第80题 require 具体实现原理是什么
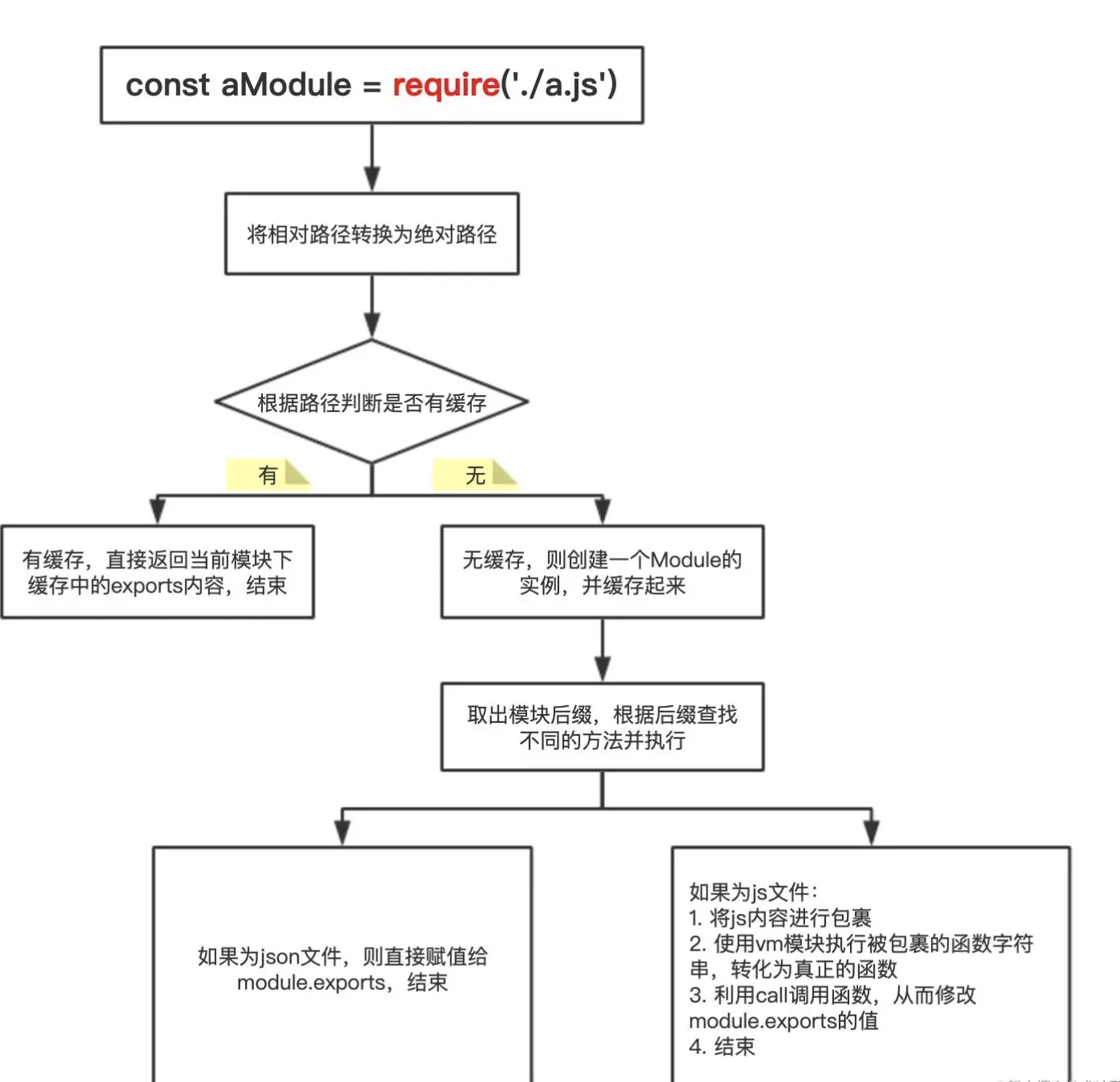
require 基本原理
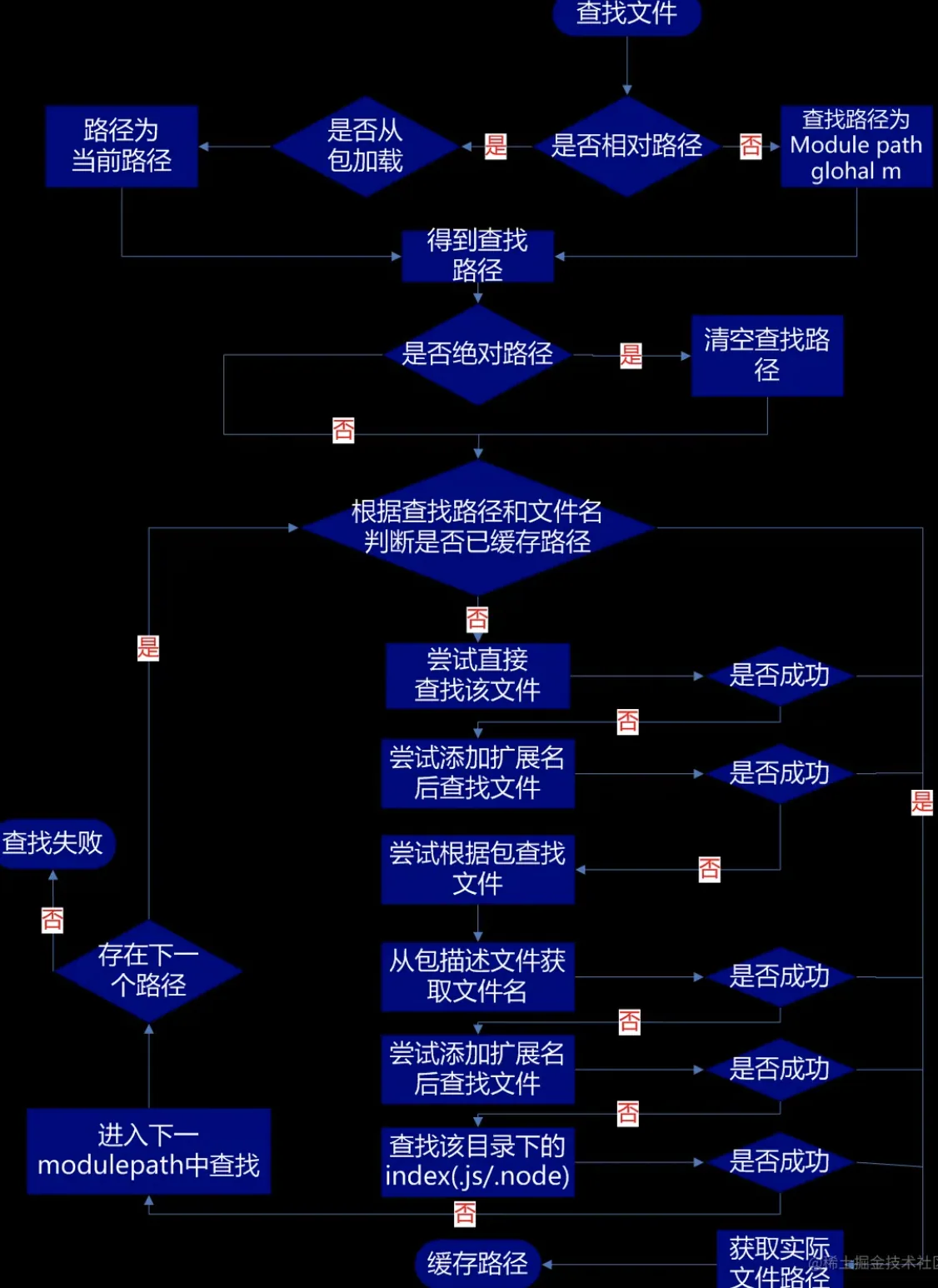
require 查找路径
require和module.exports干的事情并不复杂,我们先假设有一个全局对象{},初始情况下是空的,当你require某个文件时,就将这个文件拿出来执行,如果这个文件里面存在module.exports,当运行到这行代码时将module.exports的值加入这个对象,键为对应的文件名,最终这个对象就长这样:
{
"a.js": "hello world",
"b.js": function add(){},
"c.js": 2,
"d.js": { num: 2 }
}
当你再次
require某个文件时,如果这个对象里面有对应的值,就直接返回给你,如果没有就重复前面的步骤,执行目标文件,然后将它的module.exports加入这个全局对象,并返回给调用者。这个全局对象其实就是我们经常听说的缓存。所以require和module.exports并没有什么黑魔法,就只是运行并获取目标文件的值,然后加入缓存,用的时候拿出来用就行
手写实现一个require
const path = require('path'); // 路径操作
const fs = require('fs'); // 文件读取
const vm = require('vm'); // 文件执行
// node模块化的实现
// node中是自带模块化机制的,每个文件就是一个单独的模块,并且它遵循的是CommonJS规范,也就是使用require的方式导入模块,通过module.export的方式导出模块。
// node模块的运行机制也很简单,其实就是在每一个模块外层包裹了一层函数,有了函数的包裹就可以实现代码间的作用域隔离
// require加载模块
// require依赖node中的fs模块来加载模块文件,fs.readFile读取到的是一个字符串。
// 在javascrpt中我们可以通过eval或者new Function的方式来将一个字符串转换成js代码来运行。
// eval
// const name = 'poetry';
// const str = 'const a = 123; console.log(name)';
// eval(str); // poetry;
// new Function
// new Function接收的是一个要执行的字符串,返回的是一个新的函数,调用这个新的函数字符串就会执行了。如果这个函数需要传递参数,可以在new Function的时候依次传入参数,最后传入的是要执行的字符串。比如这里传入参数b,要执行的字符串str
// const b = 3;
// const str = 'let a = 1; return a + b';
// const fun = new Function('b', str);
// console.log(fun(b, str)); // 4
// 可以看到eval和Function实例化都可以用来执行javascript字符串,似乎他们都可以来实现require模块加载。不过在node中并没有选用他们来实现模块化,原因也很简单因为他们都有一个致命的问题,就是都容易被不属于他们的变量所影响。
// 如下str字符串中并没有定义a,但是确可以使用上面定义的a变量,这显然是不对的,在模块化机制中,str字符串应该具有自身独立的运行空间,自身不存在的变量是不可以直接使用的
// const a = 1;
// const str = 'console.log(a)';
// eval(str);
// const func = new Function(str);
// func();
// node存在一个vm虚拟环境的概念,用来运行额外的js文件,他可以保证javascript执行的独立性,不会被外部所影响
// vm 内置模块
// 虽然我们在外部定义了hello,但是str是一个独立的模块,并不在村hello变量,所以会直接报错。
// 引入vm模块, 不需要安装,node 自建模块
// const vm = require('vm');
// const hello = 'poetry';
// const str = 'console.log(hello)';
// wm.runInThisContext(str); // 报错
// 所以node执行javascript模块时可以采用vm来实现。就可以保证模块的独立性了
// 分析实现步骤
// 1.导入相关模块,创建一个Require方法。
// 2.抽离通过Module._load方法,用于加载模块。
// 3.Module.resolveFilename 根据相对路径,转换成绝对路径。
// 4.缓存模块 Module._cache,同一个模块不要重复加载,提升性能。
// 5.创建模块 id: 保存的内容是 exports = {}相当于this。
// 6.利用tryModuleLoad(module, filename) 尝试加载模块。
// 7.Module._extensions使用读取文件。
// 8.Module.wrap: 把读取到的js包裹一个函数。
// 9.将拿到的字符串使用runInThisContext运行字符串。
// 10.让字符串执行并将this改编成exports
// 定义导入类,参数为模块路径
function Require(modulePath) {
// 获取当前要加载的绝对路径
let absPathname = path.resolve(__dirname, modulePath);
// 自动给模块添加后缀名,实现省略后缀名加载模块,其实也就是如果文件没有后缀名的时候遍历一下所有的后缀名看一下文件是否存在
// 获取所有后缀名
const extNames = Object.keys(Module._extensions);
let index = 0;
// 存储原始文件路径
const oldPath = absPathname;
function findExt(absPathname) {
if (index === extNames.length) {
throw new Error('文件不存在');
}
try {
fs.accessSync(absPathname);
return absPathname;
} catch(e) {
const ext = extNames[index++];
findExt(oldPath + ext);
}
}
// 递归追加后缀名,判断文件是否存在
absPathname = findExt(absPathname);
// 从缓存中读取,如果存在,直接返回结果
if (Module._cache[absPathname]) {
return Module._cache[absPathname].exports;
}
// 创建模块,新建Module实例
const module = new Module(absPathname);
// 添加缓存
Module._cache[absPathname] = module;
// 加载当前模块
tryModuleLoad(module);
// 返回exports对象
return module.exports;
}
// Module的实现很简单,就是给模块创建一个exports对象,tryModuleLoad执行的时候将内容加入到exports中,id就是模块的绝对路径
// 定义模块, 添加文件id标识和exports属性
function Module(id) {
this.id = id;
// 读取到的文件内容会放在exports中
this.exports = {};
}
Module._cache = {};
// 我们给Module挂载静态属性wrapper,里面定义一下这个函数的字符串,wrapper是一个数组,数组的第一个元素就是函数的参数部分,其中有exports,module. Require,__dirname, __filename, 都是我们模块中常用的全局变量。注意这里传入的Require参数是我们自己定义的Require
// 第二个参数就是函数的结束部分。两部分都是字符串,使用的时候我们将他们包裹在模块的字符串外部就可以了
Module.wrapper = [
"(function(exports, module, Require, __dirname, __filename) {",
"})"
]
// _extensions用于针对不同的模块扩展名使用不同的加载方式,比如JSON和javascript加载方式肯定是不同的。JSON使用JSON.parse来运行。
// javascript使用vm.runInThisContext来运行,可以看到fs.readFileSync传入的是module.id也就是我们Module定义时候id存储的是模块的绝对路径,读取到的content是一个字符串,我们使用Module.wrapper来包裹一下就相当于在这个模块外部又包裹了一个函数,也就实现了私有作用域。
// 使用call来执行fn函数,第一个参数改变运行的this我们传入module.exports,后面的参数就是函数外面包裹参数exports, module, Require, __dirname, __filename
Module._extensions = {
'.js'(module) {
const content = fs.readFileSync(module.id, 'utf8');
const fnStr = Module.wrapper[0] + content + Module.wrapper[1];
const fn = vm.runInThisContext(fnStr);
fn.call(module.exports, module.exports, module, Require,__filename,__dirname);
},
'.json'(module) {
const json = fs.readFileSync(module.id, 'utf8');
module.exports = JSON.parse(json); // 把文件的结果放在exports属性上
}
}
// tryModuleLoad函数接收的是模块对象,通过path.extname来获取模块的后缀名,然后使用Module._extensions来加载模块
// 定义模块加载方法
function tryModuleLoad(module) {
// 获取扩展名
const extension = path.extname(module.id);
// 通过后缀加载当前模块
Module._extensions[extension](module);
}
// 至此Require加载机制我们基本就写完了,我们来重新看一下。Require加载模块的时候传入模块名称,在Require方法中使用path.resolve(__dirname, modulePath)获取到文件的绝对路径。然后通过new Module实例化的方式创建module对象,将模块的绝对路径存储在module的id属性中,在module中创建exports属性为一个json对象
// 使用tryModuleLoad方法去加载模块,tryModuleLoad中使用path.extname获取到文件的扩展名,然后根据扩展名来执行对应的模块加载机制
// 最终将加载到的模块挂载module.exports中。tryModuleLoad执行完毕之后module.exports已经存在了,直接返回就可以了
// 给模块添加缓存
// 添加缓存也比较简单,就是文件加载的时候将文件放入缓存中,再去加载模块时先看缓存中是否存在,如果存在直接使用,如果不存在再去重新,加载之后再放入缓存
// 测试
let json = Require('./test.json');
let test2 = Require('./test2.js');
console.log(json);
console.log(test2);