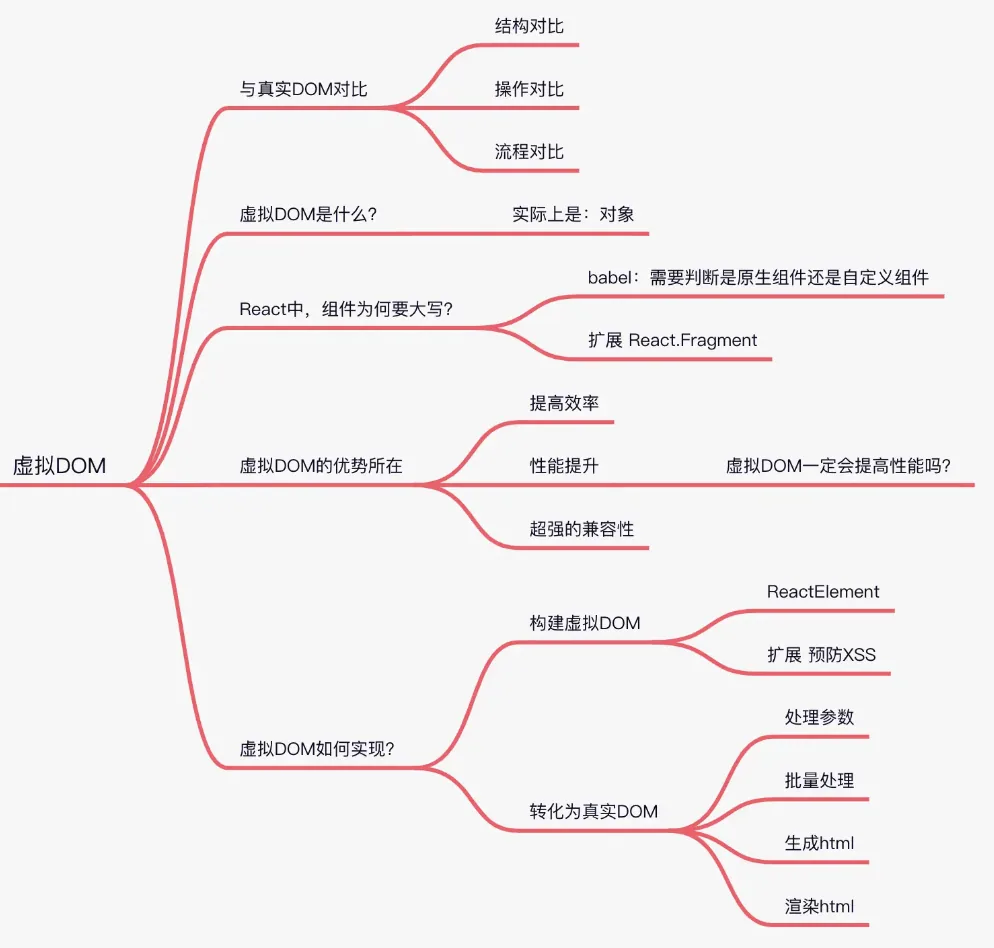
5 Diff算法相关
为什么虚拟dom会提高性能
虚拟
dom相当于在js和真实dom中间加了一个缓存,利用dom diff算法避免了没有必要的dom操作,从而提高性能
首先说说为什么要使用
Virturl DOM,因为操作真实DOM的耗费的性能代价太高,所以react内部使用js实现了一套dom结构,在每次操作在和真实dom之前,使用实现好的diff算法,对虚拟dom进行比较,递归找出有变化的dom节点,然后对其进行更新操作。为了实现虚拟DOM,我们需要把每一种节点类型抽象成对象,每一种节点类型有自己的属性,也就是prop,每次进行diff的时候,react会先比较该节点类型,假如节点类型不一样,那么react会直接删除该节点,然后直接创建新的节点插入到其中,假如节点类型一样,那么会比较prop是否有更新,假如有prop不一样,那么react会判定该节点有更新,那么重渲染该节点,然后在对其子节点进行比较,一层一层往下,直到没有子节点
具体实现步骤如下
- 用
JavaScript对象结构表示DOM树的结构;然后用这个树构建一个真正的DOM树,插到文档当中 - 当状态变更的时候,重新构造一棵新的对象树。然后用新的树和旧的树进行比较,记录两棵树差异
- 把记录的差异应用到真正的
DOM树上,视图就更新
虚拟DOM一定会提高性能吗?
很多人认为虚拟
DOM一定会提高性能,一定会更快,其实这个说法有点片面,因为虚拟DOM虽然会减少DOM操作,但也无法避免DOM操作
- 它的优势是在于
diff算法和批量处理策略,将所有的DOM操作搜集起来,一次性去改变真实的DOM,但在首次渲染上,虚拟DOM会多了一层计算,消耗一些性能,所以有可能会比html渲染的要慢 - 注意,虚拟
DOM实际上是给我们找了一条最短,最近的路径,并不是说比DOM操作的更快,而是路径最简单
react 的渲染过程中,兄弟节点之间是怎么处理的?也就是key值不一样的时候
通常我们输出节点的时候都是map一个数组然后返回一个
ReactNode,为了方便react内部进行优化,我们必须给每一个reactNode添加key,这个key prop在设计值处不是给开发者用的,而是给react用的,大概的作用就是给每一个reactNode添加一个身份标识,方便react进行识别,在重渲染过程中,如果key一样,若组件属性有所变化,则react只更新组件对应的属性;没有变化则不更新,如果key不一样,则react先销毁该组件,然后重新创建该组件
diff算法
我们知道
React会维护两个虚拟DOM,那么是如何来比较,如何来判断,做出最优的解呢?这就用到了diff算法
diff算法的作用
计算出Virtual DOM中真正变化的部分,并只针对该部分进行原生DOM操作,而非重新渲染整个页面。
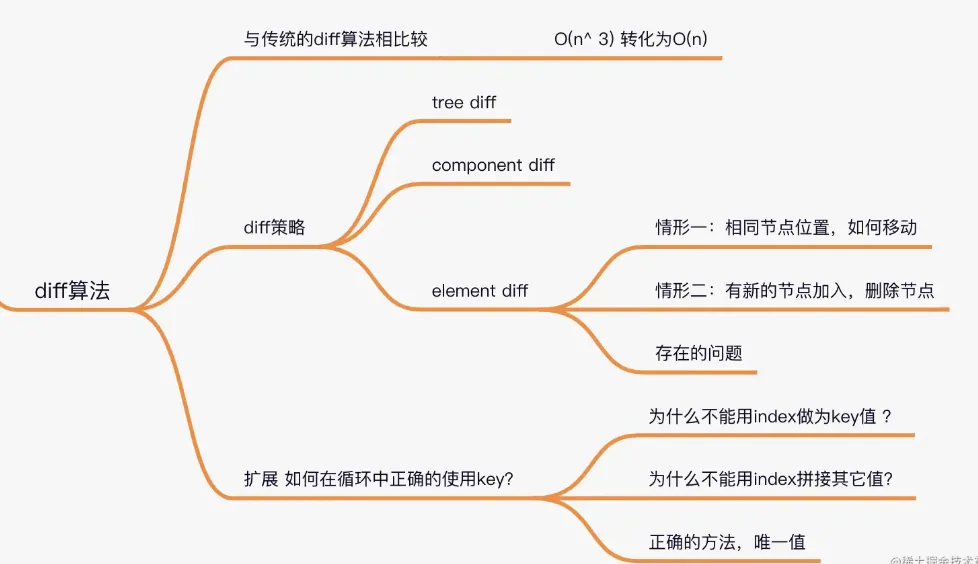
传统diff算法
通过循环递归对节点进行依次对比,算法复杂度达到
O(n^3),n是树的节点数,这个有多可怕呢?——如果要展示1000个节点,得执行上亿次比较。即便是CPU快能执行30亿条命令,也很难在一秒内计算出差异。
- 把树形结构按照层级分解,只比较同级元素。
- 给列表结构的每个单元添加唯一的
key属性,方便比较。 React只会匹配相同class的component(这里面的class指的是组件的名字)- 合并操作,调用
component的setState方法的时候,React将其标记为 -dirty.到每一个事件循环结束,React检查所有标记dirty的component重新绘制. - 开发人员可以重写
shouldComponentUpdate提高diff的性能
diff策略
React用 三大策略 将
O(n^3)杂度 转化为O(n)复杂度
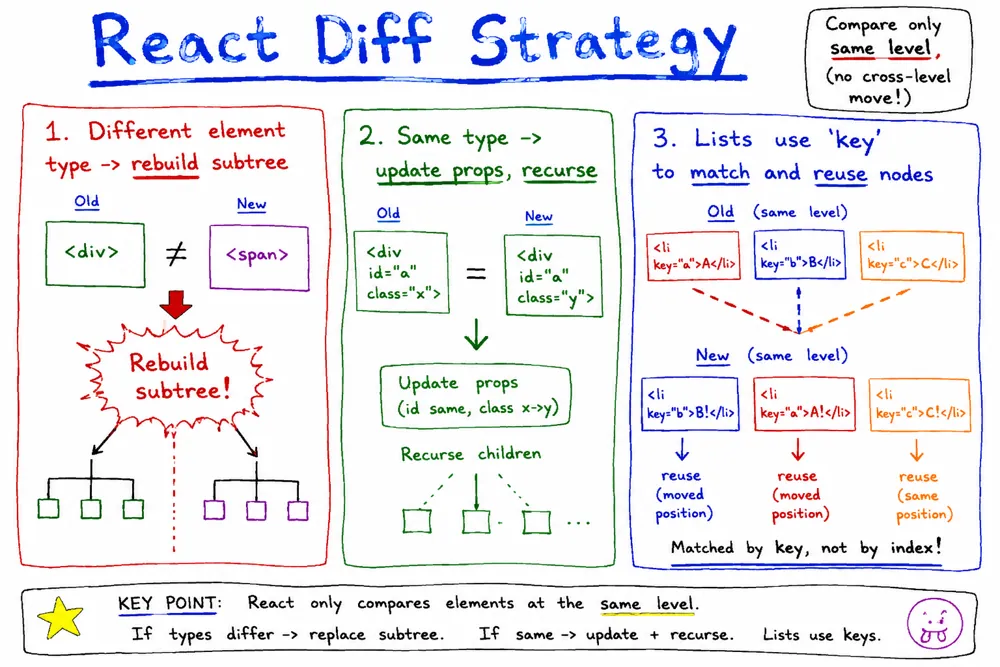
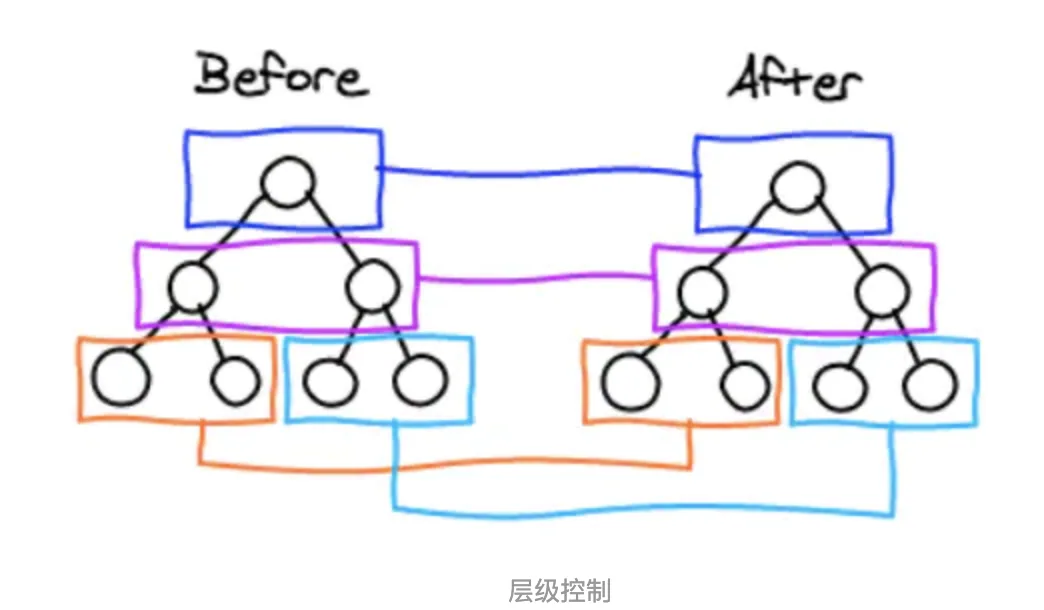
策略一(tree diff):
- Web UI中DOM节点跨层级的移动操作特别少,可以忽略不计
- 同级比较,既然DOM 节点跨层级的移动操作少到可以忽略不计,那么React通过updateDepth 对 Virtual DOM 树进行层级控制,也就是同一层,在对比的过程中,如果发现节点不在了,会完全删除不会对其他地方进行比较,这样只需要对树遍历一次就OK了
策略二(component diff):
- 拥有相同类的两个组件 生成相似的树形结构,
- 拥有不同类的两个组件 生成不同的树形结构。
策略三(element diff):
对于同一层级的一组子节点,通过唯一id区分。
tree diff
React通过updateDepth对Virtual DOM树进行层级控制。- 对树分层比较,两棵树 只对同一层次节点 进行比较。如果该节点不存在时,则该节点及其子节点会被完全删除,不会再进一步比较。
- 只需遍历一次,就能完成整棵DOM树的比较。
那么问题来了,如果DOM节点出现了跨层级操作,diff会咋办呢?
diff只简单考虑同层级的节点位置变换,如果是跨层级的话,只有创建节点和删除节点的操作。
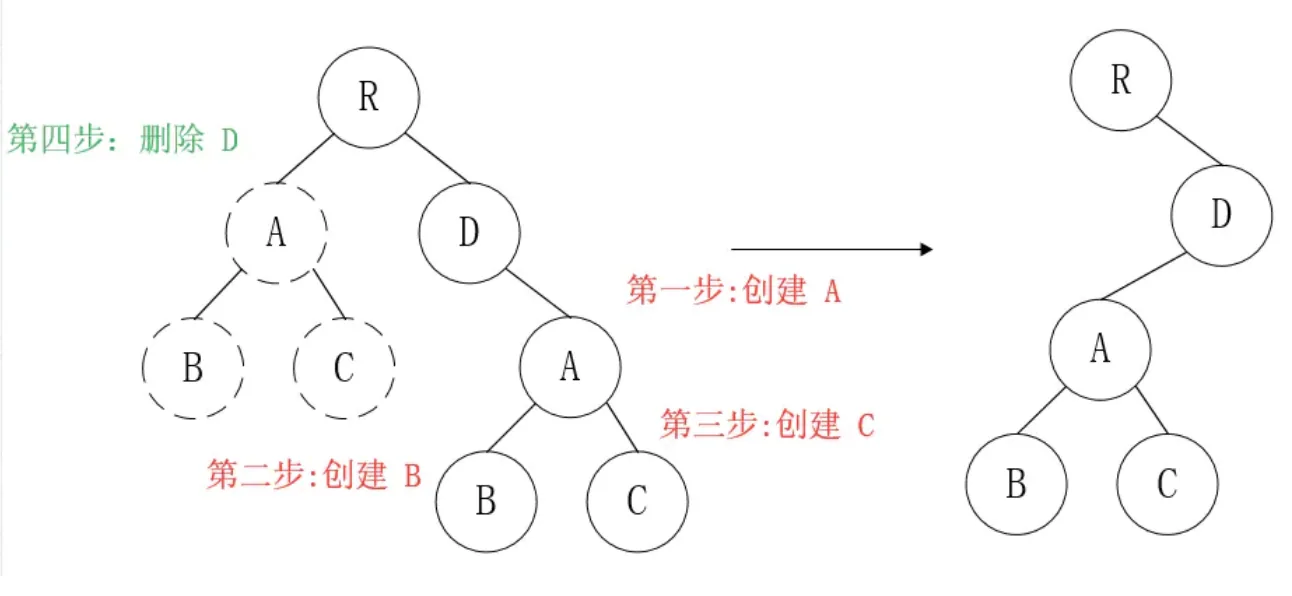
如上图所示,以A为根节点的整棵树会被重新创建,而不是移动,因此 官方建议不要进行DOM节点跨层级操作,可以通过CSS隐藏、显示节点,而不是真正地移除、添加DOM节点
component diff
React对不同的组件间的比较,有三种策略
- 同一类型的两个组件,按原策略(层级比较)继续比较
Virtual DOM树即可。 - 同一类型的两个组件,组件A变化为组件B时,可能
Virtual DOM没有任何变化,如果知道这点(变换的过程中,Virtual DOM没有改变),可节省大量计算时间,所以 用户 可以通过shouldComponentUpdate()来判断是否需要 判断计算。 - 不同类型的组件,将一个(将被改变的)组件判断为
dirty component(脏组件),从而替换 整个组件的所有节点。
注意:如果组件
D和组件G的结构相似,但是React判断是 不同类型的组件,则不会比较其结构,而是删除 组件D及其子节点,创建组件G及其子节点。
element diff
当节点处于同一层级时,
diff提供三种节点操作:删除、插入、移动。
- 插入 :组件
C不在集合(A,B)中,需要插入 - 删除 :
- 组件
D在集合(A,B,D)中,但D的节点已经更改,不能复用和更新,所以需要删除旧的D,再创建新的。 - 组件
D之前在 集合(A,B,D)中,但集合变成新的集合(A,B)了,D就需要被删除。
- 组件
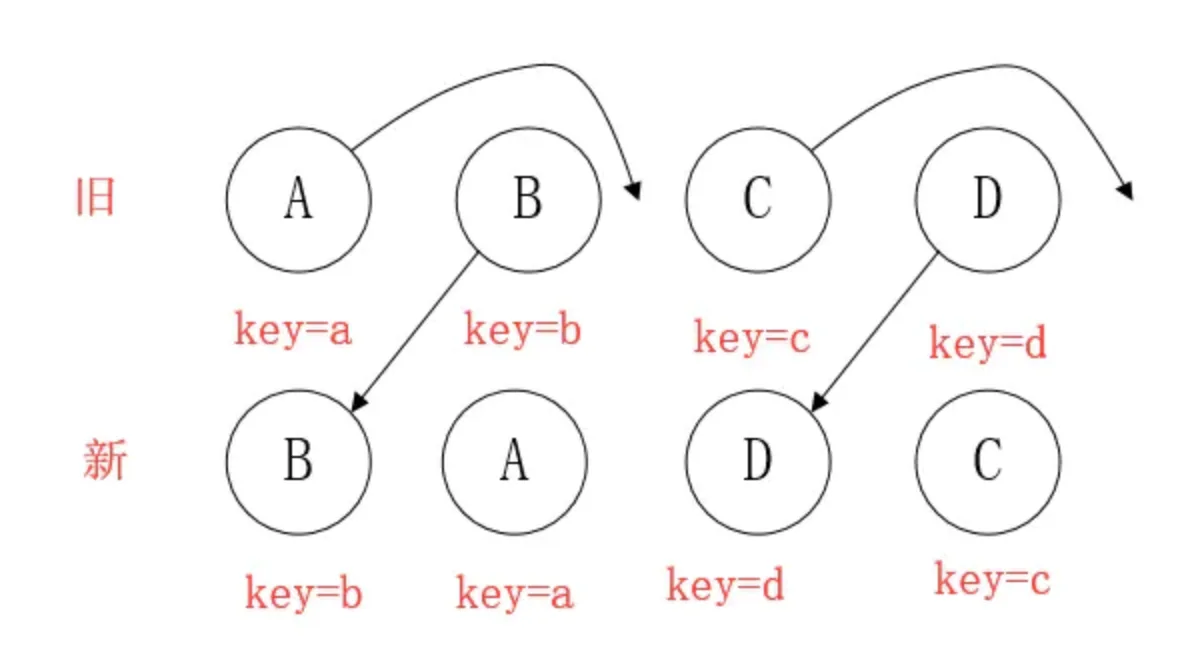
- 移动 :组件D已经在集合(
A,B,C,D)里了,且集合更新时,D没有发生更新,只是位置改变,如新集合(A,D,B,C),D在第二个,无须像传统diff,让旧集合的第二个B和新集合的第二个D比较,并且删除第二个位置的B,再在第二个位置插入D,而是 (对同一层级的同组子节点) 添加唯一key进行区分,移动即可。
diff的不足与待优化的地方
尽量减少类似将最后一个节点移动到列表首部的操作,当节点数量过大或更新操作过于频繁时,会影响React的渲染性能
Diff 的瓶颈以及 React 的应对
由于 diff 操作本身会带来性能上的损耗,在 React 文档中提到过,即使最先进的算法中,将前后两棵树完全比对的算法复杂度为O(n3),其中 n 为树中元素的数量。
如果 React 使用了该算法,那么仅仅一千个元素的页面所需要执行的计算量就是十亿的量级,这无疑是无法接受的。
为了降低算法的复杂度,React 的 diff 会预设三个限制:
- 只对同级元素进行
diff比对。如果一个元素节点在前后两次更新中跨越了层级,那么React不会尝试复用它 - 两个不同类型的元素会产生出不同的树。如果元素由
div变成p,React会销毁div及其子孙节点,并新建p及其子孙节点 - 开发者可以通过
key来暗示哪些子元素在不同的渲染下能保持稳定
React 中 key 的作用是什么
Key是React用于追踪哪些列表中元素被修改、被添加或者被移除的辅助标识- 给每一个
vnode的唯一id,可以依靠key,更准确,更快的拿到oldVnode中对应的vnode节点
<!-- 更新前 -->
<div>
<p key="a">a</p>
<h3 key="b">b</he>
</div>
<!-- 更新后 -->
<div>
<h3 key="b">b</h3>
<p key="a">a</p>
</div>
- 如果没有
key,React会认为div的第一个子节点由p变成h3,第二个子节点由h3变成p,则会销毁这两个节点并重新构造 - 但是当我们用
key指明了节点前后对应关系后,React知道key === "a"的p更新后还在,所以可以复用该节点,只需要交换顺序。 key是React用来追踪哪些列表元素被修改、被添加或者被移除的辅助标志。- 在开发过程中,我们需要保证某个元素的
key在其同级元素中具有唯一性。在React diff算法中,React会借助元素的Key值来判断该元素是新近创建的还是被移动而来的元素,从而减少不必要的元素重新渲染
关于Fiber
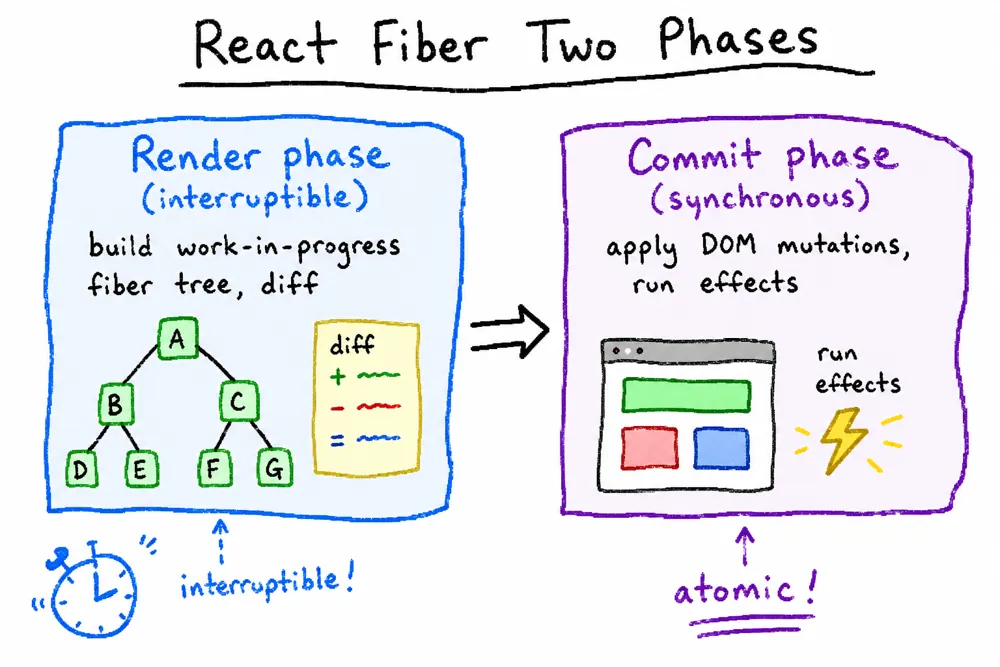
React Fiber用类似requestIdleCallback的机制来做异步diff。但是之前数据结构不支持这样的实现异步diff,于是React实现了一个类似链表的数据结构,将原来的递归diff(不可被中断) 变成了现在的遍历diff,这样就能做到异步可更新并且可以中断恢复执行
React 的核心流程可以分为两个部分:
reconciliation(调度算法,也可称为render)- 更新
state与props; - 调用生命周期钩子;
- 生成
virtual dom- 这里应该称为
Fiber Tree更为符合;
- 这里应该称为
- 通过新旧
vdom进行diff算法,获取vdom change - 确定是否需要重新渲染
- 更新
commit- 如需要,则操作
dom节点更新
- 如需要,则操作
要了解
Fiber,我们首先来看为什么需要它
- 问题 : 随着应用变得越来越庞大,整个更新渲染的过程开始变得吃力,大量的组件渲染会导致主进程长时间被占用,导致一些动画或高频操作出现卡顿和掉帧的情况。而关键点,便是 同步阻塞。在之前的调度算法中,React 需要实例化每个类组件,生成一颗组件树,使用
同步递归的方式进行遍历渲染,而这个过程最大的问题就是无法 暂停和恢复。 - 解决方案 : 解决同步阻塞的方法,通常有两种:
异步与任务分割。而React Fiber便是为了实现任务分割而诞生的 - 简述
- 在
React V16将调度算法进行了重构, 将之前的stack reconciler重构成新版的fiber reconciler,变成了具有链表和指针的 单链表树遍历算法。通过指针映射,每个单元都记录着遍历当下的上一步与下一步,从而使遍历变得可以被暂停和重启 - 这里我理解为是一种 任务分割调度算法,主要是 将原先同步更新渲染的任务分割成一个个独立的 小任务单位,根据不同的优先级,将小任务分散到浏览器的空闲时间执行,充分利用主进程的事件循环机制
- 在
- 核心
Fiber这里可以具象为一个数据结构
class Fiber {
constructor(instance) {
this.instance = instance
// 指向第一个 child 节点
this.child = child
// 指向父节点
this.return = parent
// 指向第一个兄弟节点
this.sibling = previous
}
}
- 链表树遍历算法 : 通过
节点保存与映射,便能够随时地进行停止和重启,这样便能达到实现任务分割的基本前提- 首先通过不断遍历子节点,到树末尾;
- 开始通过
sibling遍历兄弟节点; - return 返回父节点,继续执行2;
- 直到 root 节点后,跳出遍历;
- 任务分割 ,React 中的渲染更新可以分成两个阶段
- reconciliation 阶段 : vdom 的数据对比,是个适合拆分的阶段,比如对比一部分树后,先暂停执行个动画调用,待完成后再回来继续比对
- Commit 阶段 : 将 change list 更新到 dom 上,并不适合拆分,才能保持数据与 UI 的同步。否则可能由于阻塞 UI 更新,而导致数据更新和 UI 不一致的情况
- 分散执行: 任务分割后,就可以把小任务单元分散到浏览器的空闲期间去排队执行,而实现的关键是两个新API:
requestIdleCallback与requestAnimationFrame- 低优先级的任务交给
requestIdleCallback处理,这是个浏览器提供的事件循环空闲期的回调函数,需要pollyfill,而且拥有deadline参数,限制执行事件,以继续切分任务; - 高优先级的任务交给
requestAnimationFrame处理;
- 低优先级的任务交给
// 类似于这样的方式
requestIdleCallback((deadline) => {
// 当有空闲时间时,我们执行一个组件渲染;
// 把任务塞到一个个碎片时间中去;
while ((deadline.timeRemaining() > 0 || deadline.didTimeout) && nextComponent) {
nextComponent = performWork(nextComponent);
}
});
- 优先级策略: 文本框输入 > 本次调度结束需完成的任务 > 动画过渡 > 交互反馈 > 数据更新 > 不会显示但以防将来会显示的任务
Fiber其实可以算是一种编程思想,在其它语言中也有许多应用(Ruby Fiber)。- 核心思想是 任务拆分和协同,主动把执行权交给主线程,使主线程有时间空挡处理其他高优先级任务。
- 当遇到进程阻塞的问题时,任务分割、异步调用 和 缓存策略 是三个显著的解决思路。