七、React(2/2)
17 Redux实现原理解析
在 Redux 的整个工作过程中,数据流是严格单向的。这一点一定一定要背下来,面试的时候也一定一定要记得说
为什么要用redux
在
React中,数据在组件中是单向流动的,数据从一个方向父组件流向子组件(通过props),所以,两个非父子组件之间通信就相对麻烦,redux的出现就是为了解决state里面的数据问题
Redux设计理念
Redux是将整个应用状态存储到一个地方上称为store,里面保存着一个状态树store tree,组件可以派发(dispatch)行为(action)给store,而不是直接通知其他组件,组件内部通过订阅store中的状态state来刷新自己的视图
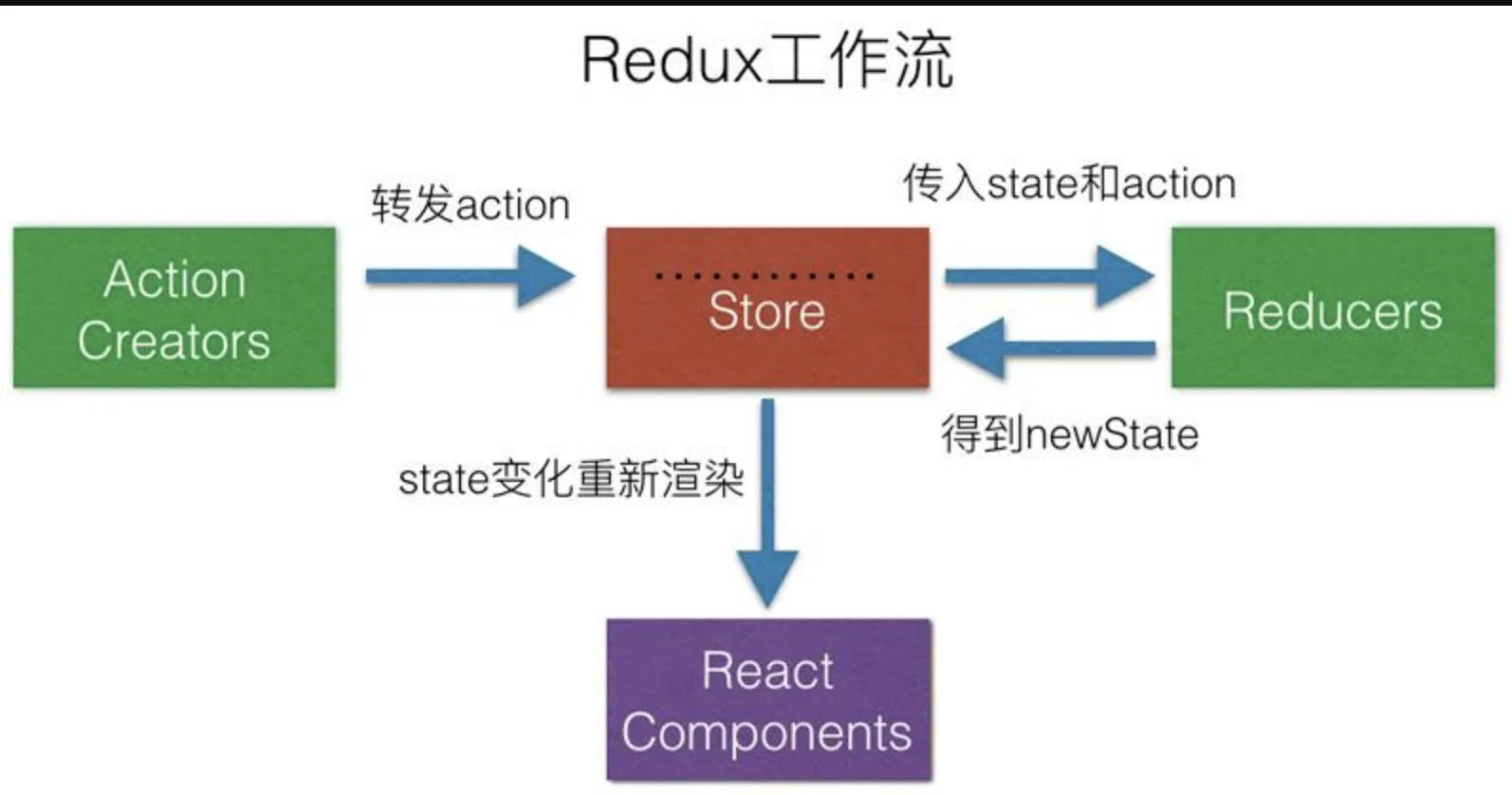
如果你想对数据进行修改,
只有一种途径:派发 action。action 会被 reducer 读取,进而根据 action 内容的不同对数据进行修改、生成新的 state(状态),这个新的 state 会更新到 store 对象里,进而驱动视图层面做出对应的改变。
Redux三大原则
- 唯一数据源
整个应用的state都被存储到一个状态树里面,并且这个状态树,只存在于唯一的store中
- 保持只读状态
state是只读的,唯一改变state的方法就是触发action,action是一个用于描述以发生时间的普通对象
- 数据改变只能通过纯函数来执行
使用纯函数来执行修改,为了描述
action如何改变state的,你需要编写reducers
从编码的角度理解 Redux 工作流
- 使用
createStore 来完成 store 对象的创建
// 引入 redux
import { createStore } from 'redux'
// 创建 store
const store = createStore(
reducer,
initial_state,
applyMiddleware(middleware1, middleware2, ...)
);
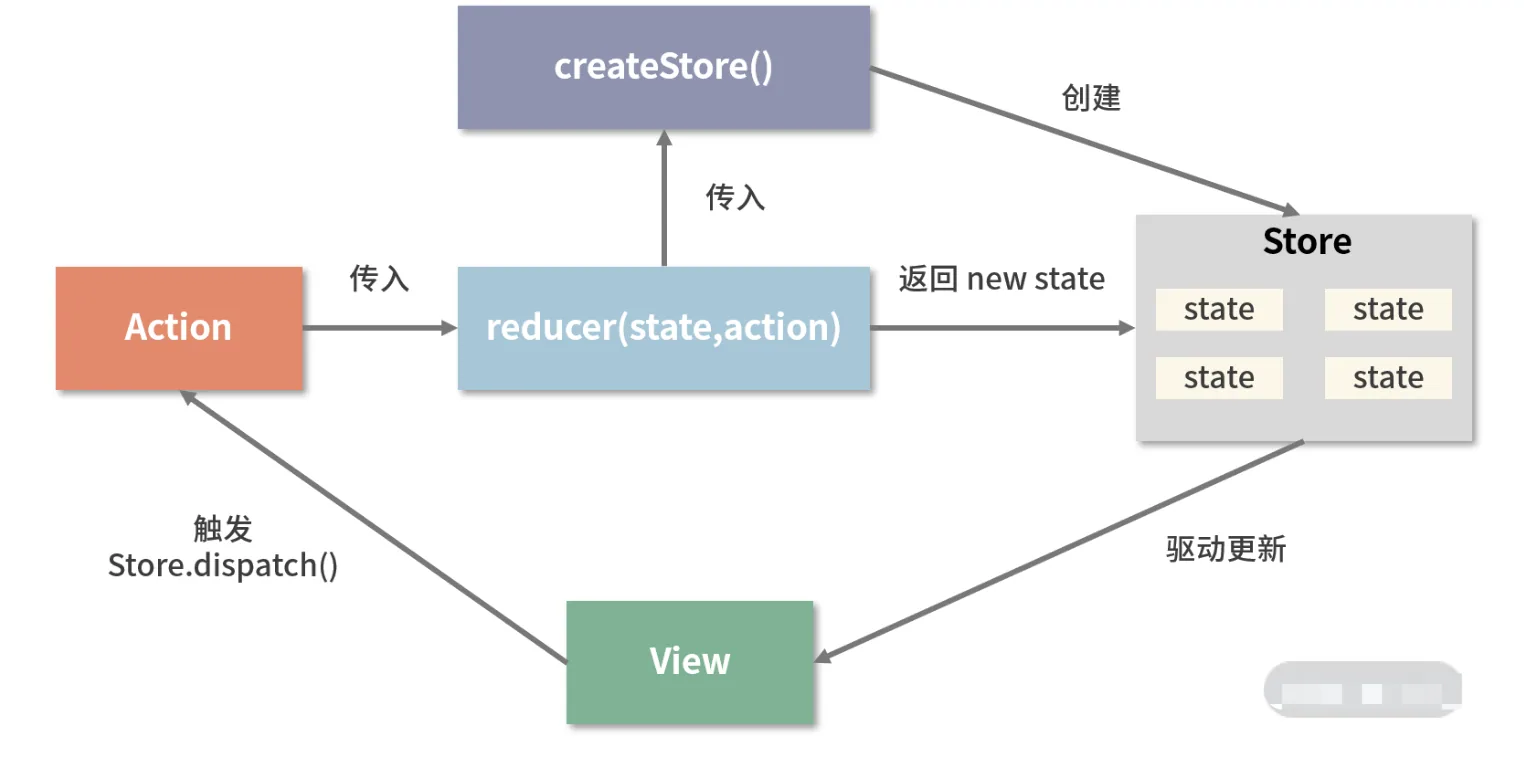
createStore 方法是一切的开始,它接收三个入参:
- reducer;
- 初始状态内容;
- 指定中间件
reducer 的作用是将新的 state 返回给 store
一个 reducer 一定是一个纯函数,它可以有各种各样的内在逻辑,但它最终一定要返回一个 state:
const reducer = (state, action) => {
// 此处是各种样的 state处理逻辑
return new_state
}
当我们基于某个 reducer 去创建 store 的时候,其实就是给这个 store 指定了一套更新规则:
// 更新规则全都写在 reducer 里
const store = createStore(reducer)
- action 的作用是通知 reducer “让改变发生”
要想让 state 发生改变,就必须用正确的 action 来驱动这个改变。
const action = {
type: "ADD_ITEM",
payload: '<li>text</li>'
}
action 对象中允许传入的属性有多个,但只有 type 是必传的。type 是 action 的唯一标识,reducer 正是通过不同的 type 来识别出需要更新的不同的 state,由此才能够实现精准的“定向更新”。
- 派发 action,靠的是 dispatch
action 本身只是一个对象,要想让 reducer 感知到 action,还需要“派发 action”这个动作,这个动作是由 store.dispatch 完成的。这里我简单地示范一下:
import { createStore } from 'redux'
// 创建 reducer
const reducer = (state, action) => {
// 此处是各种样的 state处理逻辑
return new_state
}
// 基于 reducer 创建 state
const store = createStore(reducer)
// 创建一个 action,这个 action 用 “ADD_ITEM” 来标识
const action = {
type: "ADD_ITEM",
payload: '<li>text</li>'
}
// 使用 dispatch 派发 action,action 会进入到 reducer 里触发对应的更新
store.dispatch(action)
以上这段代码,是从编码角度对 Redux 主要工作流的概括,这里我同样为你总结了一张对应的流程图:
Redux源码
let createStore = (reducer) => {
let state;
//获取状态对象
//存放所有的监听函数
let listeners = [];
let getState = () => state;
//提供一个方法供外部调用派发action
let dispath = (action) => {
//调用管理员reducer得到新的state
state = reducer(state, action);
//执行所有的监听函数
listeners.forEach((l) => l())
}
//订阅状态变化事件,当状态改变发生之后执行监听函数
let subscribe = (listener) => {
listeners.push(listener);
}
dispath();
return {
getState,
dispath,
subscribe
}
}
let combineReducers=(renducers)=>{
//传入一个renducers管理组,返回的是一个renducer
return function(state={},action={}){
let newState={};
for(var attr in renducers){
newState[attr]=renducers[attr](state[attr],action)
}
return newState;
}
}
export {createStore,combineReducers};
聊聊 Redux 和 Vuex 的设计思想
- 共同点
首先两者都是处理全局状态的工具库,大致实现思想都是:全局
state保存状态---->dispatch(action)------>reducer(vuex里的mutation)----> 生成newState; 整个状态为同步操作;
- 区别
最大的区别在于处理异步的不同,vuex里面多了一步
commit操作,在action之后commit(mutation)之前处理异步,而redux里面则是通过中间件处理
redux 中间件
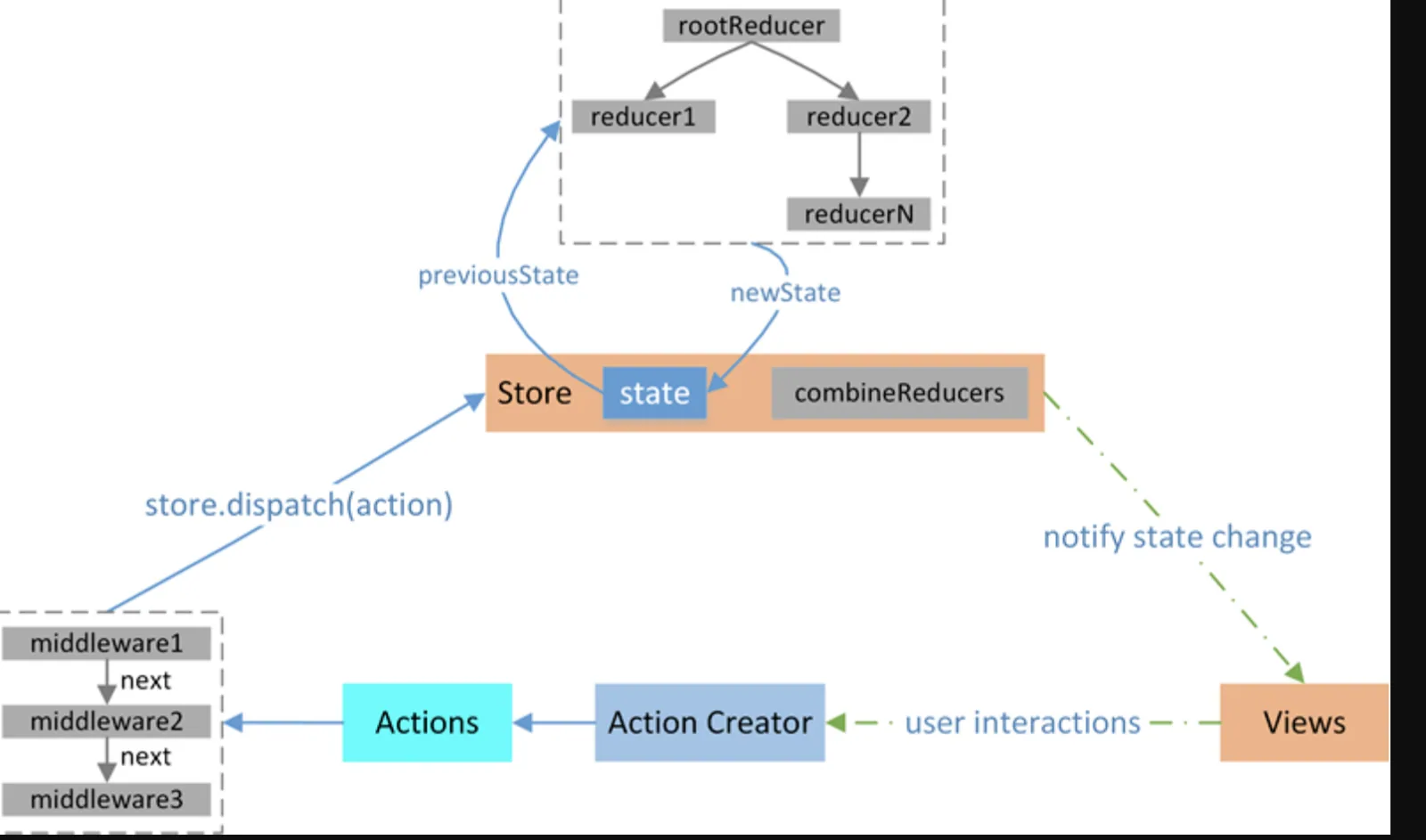
中间件提供第三方插件的模式,自定义拦截 action -> reducer 的过程。变为 action -> middlewares -> reducer 。这种机制可以让我们改变数据流,实现如异步 action ,action 过 滤,日志输出,异常报告等功能
常见的中间件:
redux-logger:提供日志输出;redux-thunk:处理异步操作;redux-promise: 处理异步操作;actionCreator的返回值是promise
redux中间件的原理是什么
applyMiddleware
为什么会出现中间件?
- 它只是一个用来加工dispatch的工厂,而要加工什么样的dispatch出来,则需要我们传入对应的中间件函数
- 让每一个中间件函数,接收一个dispatch,然后返回一个改造后的dispatch,来作为下一个中间件函数的next,以此类推。
function applyMiddleware(middlewares) {
middlewares = middlewares.slice()
middlewares.reverse()
let dispatch = store.dispatch
middlewares.forEach(middleware =>
dispatch = middleware(store)(dispatch)
)
return Object.assign({}, store, { dispatch })
}
上面的
middleware(store)(dispatch)就相当于是const logger = store => next => {},这就是构造后的dispatch,继续向下传递。这里middlewares.reverse(),进行数组反转的原因,是最后构造的dispatch,实际上是最先执行的。因为在applyMiddleware串联的时候,每个中间件只是返回一个新的dispatch函数给下一个中间件,实际上这个dispatch并不会执行。只有当我们在程序中通过store.dispatch(action),真正派发的时候,才会执行。而此时的dispatch是最后一个中间件返回的包装函数。然后依次向前递推执行。
[浅析中间件 (opens new window)](http://interview.poetries.top/principle- docs/react/08-%E6%B5%85%E6%9E%90%E4%B8%AD%E9%97%B4%E4%BB%B6.html)
action、store、reducer分析
redux的核心概念就是store、action、reducer,从调用关系来看如下所示
store.dispatch(action) --> reducer(state, action) --> final state
// reducer方法, 传入的参数有两个
// state: 当前的state
// action: 当前触发的行为, {type: 'xx'}
// 返回值: 新的state
var reducer = function(state, action){
switch (action.type) {
case 'add_todo':
return state.concat(action.text);
default:
return state;
}
};
// 创建store, 传入两个参数
// 参数1: reducer 用来修改state
// 参数2(可选): [], 默认的state值,如果不传, 则为undefined
var store = redux.createStore(reducer, []);
// 通过 store.getState() 可以获取当前store的状态(state)
// 默认的值是 createStore 传入的第二个参数
console.log('state is: ' + store.getState()); // state is:
// 通过 store.dispatch(action) 来达到修改 state 的目的
// 注意: 在redux里,唯一能够修改state的方法,就是通过 store.dispatch(action)
store.dispatch({type: 'add_todo', text: '读书'});
// 打印出修改后的state
console.log('state is: ' + store.getState()); // state is: 读书
store.dispatch({type: 'add_todo', text: '写作'});
console.log('state is: ' + store.getState()); // state is: 读书,写作
- store、reducer、action关联
store
store在这里代表的是数据模型,内部维护了一个state变量store有两个核心方法,分别是getState、dispatch。前者用来获取store的状态(state),后者用来修改store的状态
// 创建store, 传入两个参数
// 参数1: reducer 用来修改state
// 参数2(可选): [], 默认的state值,如果不传, 则为undefined
var store = redux.createStore(reducer, []);
// 通过 store.getState() 可以获取当前store的状态(state)
// 默认的值是 createStore 传入的第二个参数
console.log('state is: ' + store.getState()); // state is:
// 通过 store.dispatch(action) 来达到修改 state 的目的
// 注意: 在redux里,唯一能够修改state的方法,就是通过 store.dispatch(action)
store.dispatch({type: 'add_todo', text: '读书'});
action
- 对行为(如用户行为)的抽象,在
redux里是一个普通的js对象 action必须有一个type字段来标识这个行为的类型
{type:'add_todo', text:'读书'}
{type:'add_todo', text:'写作'}
{type:'add_todo', text:'睡觉', time:'晚上'}
reducer
- 一个普通的函数,用来修改
store的状态。传入两个参数state、action - 其中,
state为当前的状态(可通过store.getState()获得),而action为当前触发的行为(通过store.dispatch(action)调用触发) reducer(state, action)返回的值,就是store最新的state值
// reducer方法, 传入的参数有两个
// state: 当前的state
// action: 当前触发的行为, {type: 'xx'}
// 返回值: 新的state
var reducer = function(state, action){
switch (action.type) {
case 'add_todo':
return state.concat(action.text);
default:
return state;
}
};
- 关于
actionCreator
actionCreator(args) => action
var addTodo = function(text){
return {
type: 'add_todo',
text: text
};
};
addTodo('睡觉'); // 返回:{type: 'add_todo', text: '睡觉'}
异步Action及操作
- 创建同步Action
Action是数据从应用传递到store/state的载体,也是开启一次完成数据流的开始
普通的action对象
const action = {
type:'ADD_TODO',
name:'poetries'
}
dispatch(action)
封装action creator
function actionCreator(data){
return {
type:'ADD_TODO',
data:data
}
}
dispatch(actionCreator('poetries'))
bindActionCreators合并
function a(name,id){
reurn {
type:'a',
name,
id
}
}
function b(name,id){
reurn {
type:'b',
name,
id
}
}
let actions = Redux.bindActionCreators({a,b},store.dispatch)
//调用
actions.a('poetries','id001')
actions.b('jing','id002')
action创建的标准
在Flux的架构中,一个Action要符合 FSA(Flux Standard Action) 规范,需要满足如下条件
- 是一个纯文本对象
- 只具备
type、payload、error和meta中的一个或者多个属性。type字段不可缺省,其它字段可缺省 - 若
Action报错,error字段不可缺省,切必须为true
payload是一个对象,用作Action携带数据的载体
标准action示例
- A basic Flux Standard Action:
{
type: 'ADD_TODO',
payload: {
text: 'Do something.'
}
}
- An FSA that represents an error, analogous to a rejected Promise
{
type: 'ADD_TODO',
payload: new Error(),
error: true
}
https://github.com/acdlite/flux-standard-action
- 可以采用如下一个简单的方式检验一个
Action是否符合FSA标准
// every有一个匹配不到返回false
let isFSA = Object.keys(action).every((item)=>{
return ['payload','type','error','meta'].indexOf(item) > -1
})
- 创建异步action的多种方式
最简单的方式就是使用同步的方式来异步,将原来同步时一个
action拆分成多个异步的action的,在异步开始前、异步请求中、异步正常返回(异常)操作分别使用同步的操作,从而模拟出一个异步操作了。这样的方式是比较麻烦的,现在已经有redux- saga等插件来解决这些问题了
异步action的实现方式一:setTimeout
redux-thunk中间处理解析
function thunkAction(data) {
reutrn (dispatch)=>{
setTimeout(function(){
dispatch({
type:'ADD_TODO',
data
})
},3000)
}
}
异步action的实现方式二:promise实现异步action
redux-promise中间处理这种action
function promiseAction(name){
return new Promise((resolve,reject) => {
setTimeout((param)=>{
resolve({
type:'ADD_TODO',
name
})
},3000)
}).then((param)=>{
dispatch(action("action2"))
return;
}).then((param)=>{
dispatch(action("action3"))
})
}
- redux异步流程
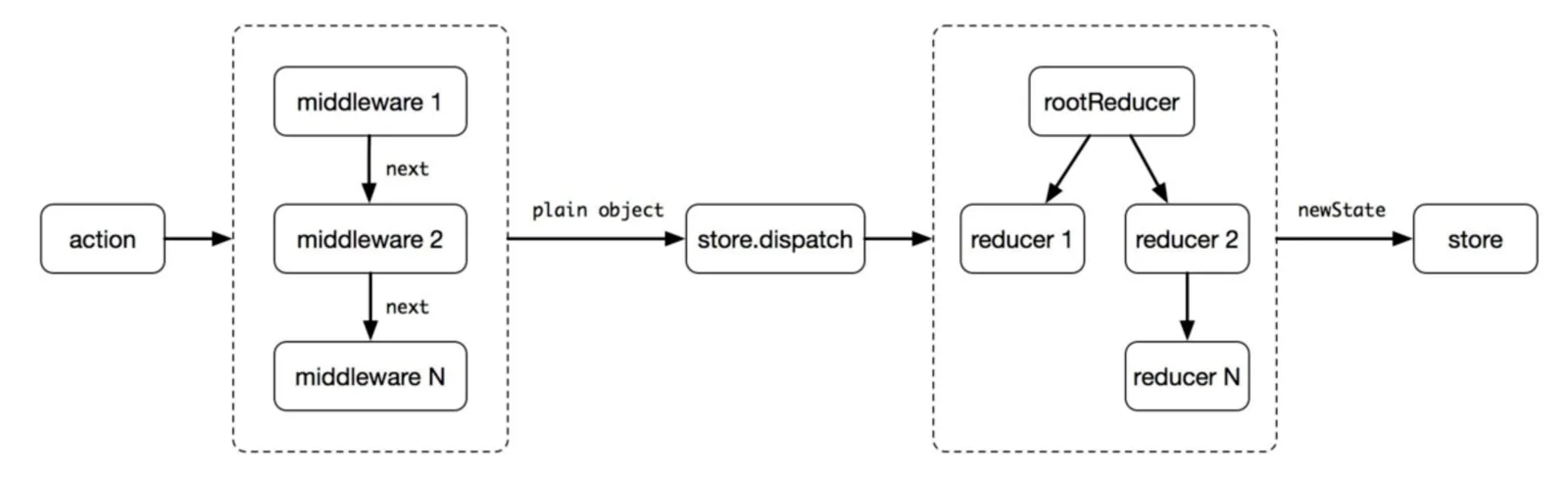
- 首先发起一个action,然后通过中间件,这里为什么要用中间件呢,因为这样
dispatch的返回值才能是一个函数。 - 通过
store.dispatch,将状态的的改变传给store的小弟reducer,reducer根据action的改变,传递新的状态state。 - 最后将所有的改变告诉给它的大哥,
store。store保存着所有的数据,并将数据注入到组件的顶部,这样组件就可以获得它需要的数据了
- Redux异步方案选型
redux-thunk
Redux本身只能处理同步的Action,但可以通过中间件来拦截处理其它类型的action,比如函数(Thunk),再用回调触发普通Action,从而实现异步处理
- 发送异步的
action其实是被中间件捕获的,函数类型的action就被middleware捕获。至于怎么定义异步的action要看你用哪个中间件,根据他们的实例来定义,这样才会正确解析action
Redux本身不处理异步行为,需要依赖中间件。结合redux-actions使用,Redux有两个推荐的异步中间件
redux-thunkredux-promise
redux-thunk的源码如下
function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
thunk.withExtraArgument = createThunkMiddleware;
export default thunk;
源码可知,
action creator需要返回一个函数给redux-thunk进行调用,示例如下
export let addTodoWithThunk = (val) => async (dispatch, getState)=>{
//请求之前的一些处理
let value = await Promise.resolve(val + ' thunk');
dispatch({
type:CONSTANT.ADD_TO_DO_THUNK,
payload:{
value
}
});
};
- 而它使用起来最大的问题,就是重复的模板代码太多
//action types
const GET_DATA = 'GET_DATA',
GET_DATA_SUCCESS = 'GET_DATA_SUCCESS',
GET_DATA_FAILED = 'GET_DATA_FAILED';
//action creator
const getDataAction = (id) => (dispatch, getState) => {
dispatch({
type: GET_DATA,
payload: id
})
api.getData(id) //注:本文所有示例的api.getData都返回promise对象
.then(response => {
dispatch({
type: GET_DATA_SUCCESS,
payload: response
})
})
.catch(error => {
dispatch({
type: GET_DATA_FAILED,
payload: error
})
})
}
}
//reducer
const reducer = (oldState, action) => {
switch(action.type) {
case GET_DATA :
return oldState;
case GET_DATA_SUCCESS :
return successState;
case GET_DATA_FAILED :
return errorState;
}
}
这已经是最简单的场景了,请注意:我们甚至还没写一行业务逻辑,如果每个异步处理都像这样,重复且无意义的工作会变成明显的阻碍
- 另一方面,像
GET_DATA_SUCCESS、GET_DATA_FAILED这样的字符串声明也非常无趣且易错 上例中,GET_DATA这个action并不是多数场景需要的
redux-promise
由于
redux-thunk写起来实在是太麻烦了,社区当然会有其它轮子出现。redux-promise则是其中比较知名的
- 它自定义了一个
middleware,当检测到有action的payload属性是Promise对象时,就会- 若
resolve,触发一个此action的拷贝,但payload为promise的value,并设status属性为"success" - 若
reject,触发一个此action的拷贝,但payload为promise的reason,并设status属性为"error"
- 若
//action types
const GET_DATA = 'GET_DATA';
//action creator
const getData = function(id) {
return {
type: GET_DATA,
payload: api.getData(id) //payload为promise对象
}
}
//reducer
function reducer(oldState, action) {
switch(action.type) {
case GET_DATA:
if (action.status === 'success') {
return successState
} else {
return errorState
}
}
}
redux-promise为了精简而做出的妥协非常明显:无法处理乐观更新
场景解析之:乐观更新
多数异步场景都是悲观更新的,即等到请求成功才渲染数据。而与之相对的乐观更新,则是不等待请求成功,在发送请求的同时立即渲染数据
- 由于乐观更新发生在用户操作时,要处理它,意味着必须有action表示用户的初始动作
- 在上面
redux-thunk的例子中,我们看到了GET_DATA,GET_DATA_SUCCESS、GET_DATA_FAILED三个action,分别表示初始动作、异步成功和异步失败,其中第一个action使得redux-thunk具备乐观更新的能力 - 而在
redux-promise中,最初触发的action被中间件拦截然后过滤掉了。原因很简单,redux认可的action对象是plain JavaScript objects,即简单对象,而在redux-promise中,初始action的payload是个Promise
redux-promise-middleware
redux-promise-middleware相比redux-promise,采取了更为温和和渐进式的思路,保留了和redux- thunk类似的三个action
//action types
const GET_DATA = 'GET_DATA',
GET_DATA_PENDING = 'GET_DATA_PENDING',
GET_DATA_FULFILLED = 'GET_DATA_FULFILLED',
GET_DATA_REJECTED = 'GET_DATA_REJECTED';
//action creator
const getData = function(id) {
return {
type: GET_DATA,
payload: {
promise: api.getData(id),
data: id
}
}
}
//reducer
const reducer = function(oldState, action) {
switch(action.type) {
case GET_DATA_PENDING :
return oldState; // 可通过action.payload.data获取id
case GET_DATA_FULFILLED :
return successState;
case GET_DATA_REJECTED :
return errorState;
}
}
- redux异步操作代码演示
- 根据官网的async例子分析 https://github.com/lewis617/react-redux-tutorial/tree/master/redux-examples/async
action/index.js
import fetch from 'isomorphic-fetch'
export const RECEIVE_POSTS = 'RECEIVE_POSTS'
//获取新闻成功的action
function receivePosts(reddit, json) {
return {
type: RECEIVE_POSTS,
reddit: reddit,
posts: json.data.children.map(child =>child.data)
}
}
function fetchPosts(subreddit) {
return function (dispatch) {
return fetch(`http://www.subreddit.com/r/${subreddit}.json`)
.then(response => response.json())
.then(json =>
dispatch(receivePosts(subreddit, json))
)
}
}
//如果需要则开始获取文章
export function fetchPostsIfNeeded(subreddit) {
return (dispatch, getState) => {
return dispatch(fetchPosts(subreddit))
}
}
fetchPostsIfNeeded这里就是一个中间件。redux- thunk会拦截fetchPostsIfNeeded这个action,会先发起数据请求,如果成功,就将数据传给action从而到达reducer那里
reducers/index.js
import { combineReducers } from 'redux'
import {
RECEIVE_POSTS
} from '../actions'
function posts(state = {
items: []
}, action) {
switch (action.type) {
case RECEIVE_POSTS:
// Object.assign是ES6的一个语法。合并对象,将对象合并为一个,前后相同的话,后者覆盖强者。详情可以看这里
// https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/assign
return Object.assign({}, state, {
items: action.posts //数据都存在了这里
})
default:
return state
}
}
// 将所有的reducer结合为一个,传给store
const rootReducer = combineReducers({
postsByReddit
})
export default rootReducer
这个跟正常的
reducer差不多。判断action的类型,从而根据action的不同类型,返回不同的数据。这里将数据存储在了items这里。这里的reducer只有一个。最后结合成rootReducer,传给store
store/configureStore.js
import { createStore, applyMiddleware } from 'redux'
import thunkMiddleware from 'redux-thunk'
import createLogger from 'redux-logger'
import rootReducer from '../reducers'
const createStoreWithMiddleware = applyMiddleware(
thunkMiddleware,
createLogger()
)(createStore)
export default function configureStore(initialState) {
const store = createStoreWithMiddleware(rootReducer, initialState)
if (module.hot) {
// Enable Webpack hot module replacement for reducers
module.hot.accept('../reducers', () => {
const nextRootReducer = require('../reducers')
store.replaceReducer(nextRootReducer)
})
}
return store
}
- 我们是如何在
dispatch机制中引入Redux Thunk middleware的呢? 我们使用了applyMiddleware() - 通过使用指定的
middleware,action creator除了返回action对象外还可以返回函数 - 这时,这个
action creator就成为了thunk
界面上的调用:在containers/App.js
//初始化渲染后触发
componentDidMount() {
const { dispatch} = this.props
// 这里可以传两个值,一个是 reactjs 一个是 frontend
dispatch(fetchPostsIfNeeded('frontend'))
}
改变状态的时候也是需要通过
dispatch来传递的
- 数据的获取是通过
provider,将store里面的数据注入给组件。让顶级组件提供给他们的子孙组件调用。代码如下:
import 'babel-core/polyfill'
import React from 'react'
import { render } from 'react-dom'
import { Provider } from 'react-redux'
import App from './containers/App'
import configureStore from './store/configureStore'
const store = configureStore()
render(
<Provider store={store}>
<App />
</Provider>,
document.getElementById('root')
)
这样就完成了
redux的异步操作。其实最主要的区别还是action里面还有中间件的调用,其他的地方基本跟同步的redux差不多的。搞懂了中间件,就基本搞懂了redux的异步操作
18 谈谈你对状态管理的理解
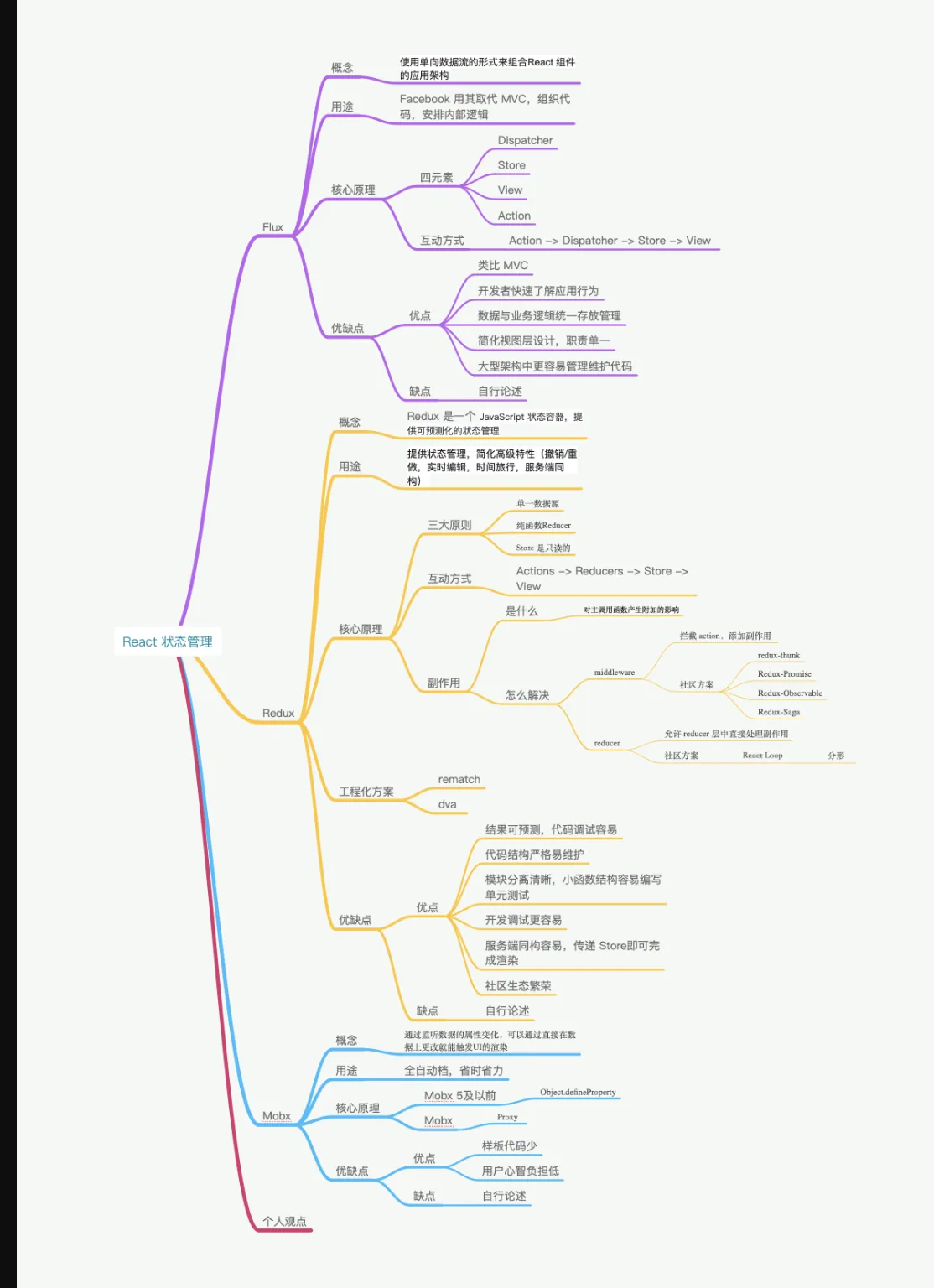
- 首先介绍 Flux,Flux 是一种使用单向数据流的形式来组合 React 组件的应用架构。
- Flux 包含了 4 个部分,分别是
Dispatcher、Store、View、Action。Store存储了视图层所有的数据,当Store变化后会引起 View 层的更新。如果在视图层触发一个Action,就会使当前的页面数据值发生变化。Action 会被 Dispatcher 进行统一的收发处理,传递给 Store 层,Store 层已经注册过相关 Action 的处理逻辑,处理对应的内部状态变化后,触发 View 层更新。 Flux 的优点是单向数据流,解决了 MVC 中数据流向不清的问题,使开发者可以快速了解应用行为。从项目结构上简化了视图层设计,明确了分工,数据与业务逻辑也统一存放管理,使在大型架构的项目中更容易管理、维护代码。其次是 Redux,Redux 本身是一个 JavaScript 状态容器,提供可预测化状态的管理。社区通常认为 Redux 是 Flux 的一个简化设计版本,它提供的状态管理,简化了一些高级特性的实现成本,比如撤销、重做、实时编辑、时间旅行、服务端同构等。- Redux 的核心设计包含了三大原则:
单一数据源、纯函数 Reducer、State 是只读的。 - Redux 中整个数据流的方案与 Flux 大同小异
- Redux 中的另一大核心点是处理“副作用”,AJAX 请求等异步工作,或不是纯函数产生的第三方的交互都被认为是 “副作用”。这就造成在纯函数设计的 Redux 中,处理副作用变成了一件至关重要的事情。社区通常有两种解决方案:
- 第一类是在
Dispatch的时候会有一个middleware 中间件层,拦截分发的Action 并添加额外的复杂行为,还可以添加副作用。第一类方案的流行框架有Redux-thunk、Redux-Promise、Redux-Observable、Redux-Saga等。 - 第二类是允许
Reducer层中直接处理副作用,采取该方案的有React Loop,React Loop在实现中采用了 Elm 中分形的思想,使代码具备更强的组合能力。 - 除此以外,社区还提供了更为工程化的方案,比如
rematch 或 dva,提供了更详细的模块架构能力,提供了拓展插件以支持更多功能。
- 第一类是在
- Redux 的优点很多:
- 结果可预测;
- 代码结构严格易维护;
- 模块分离清晰且小函数结构容易编写单元测试;
Action触发的方式,可以在调试器中使用时间回溯,定位问题更简单快捷;- 单一数据源使服务端同构变得更为容易;社区方案多,生态也更为繁荣。
最后是 Mobx,Mobx 通过监听数据的属性变化,可以直接在数据上更改触发UI 的渲染。在使用上更接近 Vue,比起Flux 与 Redux的手动挡的体验,更像开自动挡的汽车。Mobx 的响应式实现原理与 Vue 相同,以Mobx 5为分界点,5 以前采用Object.defineProperty的方案,5 及以后使用Proxy的方案。它的优点是样板代码少、简单粗暴、用户学习快、响应式自动更新数据让开发者的心智负担更低。- Mobx 在开发项目时简单快速,但应用 Mobx 的场景 ,其实完全可以用 Vue 取代。如果纯用 Vue,体积还会更小巧
19 connect组件原理分析
1. connect用法
作用:连接
React组件与Redux store
connect([mapStateToProps], [mapDispatchToProps], [mergeProps],[options])
// 这个函数允许我们将 store 中的数据作为 props 绑定到组件上
const mapStateToProps = (state) => {
return {
count: state.count
}
}
- 这个函数的第一个参数就是
Redux的store,我们从中摘取了count属性。你不必将state中的数据原封不动地传入组件,可以根据state中的数据,动态地输出组件需要的(最小)属性 - 函数的第二个参数
ownProps,是组件自己的props
当
state变化,或者ownProps变化的时候,mapStateToProps都会被调用,计算出一个新的stateProps,(在与ownProps merge后)更新给组件
mapDispatchToProps(dispatch, ownProps): dispatchProps
connect的第二个参数是mapDispatchToProps,它的功能是,将action作为props绑定到组件上,也会成为MyComp的 `props
2. 原理解析
首先
connect之所以会成功,是因为Provider组件
- 在原应用组件上包裹一层,使原来整个应用成为
Provider的子组件 - 接收
Redux的store作为props,通过context对象传递给子孙组件上的connect
connect做了些什么
它真正连接
Redux和React,它包在我们的容器组件的外一层,它接收上面Provider提供的store里面的state和dispatch,传给一个构造函数,返回一个对象,以属性形式传给我们的容器组件
3. 源码
connect是一个高阶函数,首先传入mapStateToProps、mapDispatchToProps,然后返回一个生产Component的函数(wrapWithConnect),然后再将真正的Component作为参数传入wrapWithConnect,这样就生产出一个经过包裹的Connect组件,该组件具有如下特点
- 通过
props.store获取祖先Component的store props包括stateProps、dispatchProps、parentProps,合并在一起得到nextState,作为props传给真正的Component componentDidMount时,添加事件this.store.subscribe(this.handleChange),实现页面交互shouldComponentUpdate时判断是否有避免进行渲染,提升页面性能,并得到nextStatecomponentWillUnmount时移除注册的事件this.handleChange
// 主要逻辑
export default function connect(mapStateToProps, mapDispatchToProps, mergeProps, options = {}) {
return function wrapWithConnect(WrappedComponent) {
class Connect extends Component {
constructor(props, context) {
// 从祖先Component处获得store
this.store = props.store || context.store
this.stateProps = computeStateProps(this.store, props)
this.dispatchProps = computeDispatchProps(this.store, props)
this.state = { storeState: null }
// 对stateProps、dispatchProps、parentProps进行合并
this.updateState()
}
shouldComponentUpdate(nextProps, nextState) {
// 进行判断,当数据发生改变时,Component重新渲染
if (propsChanged || mapStateProducedChange || dispatchPropsChanged) {
this.updateState(nextProps)
return true
}
}
componentDidMount() {
// 改变Component的state
this.store.subscribe(() = {
this.setState({
storeState: this.store.getState()
})
})
}
render() {
// 生成包裹组件Connect
return (
<WrappedComponent {...this.nextState} />
)
}
}
Connect.contextTypes = {
store: storeShape
}
return Connect;
}
}
20 React Hooks
- 代码逻辑聚合,逻辑复用
- HOC嵌套地狱
- 代替class
React 中通常使用 类定义 或者 函数定义 创建组件:
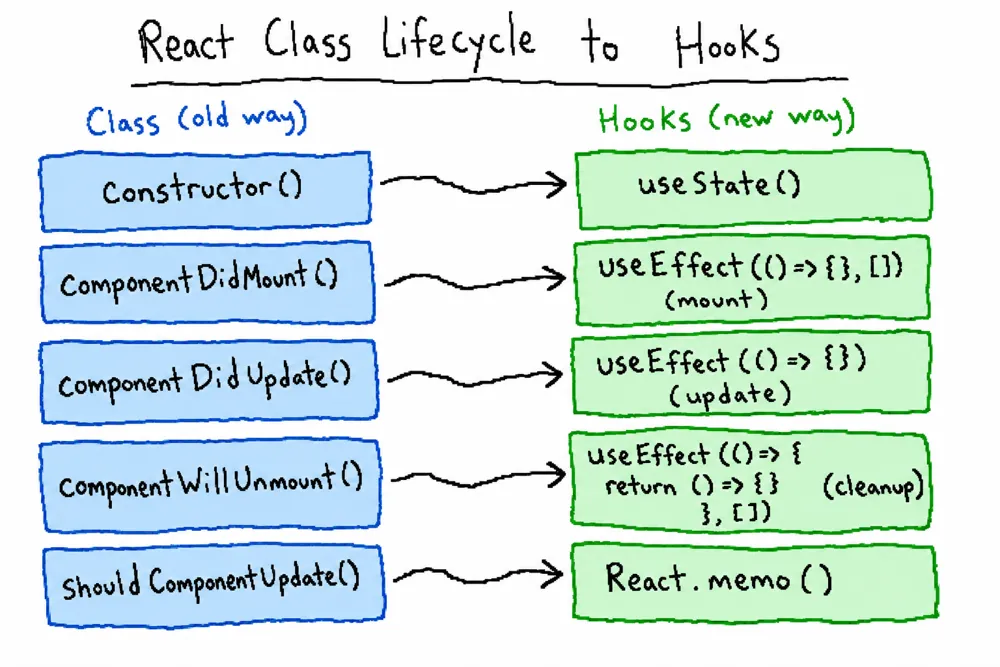
在类定义中,我们可以使用到许多 React 特性,例如 state、 各种组件生命周期钩子等,但是在函数定义中,我们却无能为力,因此 React 16.8 版本推出了一个新功能 (React Hooks),通过它,可以更好的在函数定义组件中使用 React 特性。
函数组件与类组件的对比:无关“优劣”,只谈“不同”
- 类组件需要继承 class,函数组件不需要;
- 类组件可以访问生命周期方法,函数组件不能;
- 类组件中可以获取到实例化后的 this,并基于这个 this 做各种各样的事情,而函数组件不可以;
- 类组件中可以定义并维护 state(状态),而函数组件不可以;
但是类组件它太重了,对于解决许多问题来说,编写一个类组件实在是一个过于复杂的姿势。复杂的姿势必然带来高昂的理解成本,这也是我们所不想看到的
react hooks的好处:
- 跨组件复用: 其实 render props / HOC 也是为了复用,相比于它们,Hooks 作为官方的底层 API,最为轻量,而且改造成本小,不会影响原来的组件层次结构和传说中的嵌套地狱;
- 类定义更为复杂
- 不同的生命周期会使逻辑变得分散且混乱,不易维护和管理;
- 时刻需要关注this的指向问题;
- 代码复用代价高,高阶组件的使用经常会使整个组件树变得臃肿;
- 状态与UI隔离: 正是由于 Hooks 的特性,状态逻辑会变成更小的粒度,并且极容易被抽象成一个自定义 Hooks,组件中的状态和 UI 变得更为清晰和隔离。
注意:
- 避免在 循环/条件判断/嵌套函数 中调用 hooks,保证调用顺序的稳定;
- 只有 函数定义组件 和 hooks 可以调用 hooks,避免在 类组件 或者 普通函数 中调用;
- 不能在useEffect中使用useState,React 会报错提示;
- 类组件不会被替换或废弃,不需要强制改造类组件,两种方式能并存;
重要钩子
- 状态钩子 (useState): 用于定义组件的 State,其到类定义中this.state的功能;
// useState 只接受一个参数: 初始状态
// 返回的是组件名和更改该组件对应的函数
const [flag, setFlag] = useState(true);
// 修改状态
setFlag(false)
// 上面的代码映射到类定义中:
this.state = {
flag: true
}
const flag = this.state.flag
const setFlag = (bool) => {
this.setState({
flag: bool,
})
}
- 生命周期钩子 (useEffect):
类定义中有许多生命周期函数,而在 React Hooks 中也提供了一个相应的函数 (useEffect),这里可以看做componentDidMount、componentDidUpdate和componentWillUnmount的结合。
useEffect(callback, [source])接受两个参数
- callback: 钩子回调函数;
- source: 设置触发条件,仅当 source 发生改变时才会触发;
- useEffect钩子在没有传入[source]参数时,默认在每次 render 时都会优先调用上次保存的回调中返回的函数,后再重新调用回调;
useEffect(() => {
// 组件挂载后执行事件绑定
console.log('on')
addEventListener()
// 组件 update 时会执行事件解绑
return () => {
console.log('off')
removeEventListener()
}
}, [source]);
// 每次 source 发生改变时,执行结果(以类定义的生命周期,便于大家理解):
// --- DidMount ---
// 'on'
// --- DidUpdate ---
// 'off'
// 'on'
// --- DidUpdate ---
// 'off'
// 'on'
// --- WillUnmount ---
// 'off'
通过第二个参数,我们便可模拟出几个常用的生命周期:
- componentDidMount: 传入[]时,就只会在初始化时调用一次
const useMount = (fn) => useEffect(fn, [])
- componentWillUnmount: 传入[],回调中的返回的函数也只会被最终执行一次
const useUnmount = (fn) => useEffect(() => fn, [])
- mounted: 可以使用 useState 封装成一个高度可复用的 mounted 状态;
const useMounted = () => {
const [mounted, setMounted] = useState(false);
useEffect(() => {
!mounted && setMounted(true);
return () => setMounted(false);
}, []);
return mounted;
}
- componentDidUpdate: useEffect每次均会执行,其实就是排除了 DidMount 后即可;
const mounted = useMounted()
useEffect(() => {
mounted && fn()
})
- 其它内置钩子:
useContext: 获取 context 对象useReducer: 类似于 Redux 思想的实现,但其并不足以替代 Redux,可以理解成一个组件内部的 redux:- 并不是持久化存储,会随着组件被销毁而销毁;
- 属于组件内部,各个组件是相互隔离的,单纯用它并无法共享数据;
- 配合useContext`的全局性,可以完成一个轻量级的 Redux;(easy-peasy)
useCallback: 缓存回调函数,避免传入的回调每次都是新的函数实例而导致依赖组件重新渲染,具有性能优化的效果;useMemo: 用于缓存传入的 props,避免依赖的组件每次都重新渲染;useRef: 获取组件的真实节点;useLayoutEffect- DOM更新同步钩子。用法与useEffect类似,只是区别于执行时间点的不同
- useEffect属于异步执行,并不会等待 DOM 真正渲染后执行,而useLayoutEffect则会真正渲染后才触发;
- 可以获取更新后的 state;
- 自定义钩子(useXxxxx): 基于 Hooks 可以引用其它 Hooks 这个特性,我们可以编写自定义钩子,如上面的useMounted。又例如,我们需要每个页面自定义标题:
function useTitle(title) {
useEffect(
() => {
document.title = title;
});
}
// 使用:
function Home() {
const title = '我是首页'
useTitle(title)
return (
<div>{title}</div>
)
}
React Hooks 的限制
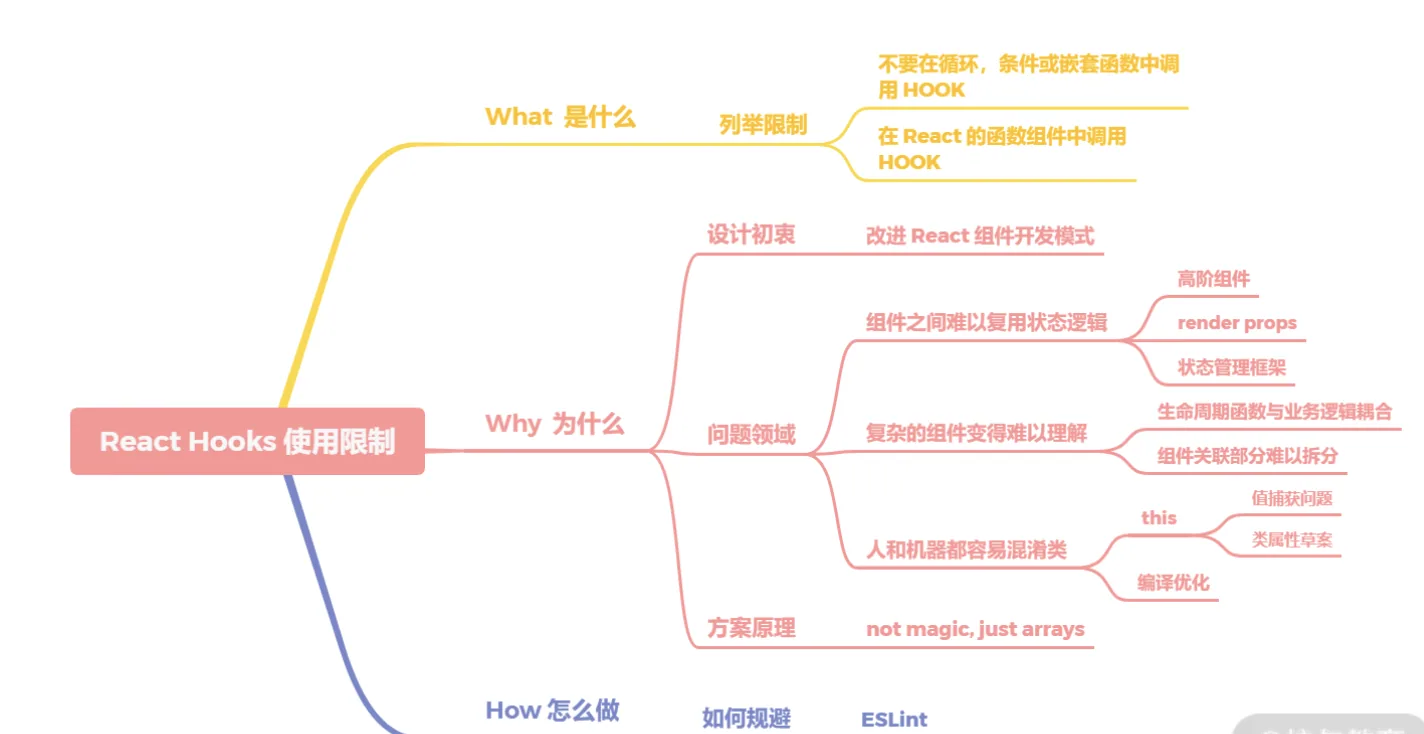
- 不要在
循环、条件或嵌套函数中调用 Hook; - 在 React 的函数组件中调用
Hook
那为什么会有这样的限制呢?就得从 Hooks 的设计说起。Hooks 的设计初衷是为了改进 React 组件的开发模式。在旧有的开发模式下遇到了三个问题。
- 组件之间难以复用状态逻辑。过去常见的解决方案是高阶组件、
render props及状态管理框架。 - 复杂的组件变得难以理解。生命周期函数与业务逻辑耦合太深,导致关联部分难以拆分。
- 常见的有 this 的问题,但在 React 团队中还有类难以优化的问题,他们希望在编译优化层面做出一些改进。
这三个问题在一定程度上阻碍了 React 的后续发展,所以为了解决这三个问题,Hooks 基于函数组件开始设计。然而第三个问题决定了 Hooks 只支持函数组件。
那为什么不要在循环、条件或嵌套函数中调用 Hook 呢?因为 Hooks 的设计是基于数组实现。在调用时按顺序加入数组中,如果使用循环、条件或嵌套函数很有可能导致数组取值错位,执行错误的 Hook。当然,实质上 React 的源码里不是数组,是链表。
这些限制会在编码上造成一定程度的心智负担,新手可能会写错,为了避免这样的情况,可以引入 ESLint 的 Hooks 检查插件进行预防。
useEffect 与 useLayoutEffect 区别在哪里
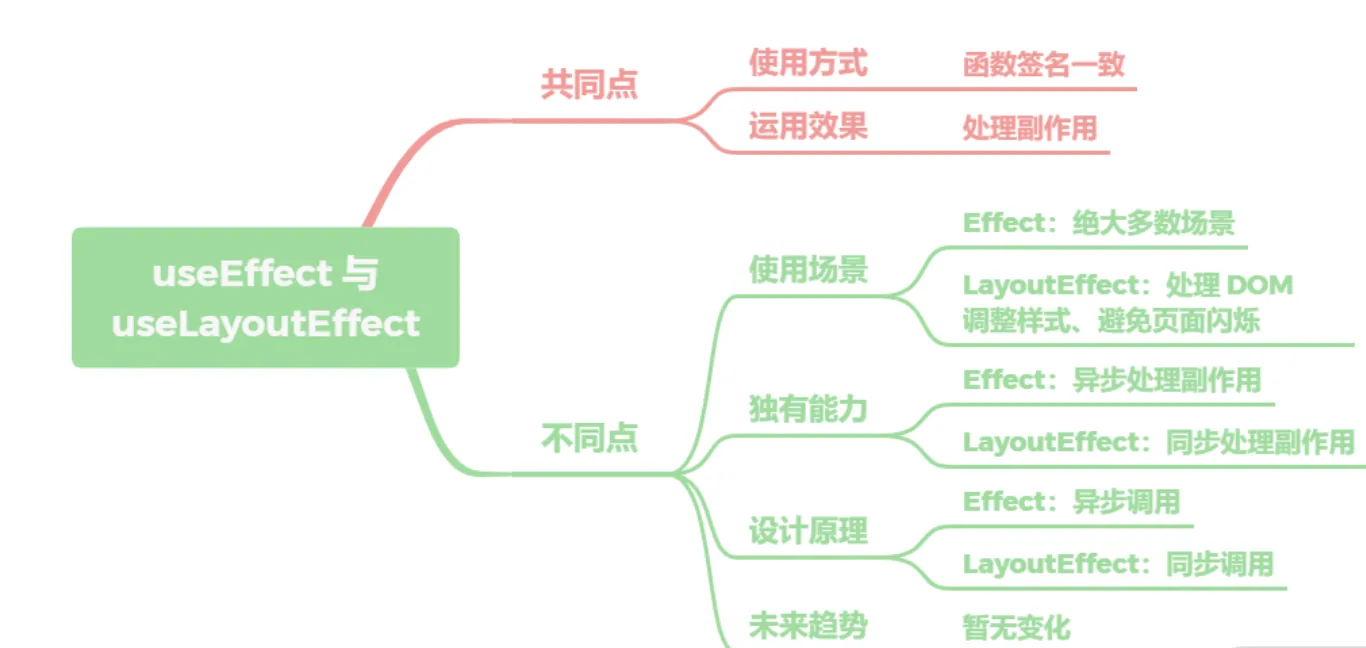
- 它们的共同点很简单,底层的函数签名是完全一致的,都是调用的
mountEffectImpl,在使用上也没什么差异,基本可以直接替换,也都是用于处理副作用。 - 那不同点就很大了,
useEffect在 React 的渲染过程中是被异步调用的,用于绝大多数场景,而LayoutEffect会在所有的 DOM 变更之后同步调用,主要用于处理 DOM 操作、调整样式、避免页面闪烁等问题。也正因为是同步处理,所以需要避免在LayoutEffect做计算量较大的耗时任务从而造成阻塞。 - 在未来的趋势上,两个 API 是会长期共存的,暂时没有删减合并的计划,需要开发者根据场景去自行选择。React 团队的建议非常实用,如果实在分不清,先用
useEffect,一般问题不大;如果页面有异常,再直接替换为useLayoutEffect即可。
21 受控组件和非受控组件
<FInput value = {x} onChange = {fn} />
// 上面的是受控组件 下面的是非受控组件
<FInput defaultValue = {x} />
- 当你一个组件同时传递一个value以及onChange事件时,它就是一个受控组件,收入输出都是我来控制的。
- 第二个只是传递了默认的初时值,并没有传onchange事件,
- 非受控组件是一种反模式,它的值不受组件自身的state或props控制
22 如何避免ajax数据请求重新获取
一般而言,ajax请求的数据都放在redux中存取。
23 组件之间通信
- 父子组件通信
- 自定义事件
- redux和context
context如何运用
- 父组件向其下所有子孙组件传递信息
- 如一些简单的信息:主题、语言
- 复杂的公共信息用redux
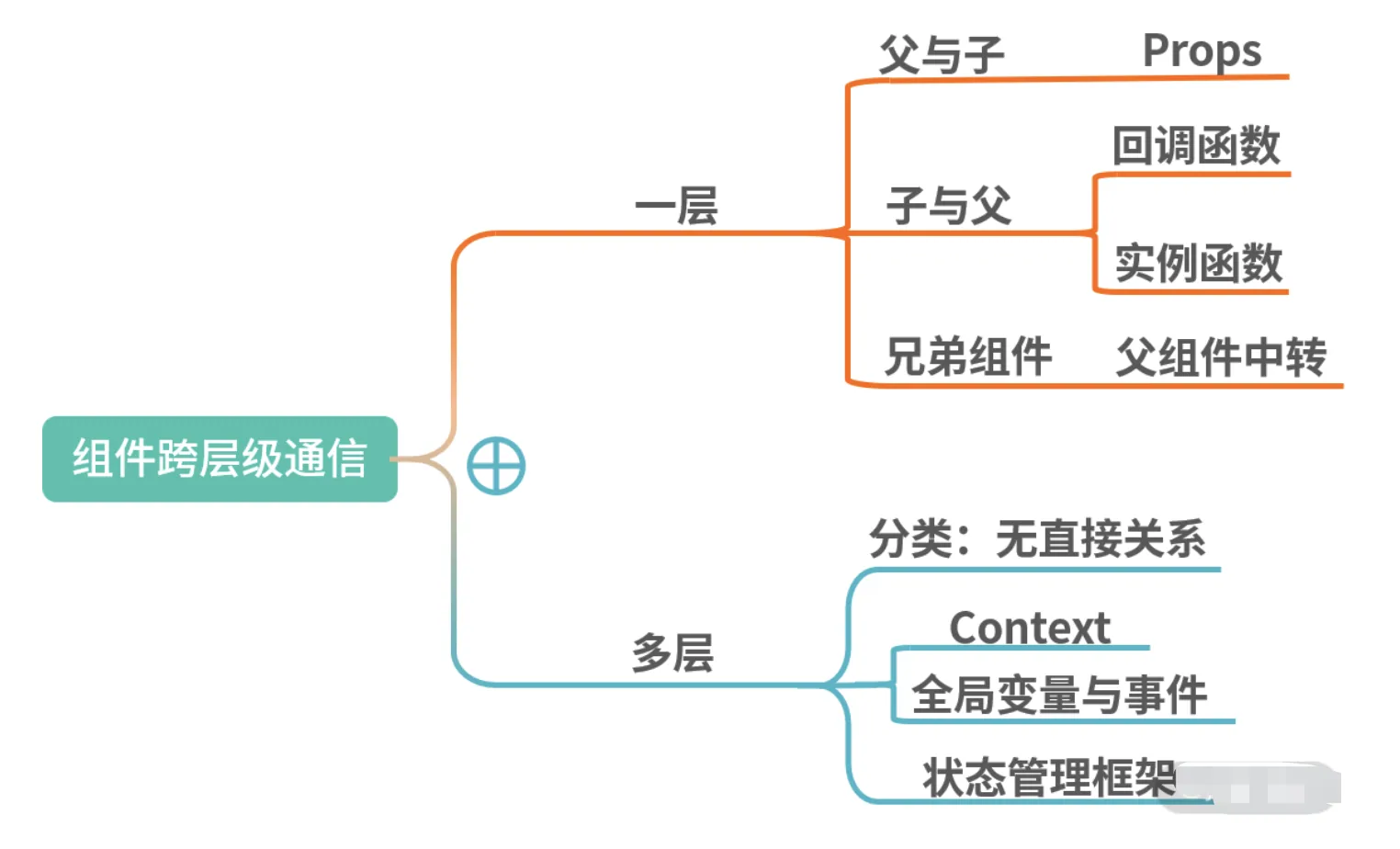
在跨层级通信中,主要分为一层或多层的情况
- 如果只有一层,那么按照 React 的树形结构进行分类的话,主要有以下三种情况:
父组件向子组件通信,子组件向父组件通信以及平级的兄弟组件间互相通信。 - 在父与子的情况下 ,因为 React 的设计实际上就是传递
Props即可。那么场景体现在容器组件与展示组件之间,通过Props传递state,让展示组件受控。 - 在子与父的情况下 ,有两种方式,分别是回调函数与实例函数。回调函数,比如输入框向父级组件返回输入内容,按钮向父级组件传递点击事件等。实例函数的情况有些特别,主要是在父组件中
通过 React 的 ref API 获取子组件的实例,然后是通过实例调用子组件的实例函数。这种方式在过去常见于 Modal 框的显示与隐藏 - 多层级间的数据通信,有两种情况 。第一种是一个容器中包含了多层子组件,需要最底部的子组件与顶部组件进行通信。在这种情况下,如果不断透传 Props 或回调函数,不仅代码层级太深,后续也很不好维护。第二种是两个组件不相关,在整个 React 的组件树的两侧,完全不相交。那么基于多层级间的通信一般有三个方案。
- 第一个是使用 React 的
Context API,最常见的用途是做语言包国际化 - 第二个是使用全局变量与事件。
- 第三个是使用状态管理框架,比如 Flux、Redux 及 Mobx。优点是由于引入了状态管理,使得项目的开发模式与代码结构得以约束,缺点是学习成本相对较高
- 第一个是使用 React 的
24 类组件与函数组件有什么区别呢?
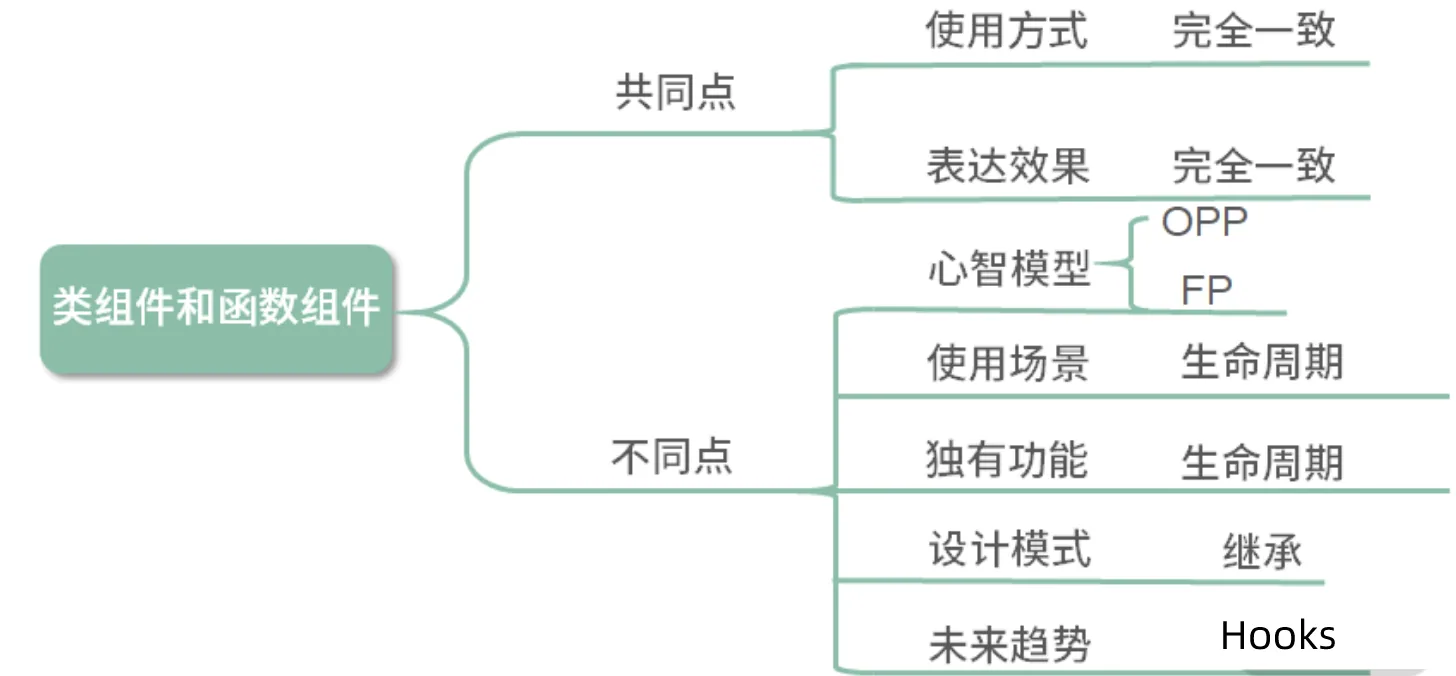
- 作为组件而言,类组件与函数组件在使用与呈现上没有任何不同,性能上在现代浏览器中也不会有明显差异
- 它们在开发时的心智模型上却存在巨大的差异。类组件是基于面向对象编程的,它主打的是继承、生命周期等核心概念;而函数组件内核是函数式编程,主打的是 immutable、没有副作用、引用透明等特点。
- 之前,在使用场景上,如果存在需要使用生命周期的组件,那么主推类组件;设计模式上,如果需要使用继承,那么主推类组件。
- 但现在由于 React Hooks 的推出,生命周期概念的淡出,函数组件可以完全取代类组件。
- 其次继承并不是组件最佳的设计模式,官方更推崇“组合优于继承”的设计概念,所以类组件在这方面的优势也在淡出。
- 性能优化上,类组件主要依靠
shouldComponentUpdate阻断渲染来提升性能,而函数组件依靠React.memo缓存渲染结果来提升性能。 - 从上手程度而言,类组件更容易上手,从未来趋势上看,由于React Hooks 的推出,函数组件成了社区未来主推的方案。
- 类组件在未来时间切片与并发模式中,由于生命周期带来的复杂度,并不易于优化。而函数组件本身轻量简单,且在 Hooks 的基础上提供了比原先更细粒度的逻辑组织与复用,更能适应 React 的未来发展。
25 如何设计React组件
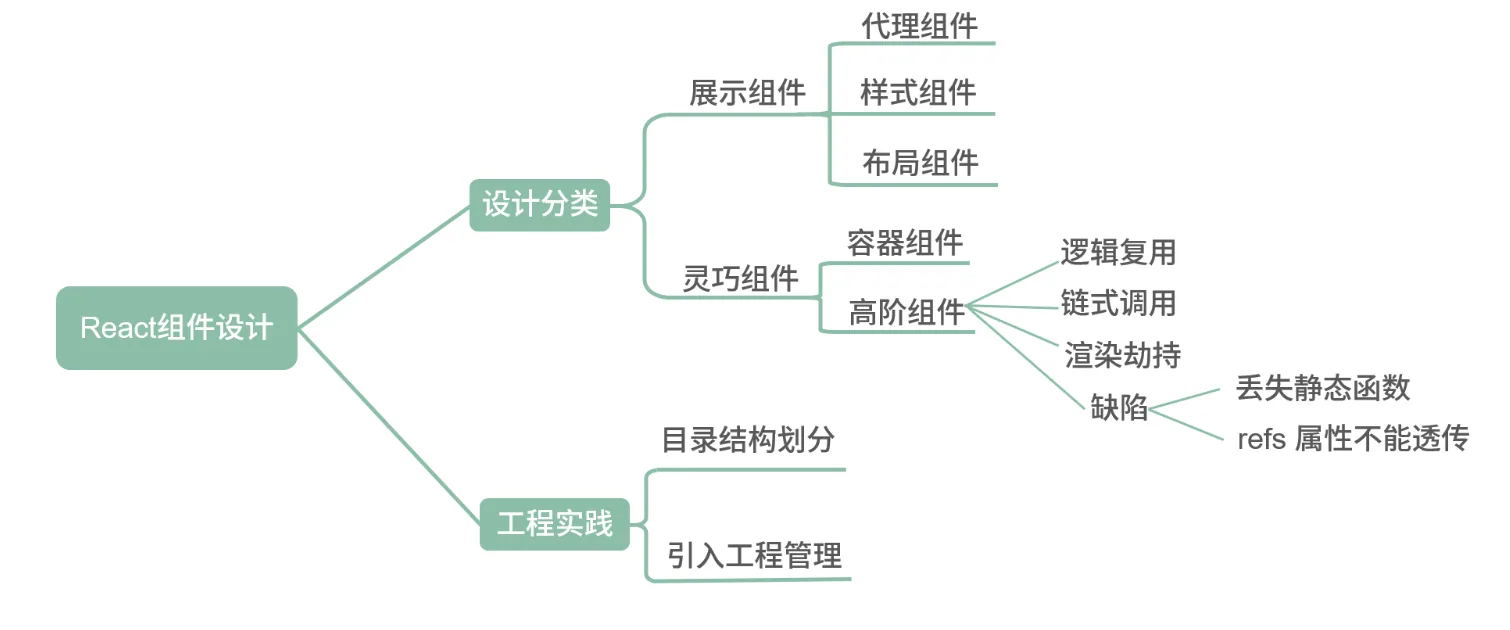
React 组件应从设计与工程实践两个方向进行探讨
从设计上而言,社区主流分类的方案是展示组件与灵巧组件
展示组件内部没有状态管理,仅仅用于最简单的展示表达。展示组件中最基础的一类组件称作代理组件。代理组件常用于封装常用属性、减少重复代码。很经典的场景就是引入 Antd 的 Button 时,你再自己封一层。如果未来需要替换掉 Antd 或者需要在所有的 Button 上添加一个属性,都会非常方便。基于代理组件的思想还可以继续分类,分为样式组件与布局组件两种,分别是将样式与布局内聚在自己组件内部。- 从工程实践而言,通过文件夹划分的方式切分代码。我初步常用的分割方式是将页面单独建立一个目录,将复用性略高的 components 建立一个目录,在下面分别建立 basic、container 和 hoc 三类。这样可以保证无法复用的业务逻辑代码尽量留在 Page 中,而可以抽象复用的部分放入 components 中。其中 basic 文件夹放展示组件,由于展示组件本身与业务关联性较低,所以可以使用 Storybook 进行组件的开发管理,提升项目的工程化管理能力
26 组件的协同及(不)可控组件
为什么要进行组件的协同
- 我们在实际的开发项目的时候,不会只用几个组件,有时候遇到大型的项目,可能会有成千上百的组件,难免会遇到有功能重复的组件。要进行修改,就会修改大部分的文件。所以我们需要进行组件的协同开发。

什么是组件的协同使用?
- 组件的协同本质上是对组件的一种组织、管理的方式。
- 目的:
- 逻辑清晰:这是组件与组件之间的逻辑
- 代码模块化
- 封装细节:像面向对象一样将常用的方法以及数据封装起来
- 提高代码的复用性:因为是组件,相当于一个封装好的东西,用的时候直接调用
如何实现组件的协同使用
- 第一种:增加一个父组件,将其他的组件进行嵌套,更多的是实现代码的封装
- 第二种:通过一些操作从后台获取数据,
React中的Mixin,更多的是实现代码的复用
组件嵌套的含义
- 组件嵌套的本质是父子关系

组件嵌套的优缺点
- 优点:
- 逻辑清晰:父子关系类似于人类中的父子关系
- 模块化开发:每个模块对应一个功能,不同的模块可以同步开发
- 封装细节:开发者必须要关注组件的功能,不需要了解细节
- 缺点:
- 编写难度高:父子组件的关系需要经过深思熟虑,贸然编写可能导致关系混乱,代码难以维护
- 无法掌握所有细节:使用者只知道组件的用法,不知道实现细节,遇到问题难以修复
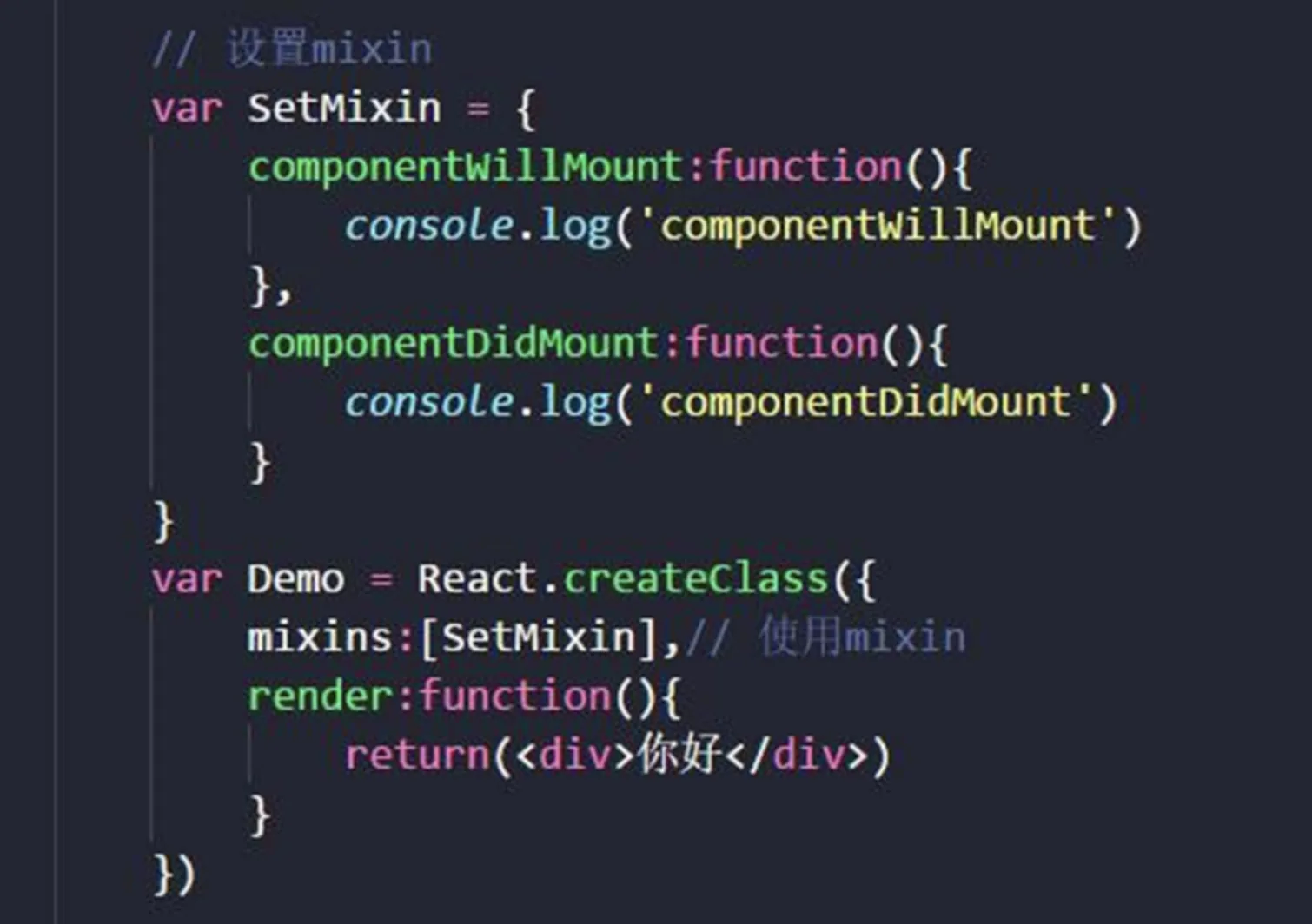
Mixin
Mixin的含义
Mixin=一组方法。- 他的目的是横向抽离出组件的相似代码,把组件的共同作用以及效果的代码提出来
Mixin的优缺点
- 优点
- 代码复用:抽离出通用的代码,减少开发成本,提高开发效率
- 即插即用:可以使用许多现有的
Mixin来开发自己的代码 - 适应性强:改动一次代码,影响多个组件
- 缺点
- 编写难度高:
Mixin可能被用在各种环境中,想要兼容多种环境就需要更多的 - 码与逻辑,通用的代价是提高复杂度 - 降低代码的可读性:组件的优势在于将逻辑与是界面直接结合在一起,
Mixin本质上会分散逻辑,理解起来难度大
- 编写难度高:
不可控组件

- 上图:
defaultValue的值是固定的,这就是一个不可控组件 - 如果要获取
input的value值,只有使用ref获取节点来获取值
可控组件

defaultValue的值是根据状态确定了,只需要拿到this.state.value的值就可以了- 这里需要注意一下:使用
value的值是不可修改的,defaultValue的值是可以修改的
可控组件的优点
- 符合
React的数据流 - 数据存储在
state中,便于获取 - 便于处理数据
27 React-Router 的实现原理及工作方式分别是什么
React Router路由的基础实现原理分为两种,如果是切换 Hash的方式,那么依靠浏览器Hash变化即可;如果是切换网址中的Path,就要用到HTML5 History API中的pushState、replaceState等。在使用这个方式时,还需要在服务端完成historyApiFallback配置- 在
React Router内部主要依靠history库完成,这是由React Router自己封装的库,为了实现跨平台运行的特性,内部提供两套基础history,一套是直接使用浏览器的History API,用于支持react-router-dom;另一套是基于内存实现的版本,这是自己做的一个数组,用于支持react-router-native。 React Router的工作方式可以分为设计模式与关键模块两个部分。从设计模式的角度出发,在架构上通过Monorepo进行库的管理。Monorepo具有团队间透明、迭代便利的优点。其次在整体的数据通信上使用了 Context API 完成上下文传递。- 在关键模块上,主要分为三类组件:
第一类是 Context 容器,比如 Router 与 MemoryRouter;第二类是消费者组件,用以匹配路由,主要有 Route、Redirect、Switch 等;第三类是与平台关联的功能组件,比如Link、NavLink、DeepLinking等。
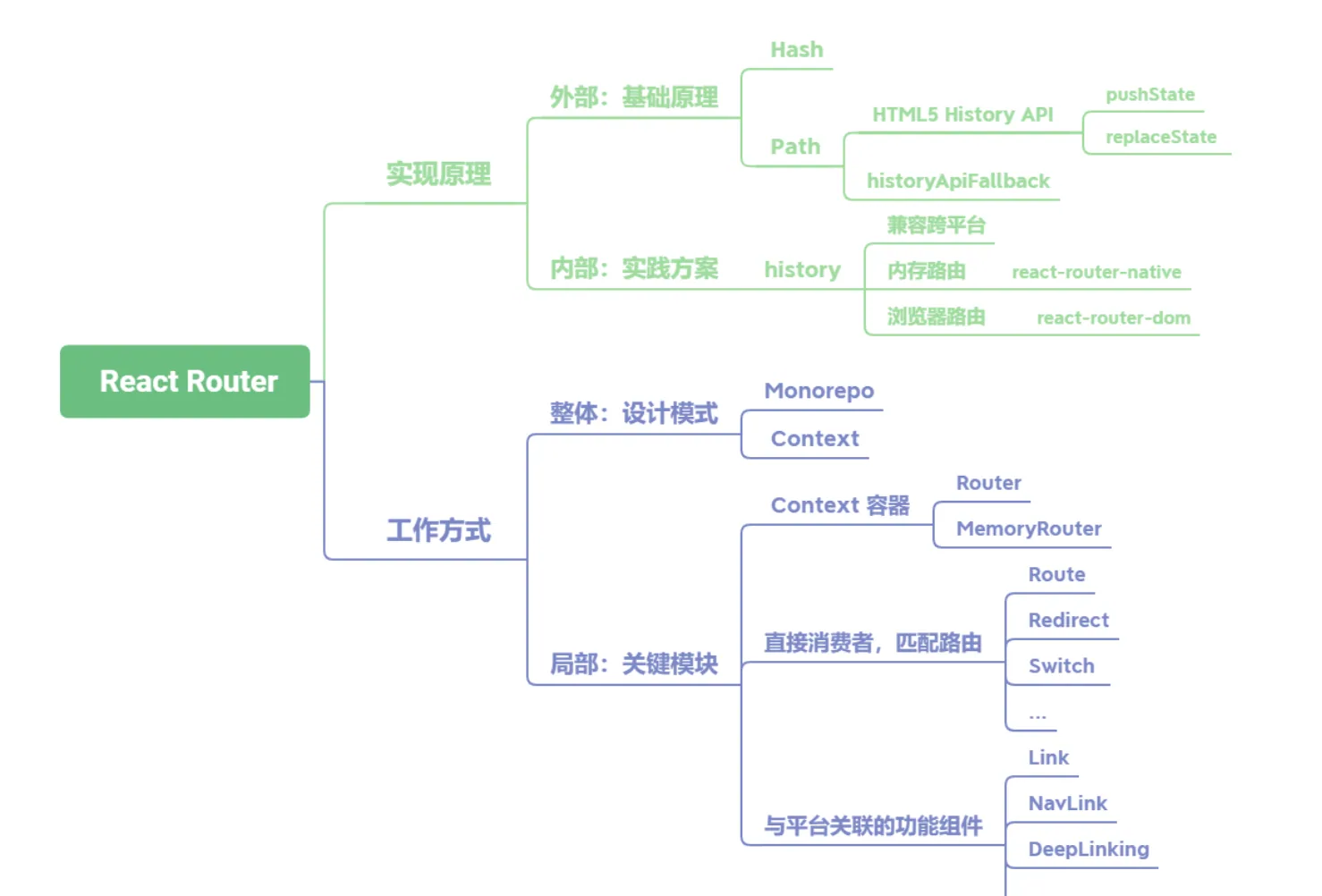

[React router原理分析 (opens new window)](http://interview.poetries.top/principle- docs/react/01-React-router%E5%8E%9F%E7%90%86.html)
28 React 17 带来了哪些改变
最重要的是以下三点:
- 新的
JSX转换逻辑 - 事件系统重构
Lane 模型的引入
1. 重构 JSX 转换逻辑
在过去,如果我们在 React 项目中写入下面这样的代码:
function MyComponent() {
return <p>这是我的组件</p>
}
React 是会报错的,原因是 React 中对 JSX 代码的转换依赖的是 React.createElement 这个函数。因此但凡我们在代码中包含了 JSX,那么就必须在文件中引入 React,像下面这样:
import React from 'react';
function MyComponent() {
return <p>这是我的组件</p>
}
而 React 17 则允许我们在不引入 React 的情况下直接使用 JSX。这是因为在 React 17 中,编译器会自动帮我们引入 JSX 的解析器,也就是说像下面这样一段逻辑:
function MyComponent() {
return <p>这是我的组件</p>
}
会被编译器转换成这个样子:
import {jsx as _jsx} from 'react/jsx-runtime';
function MyComponent() {
return _jsx('p', { children: '这是我的组件' });
}
react/jsx-runtime 中的 JSX 解析器将取代 React.createElement 完成 JSX 的编译工作,这个过程对开发者而言是自动化、无感知的。因此,新的 JSX 转换逻辑带来的最显著的改变就是降低了开发者的学习成本。
react/jsx-runtime 中的 JSX 解析器看上去似乎在调用姿势上和 React.createElement 区别不大,那么它是否只是 React.createElement 换了个马甲呢?当然不是,它在内部实现了 React.createElement 无法做到的性能优化和简化。在一定情况下,它可能会略微改善编译输出内容的大小
2. 事件系统重构
事件系统在 React 17 中的重构要从以下两个方面来看:
- 卸掉历史包袱
- 拥抱新的潮流
2.1 卸掉历史包袱:放弃利用 document 来做事件的中心化管控
React 16.13.x 版本中的事件系统会通过将所有事件冒泡到 document 来实现对事件的中心化管控
这样的做法虽然看上去已经足够巧妙,但仍然有它不聪明的地方——document 是整个文档树的根节点,操作 document 带来的影响范围实在是太大了,这将会使事情变得更加不可控
在 React 17 中,React 团队终于正面解决了这个问题:事件的中心化管控不会再全部依赖
document,管控相关的逻辑被转移到了每个 React 组件自己的容器 DOM 节点中。比如说我们在 ID 为 root 的 DOM 节点下挂载了一个 React 组件,像下面代码这样:
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);
那么事件管控相关的逻辑就会被安装到 root 节点上去。这样一来, React 组件就能够自己玩自己的,再也无法对全局的事件流构成威胁了
2.2 拥抱新的潮流:放弃事件池
在 React 17 之前,合成事件对象会被放进一个叫作“事件池”的地方统一管理。这样做的目的是能够实现事件对象的复用,进而提高性能:每当事件处理函数执行完毕后,其对应的合成事件对象内部的所有属性都会被置空,意在为下一次被复用做准备。这也就意味着事件逻辑一旦执行完毕,我们就拿不到事件对象了,React 官方给出的这个例子就很能说明问题,请看下面这个代码
function handleChange(e) {
// This won't work because the event object gets reused.
setTimeout(() => {
console.log(e.target.value); // Too late!
}, 100);
}
异步执行的
setTimeout回调会在handleChange这个事件处理函数执行完毕后执行,因此它拿不到想要的那个事件对象e。
要想拿到目标事件对象,必须显式地告诉 React——我永远需要它,也就是调用 e.persist() 函数,像下面这样:
function handleChange(e) {
// Prevents React from resetting its properties:
e.persist();
setTimeout(() => {
console.log(e.target.value); // Works
}, 100);
}
在 React 17 中,我们不需要 e.persist(),也可以随时随地访问我们想要的事件对象。
3. Lane 模型的引入
初学 React 源码的同学由此可能会很自然地认为:优先级就应该是用 Lane 来处理的。但事实上,React 16 中处理优先级采用的是 expirationTime 模型。
expirationTime模型使用expirationTime(一个时间长度) 来描述任务的优先级;而Lane 模型则使用二进制数来表示任务的优先级:
lane 模型通过将不同优先级赋值给一个位,通过 31 位的位运算来操作优先级。
Lane 模型提供了一个新的优先级排序的思路,相对于 expirationTime 来说,它对优先级的处理会更细腻,能够覆盖更多的边界条件。