七、React(1/2)
七、React
0 对虚拟DOM的理解
虚拟dom从来不是用来和直接操作dom对比的,它们俩最终殊途同归。虚拟dom只不过是局部更新的一个环节而已,整个环节的对比对象是全量更新。虚拟dom对于state=UI的意义是,虚拟dom使diff成为可能(理论上也可以直接用dom对象diff,但是太臃肿),促进了新的开发思想,又不至于性能太差。但是性能再好也不可能好过直接操作dom,人脑连diff都省了。还有一个很重要的意义是,对视图抽象,为跨平台助力
其实我最终希望你明白的事情只有一件:虚拟 DOM 的价值不在性能,而在别处。因此想要从性能角度来把握虚拟 DOM 的优势,无异于南辕北辙。偏偏在面试场景下,10 个人里面有 9 个都走这条歧路,最后9个人里面自然没有一个能自圆其说,实在让人惋惜。
[真正理解虚拟DOM (opens new window)](http://interview.poetries.top/principle- docs/react/15-%E7%9C%9F%E6%AD%A3%E7%90%86%E8%A7%A3%E8%99%9A%E6%8B%9FDOM.html)
1 谈谈你对React的理解
React 是一个网页 UI 框架,通过组件化的方式解决视图层开发复用的问题,本质是一个组件化框架。
- 它的核心设计思路有三点,分别是
声明式、组件化与 通用性。 - 声明式的优势在于直观与组合。
- 组件化的优势在于视图的拆分与模块复用,可以更容易做到高内聚低耦合。
- 通用性在于一次学习,随处编写。比如 React Native,React 360 等, 这里主要靠虚拟 DOM 来保证实现。
- 这使得 React 的适用范围变得足够广,无论是 Web、Native、VR,甚至 Shell 应用都可以进行开发。这也是 React 的优势。
- 但作为一个视图层的框架,React 的劣势也十分明显。它并没有提供完整的一揽子解决方 案,在开发大型前端应用时,需要向社区寻找并整合解决方案。虽然一定程度上促进了社区的繁荣,但也为开发者在技术选型和学习适用上造成了一定的成本。
- 承接在优势后,可以再谈一下自己对于 React 优化的看法、对虚拟 DOM 的看法
2 如何避免React生命周期中的坑
16.3版本
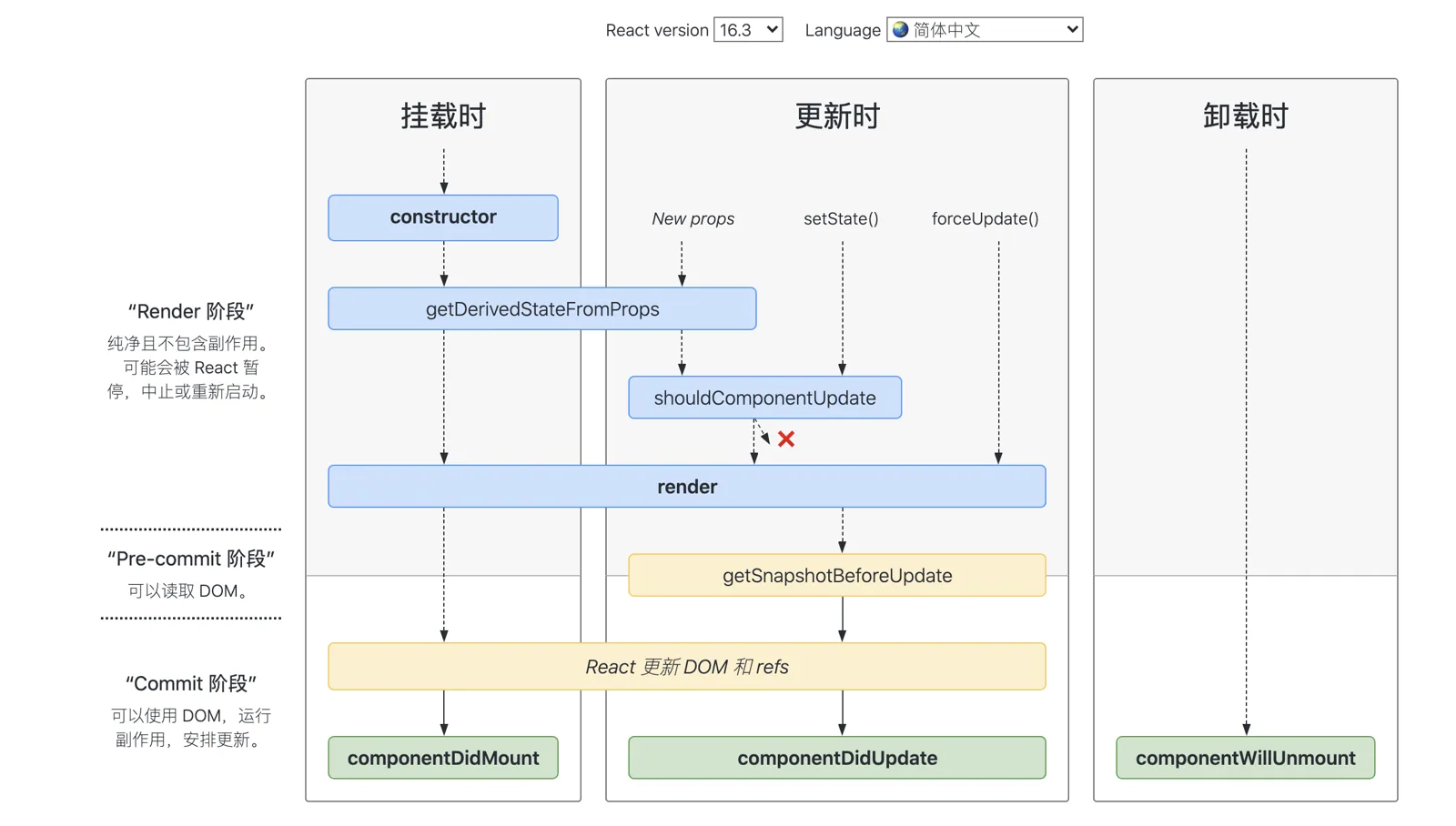
> =16.4版本
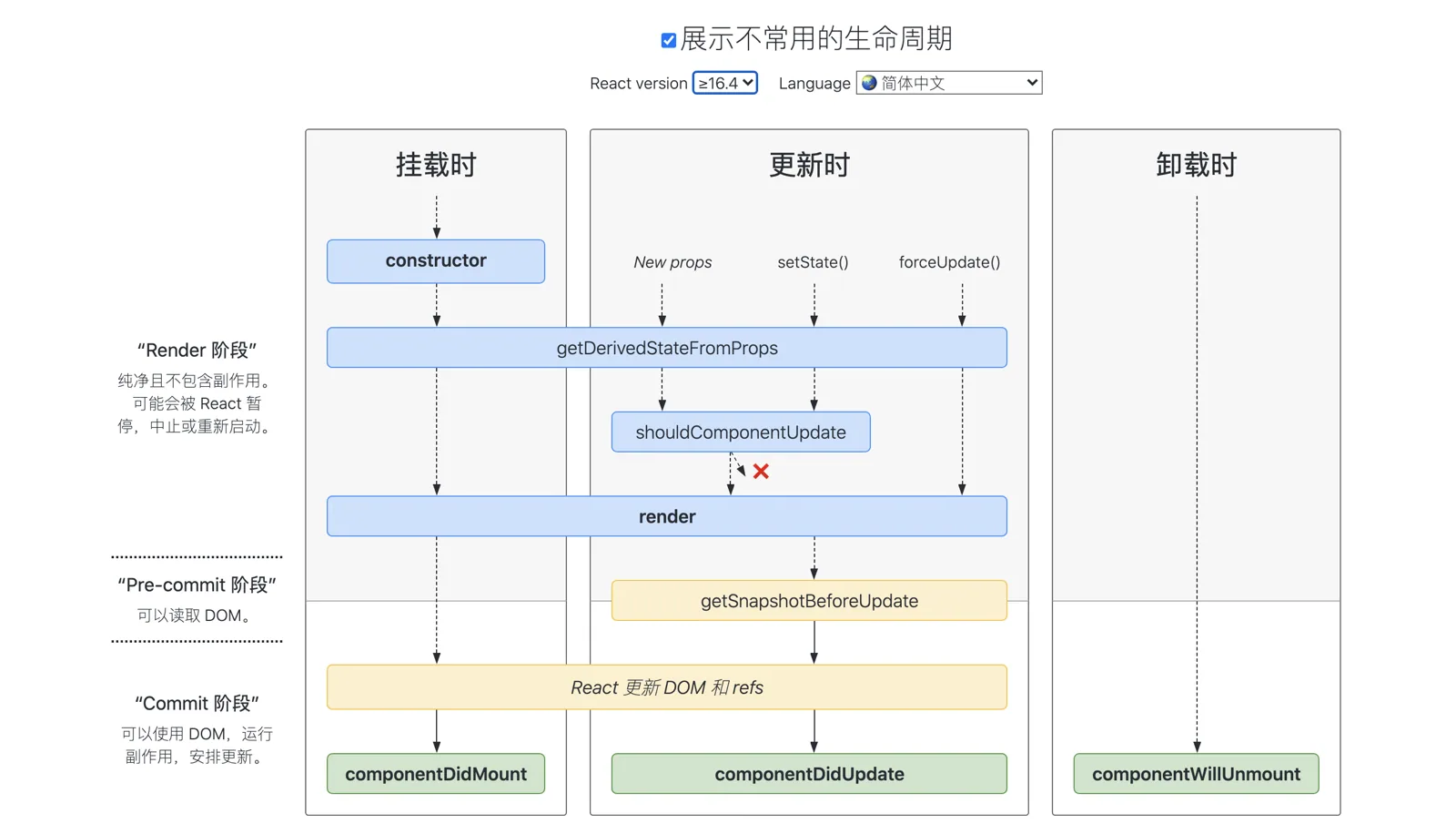
在线查看 :https://projects.wojtekmaj.pl/react-lifecycle-methods-diagram[ (opens new window)](https://projects.wojtekmaj.pl/react-lifecycle-methods- diagram)
- 避免生命周期中的坑需要做好两件事:不在恰当的时候调用了不该调用的代码;在需要调用时,不要忘了调用。
- 那么主要有这么 7 种情况容易造成生命周期的坑
getDerivedStateFromProps容易编写反模式代码,使受控组件与非受控组件区分模糊componentWillMount在 React 中已被标记弃用,不推荐使用,主要原因是新的异步渲染架构会导致它被多次调用。所以网络请求及事件绑定代码应移至componentDidMount中。componentWillReceiveProps同样被标记弃用,被getDerivedStateFromProps所取代,主要原因是性能问题shouldComponentUpdate通过返回true或者false来确定是否需要触发新的渲染。主要用于性能优化componentWillUpdate同样是由于新的异步渲染机制,而被标记废弃,不推荐使用,原先的逻辑可结合getSnapshotBeforeUpdate与componentDidUpdate改造使用。- 如果在
componentWillUnmount函数中忘记解除事件绑定,取消定时器等清理操作,容易引发 bug - 如果没有添加错误边界处理,当渲染发生异常时,用户将会看到一个无法操作的白屏,所以一定要添加
“React 的请求应该放在哪里,为什么?” 这也是经常会被追问的问题。你可以这样回答。
对于异步请求,应该放在 componentDidMount 中去操作。从时间顺序来看,除了 componentDidMount 还可以有以下选择:
- constructor:可以放,但从设计上而言不推荐。constructor 主要用于初始化 state 与函数绑定,并不承载业务逻辑。而且随着类属性的流行,constructor 已经很少使用了
- componentWillMount:已被标记废弃,在新的异步渲染架构下会触发多次渲染,容易引发 Bug,不利于未来 React 升级后的代码维护。
- 所以React 的请求放在
componentDidMount 里是最好的选择。
透过现象看本质:React 16 缘何两次求变?
Fiber 架构简析
Fiber 是 React 16 对 React 核心算法的一次重写。你只需要 get 到这一个点:
Fiber 会使原本同步的渲染过程变成异步的。
在 React 16 之前,每当我们触发一次组件的更新,React 都会构建一棵新的虚拟 DOM 树,通过与上一次的虚拟 DOM 树进行 diff,实现对 DOM 的定向更新。这个过程,是一个递归的过程。下面这张图形象地展示了这个过程的特征:
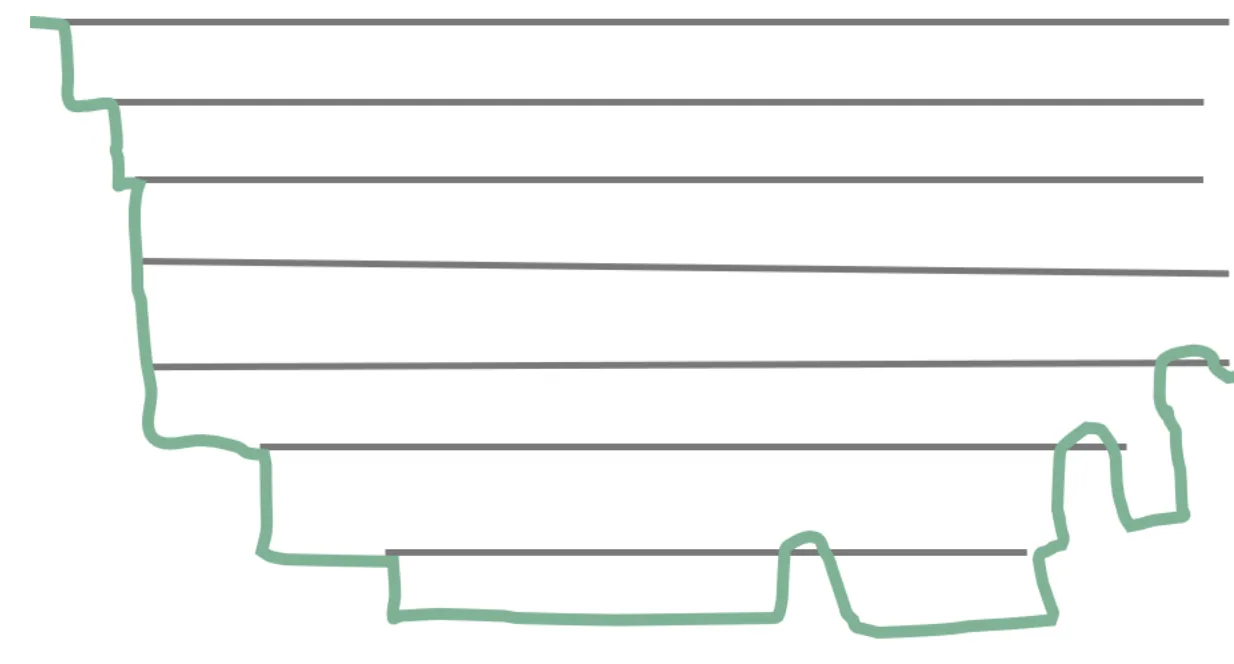
如图所示,同步渲染的递归调用栈是非常深的,只有最底层的调用返回了,整个渲染过程才会开始逐层返回。这个漫长且不可打断的更新过程,将会带来用户体验层面的巨大风险:同步渲染一旦开始,便会牢牢抓住主线程不放,直到递归彻底完成。在这个过程中,浏览器没有办法处理任何渲染之外的事情,会进入一种无法处理用户交互的状态。因此若渲染时间稍微长一点,页面就会面临卡顿甚至卡死的风险。
而 React 16 引入的 Fiber 架构,恰好能够解决掉这个风险:Fiber 会将一个大的更新任务拆解为许多个小任务。每当执行完一个小任务时,渲染线程都会把主线程交回去,看看有没有优先级更高的工作要处理,确保不会出现其他任务被“饿死”的情况,进而避免同步渲染带来的卡顿。在这个过程中,渲染线程不再“一去不回头”,而是可以被打断的,这就是所谓的“异步渲染”,它的执行过程如下图所示:

换个角度看生命周期工作流
Fiber 架构的重要特征就是可以被打断的异步渲染模式。但这个“打断”是有原则的,根据“能否被打断”这一标准,React 16 的生命周期被划分为了 render 和 commit 两个阶段,而 commit 阶段又被细分为了 pre-commit 和 commit。每个阶段所涵盖的生命周期如下图所示:
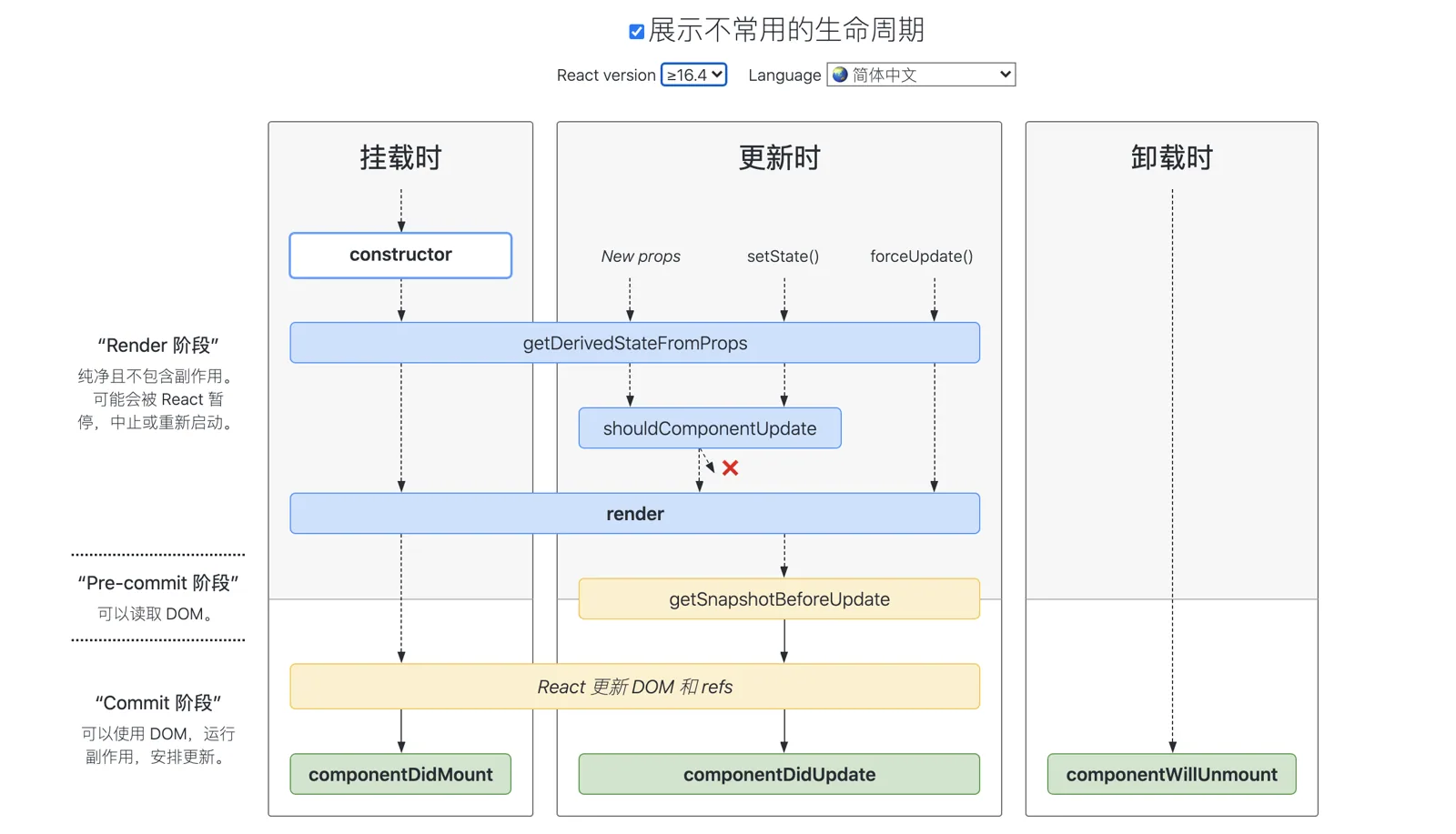
我们先来看下三个阶段各自有哪些特征
render 阶段:纯净且没有副作用,可能会被 React 暂停、终止或重新启动。pre-commit 阶段:可以读取 DOM。commit 阶段:可以使用 DOM,运行副作用,安排更新。
总的来说,render 阶段在执行过程中允许被打断,而 commit 阶段则总是同步执行的。
为什么这样设计呢?简单来说,
由于 render 阶段的操作对用户来说其实是“不可见”的,所以就算打断再重启,对用户来说也是零感知。而commit 阶段的操作则涉及真实 DOM 的渲染,所以这个过程必须用同步渲染来求稳。
为什么 React 16 要更改组件的生命周期详解
- [React16为什么要更改生命周期 (opens new window)](https://interview.poetries.top/principle- docs/react/11-React16%E4%B8%BA%E4%BB%80%E4%B9%88%E8%A6%81%E6%9B%B4%E6%94%B9%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F%E4%B8%8A.html)
- [React16为什么要更改生命周期 (opens new window)](https://interview.poetries.top/principle- docs/react/12-React16%E4%B8%BA%E4%BB%80%E4%B9%88%E8%A6%81%E6%9B%B4%E6%94%B9%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F%E4%B8%8B.html)
补充(现代做法):React 16.8 起函数组件 + Hooks 已是主流,新项目几乎不再写 class 组件。生命周期与 Hooks 的对应关系大致是:
class 生命周期 Hooks 写法 componentDidMountuseEffect(fn, [])componentDidUpdateuseEffect(fn, [deps])componentWillUnmountuseEffect里return () => {...}清理函数shouldComponentUpdateReact.memo+useMemo/useCallback实例属性 / this.xxxuseRef已废弃的
componentWillMount/componentWillReceiveProps/componentWillUpdate在严格模式下会告警,对应能力分别迁移到componentDidMount、getDerivedStateFromProps、getSnapshotBeforeUpdate(class)或直接用useEffect(函数组件)。注意 React 18 的 StrictMode 下,开发环境useEffect会刻意挂载-卸载-再挂载一次,用来暴露副作用未正确清理的问题。
3 React Fiber架构
最主要的思想就是将任务拆分 。
- DOM需要渲染时暂停,空闲时恢复。
window.requestIdleCallback- React内部实现的机制
React 追求的是 “快速响应”,那么,“快速响应“的制约因素都有什么呢
CPU的瓶颈:当项目变得庞大、组件数量繁多、遇到大计算量的操作或者设备性能不足使得页面掉帧,导致卡顿。IO的瓶颈:发送网络请求后,由于需要等待数据返回才能进一步操作导致不能快速响应。
fiber架构主要就是用来解决CPU和网络的问题,这两个问题一直也是最影响前端开发体验的地方,一个会造成卡顿,一个会造成白屏。为此 react 为前端引入了两个新概念:Time Slicing时间分片和Suspense。
1. React 都做过哪些优化
- React渲染页面的两个阶段
- 调度阶段(reconciliation):在这个阶段 React 会更新数据生成新的
Virtual DOM,然后通过Diff算法,快速找出需要更新的元素,放到更新队列中去,得到新的更新队列。 - 渲染阶段(commit):这个阶段 React 会遍历更新队列,将其所有的变更一次性更新到DOM上
- 调度阶段(reconciliation):在这个阶段 React 会更新数据生成新的
- React 15 架构
- React15架构可以分为两层
- Reconciler(协调器)—— 负责找出变化的组件;
- Renderer(渲染器)—— 负责将变化的组件渲染到页面上;
- React15架构可以分为两层
在React15及以前,Reconciler采用递归的方式创建虚拟DOM,递归过程是不能中断的。如果组件树的层级很深,递归会占用线程很多时间,递归更新时间超过了16ms,用户交互就会卡顿。 * 为了解决这个问题,React16将递归的无法中断的更新重构为异步的可中断更新,由于曾经用于递归的虚拟DOM数据结构已经无法满足需要。于是,全新的Fiber架构应运而生。
React 16 架构
- 为了解决同步更新长时间占用线程导致页面卡顿的问题,也为了探索运行时优化的更多可能,React开始重构并一直持续至今。重构的目标是实现Concurrent Mode(并发模式)。
- 从v15到v16,React团队花了两年时间将源码架构中的Stack Reconciler重构为Fiber Reconciler
React16架构可以分为三层:- Scheduler(调度器)—— 调度任务的优先级,高优任务优先进入Reconciler;
- Reconciler(协调器)—— 负责找出变化的组件:更新工作从递归变成了可以中断的循环过程。Reconciler内部采用了Fiber的架构;
- Renderer(渲染器)—— 负责将变化的组件渲染到页面上。
React 17 优化
- 使用Lane来管理任务的优先级。Lane用二进制位表示任务的优先级,方便优先级的计算(位运算),不同优先级占用不同位置的“赛道”,而且存在批的概念,优先级越低,“赛道”越多。高优先级打断低优先级,新建的任务需要赋予什么优先级等问题都是Lane所要解决的问题。
- Concurrent Mode的目的是实现一套可中断/恢复的更新机制。其由两部分组成:
- 一套协程架构:Fiber Reconciler
- 基于协程架构的启发式更新算法:控制协程架构工作方式的算法
2. 浏览器一帧都会干些什么以及requestIdleCallback的启示
我们都知道,页面的内容都是一帧一帧绘制出来的,浏览器刷新率代表浏览器一秒绘制多少帧。原则上说 1s 内绘制的帧数也多,画面表现就也细腻。目前浏览器大多是 60Hz(60帧/s),每一帧耗时也就是在 16.6ms 左右。那么在这一帧的(16.6ms) 过程中浏览器又干了些什么呢

通过上面这张图可以清楚的知道,浏览器一帧会经过下面这几个过程:
- 接受输入事件
- 执行事件回调
- 开始一帧
- 执行 RAF (RequestAnimationFrame)
- 页面布局,样式计算
- 绘制渲染
- 执行 RIC (RequestIdelCallback)
第七步的 RIC 事件不是每一帧结束都会执行,只有在一帧的 16.6ms 中做完了前面 6 件事儿且还有剩余时间,才会执行。如果一帧执行结束后还有时间执行 RIC 事件,那么下一帧需要在事件执行结束才能继续渲染,所以 RIC 执行不要超过 30ms,如果长时间不将控制权交还给浏览器,会影响下一帧的渲染,导致页面出现卡顿和事件响应不及时。
requestIdleCallback 的启示:我们以浏览器是否有剩余时间作微任务中断的标准,那么我们需要一种机制,当浏览器有剩余时间时通知我们。
requestIdleCallback((deadline) => {
// deadline 有两个参数
// timeRemaining(): 当前帧还剩下多少时间
// didTimeout: 是否超时
// 另外 requestIdleCallback 后如果跟上第二个参数 {timeout: ...} 则会强制浏览器在当前帧执行完后执行。
if (deadline.timeRemaining() > 0) {
// TODO
} else {
requestIdleCallback(otherTasks);
}
});
// 用法示例
var tasksNum = 10000
requestIdleCallback(unImportWork)
function unImportWork(deadline) {
while (deadline.timeRemaining() && tasksNum > 0) {
console.log(`执行了${10000 - tasksNum + 1}个任务`)
tasksNum--
}
if (tasksNum > 0) { // 在未来的帧中继续执行
requestIdleCallback(unImportWork)
}
}
其实部分浏览器已经实现了这个API,这就是requestIdleCallback。但是由于以下因素,Facebook 抛弃了
requestIdleCallback的原生 API:
- 浏览器兼容性;
- 触发频率不稳定,受很多因素影响。比如当我们的浏览器切换tab后,之前tab注册的
requestIdleCallback触发的频率会变得很低。
基于以上原因,在React中实现了功能更完备的
requestIdleCallbackpolyfill,这就是Scheduler。除了在空闲时触发回调的功能外,Scheduler还提供了多种调度优先级供任务设置
3. React Fiber是什么
React Fiber是对核心算法的一次重新实现。React Fiber把更新过程碎片化,把一个耗时长的任务分成很多小片,每一个小片的运行时间很短,虽然总时间依然很长,但是在每个小片执行完之后,都给其他任务一个执行的机会,这样唯一的线程就不会被独占,其他任务依然有运行的机会
- 在
React Fiber中,一次更新过程会分成多个分片完成,所以完全有可能一个更新任务还没有完成,就被另一个更高优先级的更新过程打断,这时候,优先级高的更新任务会优先处理完,而低优先级更新任务所做的工作则会完全作废,然后等待机会重头再来 - 因为一个更新过程可能被打断,所以
React Fiber一个更新过程被分为两个阶段(Phase):第一个阶段Reconciliation Phase和第二阶段Commit Phase - 在第一阶段
Reconciliation Phase,React Fiber会找出需要更新哪些DOM,这个阶段是可以被打断的;但是到了第二阶段Commit Phase,那就一鼓作气把DOM更新完,绝不会被打断 - 这两个阶段大部分工作都是
React Fiber做,和我们相关的也就是生命周期函数
React Fiber改变了之前react的组件渲染机制,新的架构使原来同步渲染的组件现在可以异步化,可中途中断渲染,执行更高优先级的任务。释放浏览器主线程
关键特性
- 增量渲染(把渲染任务拆分成块,匀到多帧)
- 更新时能够暂停,终止,复用渲染任务
- 给不同类型的更新赋予优先级
- 并发方面新的基础能力
增量渲染用来解决掉帧的问题,渲染任务拆分之后,每次只做一小段,做完一段就把时间控制权交还给主线程,而不像之前长时间占用
4. 组件的渲染顺序
假如有A,B,C,D组件,层级结构为:
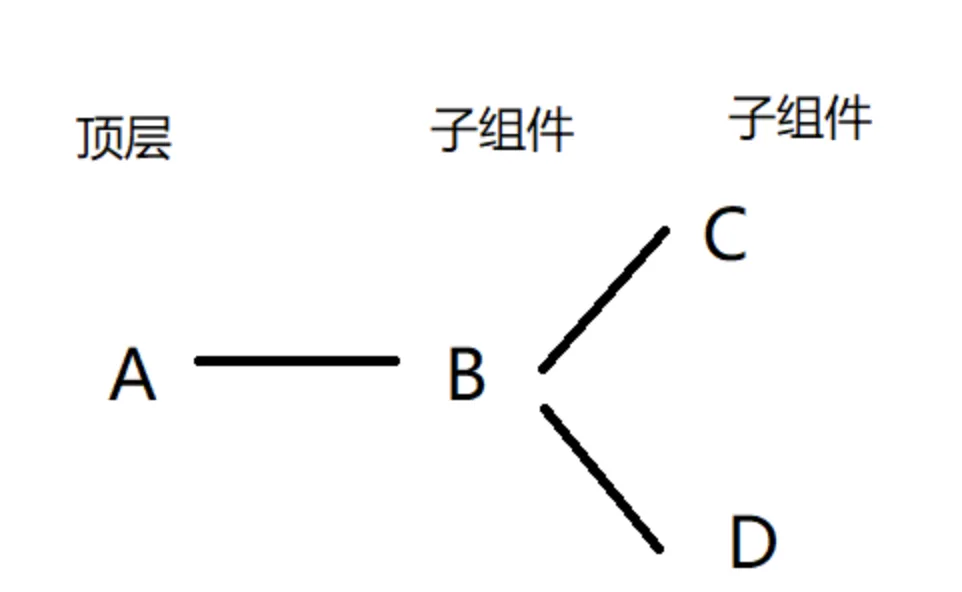
我们知道组件的生命周期为:
挂载阶段 :
constructor()componentWillMount()render()componentDidMount()
更新阶段为 :
componentWillReceiveProps()shouldComponentUpdate()componentWillUpdate()render()componentDidUpdate
那么在挂载阶段,
A,B,C,D的生命周期渲染顺序是如何的呢?
那么在挂载阶段,A,B,C,D的生命周期渲染顺序是如何的呢?
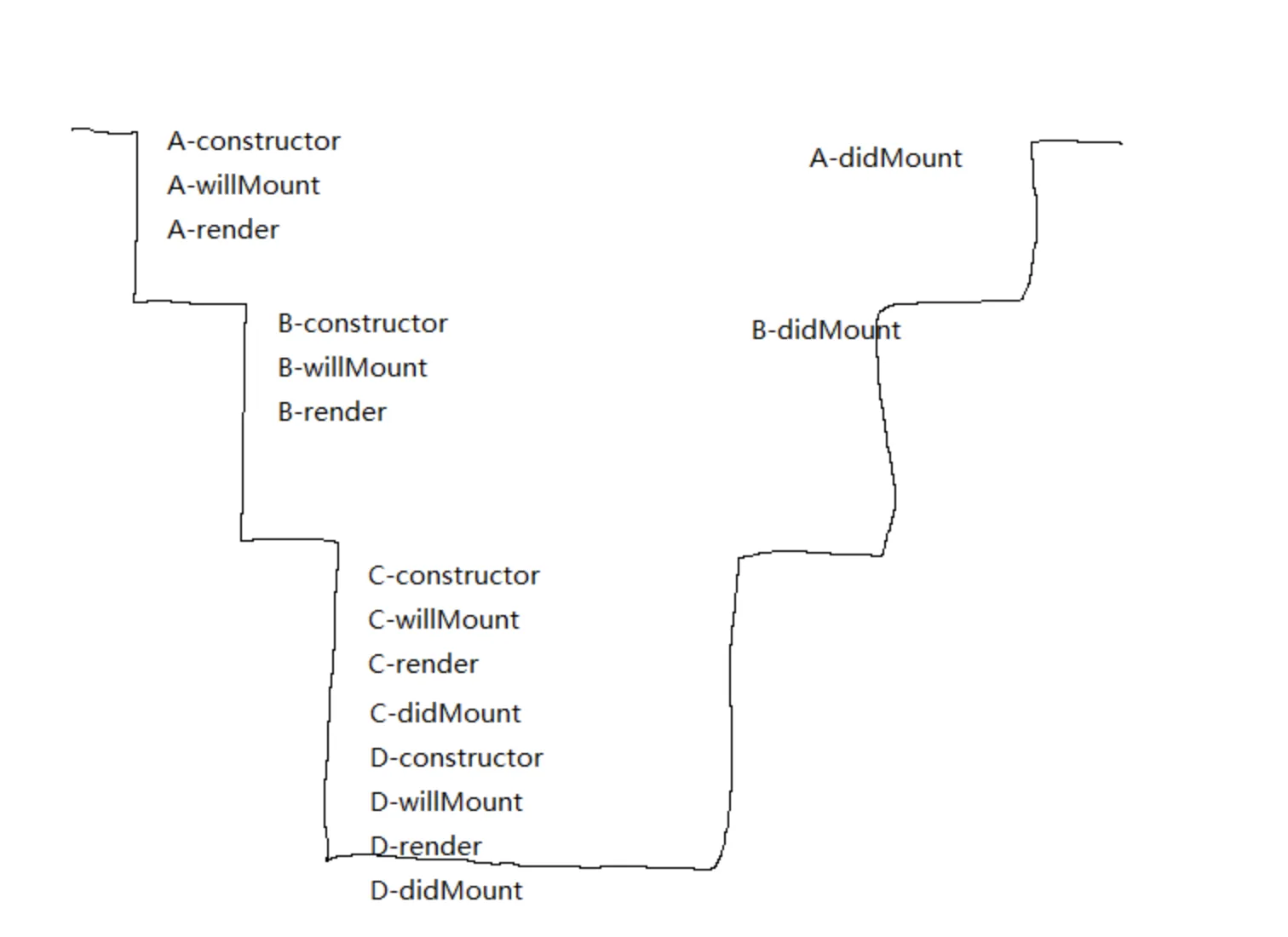
以
render()函数为分界线。从顶层组件开始,一直往下,直至最底层子组件。然后再往上
组件update阶段同理
前面是react16以前的组建渲染方式。这就存在一个问题
如果这是一个很大,层级很深的组件,
react渲染它需要几十甚至几百毫秒,在这期间,react会一直占用浏览器主线程,任何其他的操作(包括用户的点击,鼠标移动等操作)都无法执行
Fiber架构就是为了解决这个问题
看一下fiber架构 组建的渲染顺序
加入
fiber的react将组件更新分为两个时期
这两个时期以render为分界
render前的生命周期为phase1,render后的生命周期为phase2
phase1的生命周期是可以被打断的,每隔一段时间它会跳出当前渲染进程,去确定是否有其他更重要的任务。此过程,React在workingProgressTree(并不是真实的virtualDomTree)上复用current上的Fiber数据结构来一步地(通过requestIdleCallback)来构建新的 tree,标记处需要更新的节点,放入队列中phase2的生命周期是不可被打断的,React将其所有的变更一次性更新到DOM上
这里最重要的是phase1这是时期所做的事。因此我们需要具体了解phase1的机制
- 如果不被打断,那么
phase1执行完会直接进入render函数,构建真实的virtualDomTree - 如果组件再
phase1过程中被打断,即当前组件只渲染到一半(也许是在willMount,也许是willUpdate~反正是在render之前的生命周期),那么react会怎么干呢?react会放弃当前组件所有干到一半的事情,去做更高优先级更重要的任务(当然,也可能是用户鼠标移动,或者其他react监听之外的任务),当所有高优先级任务执行完之后,react通过callback回到之前渲染到一半的组件,从头开始渲染。(看起来放弃已经渲染完的生命周期,会有点不合理,反而会增加渲染时长,但是react确实是这么干的)
所有phase1的生命周期函数都可能被执行多次,因为可能会被打断重来
这样的话,就和
react16版本之前有很大区别了,因为可能会被执行多次,那么我们最好就得保证phase1的生命周期每一次执行的结果都是一样的,否则就会有问题,因此,最好都是纯函数
- 如果高优先级的任务一直存在,那么低优先级的任务则永远无法进行,组件永远无法继续渲染。这个问题facebook目前好像还没解决
- 所以,facebook在
react16增加fiber结构,其实并不是为了减少组件的渲染时间,事实上也并不会减少,最重要的是现在可以使得一些更高优先级的任务,如用户的操作能够优先执行,提高用户的体验,至少用户不会感觉到卡顿
5 React Fiber架构总结
React Fiber如何性能优化
- 更新的两个阶段
- 调度算法阶段-执行diff算法,纯js计算
- Commit阶段-将diff结果渲染dom
- 可能会有性能问题
- JS是单线程的,且和DOM渲染公用一个线程
- 当组件足够复杂,组件更新时计算和渲染压力都大
- 同时再有DOM操作需求(动画、鼠标拖拽等),将卡顿
- 解决方案fiber
- 将调度算法阶段阶段任务拆分(Commit无法拆分)
- DOM需要渲染时暂停,空闲时恢复
- 分散执行: 任务分割后,就可以把小任务单元分散到浏览器的空闲期间去排队执行,而实现的关键是两个新API:
requestIdleCallback与requestAnimationFrame- 低优先级的任务交给
requestIdleCallback处理,这是个浏览器提供的事件循环空闲期的回调函数,需要pollyfill,而且拥有deadline参数,限制执行事件,以继续切分任务; - 高优先级的任务交给
requestAnimationFrame处理;
- 低优先级的任务交给
React 的核心流程可以分为两个部分:
reconciliation(调度算法,也可称为render)- 更新
state与props; - 调用生命周期钩子;
- 生成
virtual dom- 这里应该称为
Fiber Tree更为符合;
- 这里应该称为
- 通过新旧 vdom 进行 diff 算法,获取 vdom change
- 确定是否需要重新渲染
- 更新
commit- 如需要,则操作
dom节点更新
- 如需要,则操作
要了解 Fiber,我们首先来看为什么需要它
- 问题 : 随着应用变得越来越庞大,整个更新渲染的过程开始变得吃力,大量的组件渲染会导致主进程长时间被占用,导致一些动画或高频操作出现卡顿和掉帧的情况。而关键点,便是 同步阻塞。在之前的调度算法中,React 需要实例化每个类组件,生成一颗组件树,使用 同步递归 的方式进行遍历渲染,而这个过程最大的问题就是无法 暂停和恢复。
- 解决方 案: 解决同步阻塞的方法,通常有两种: 异步 与 任务分割。而 React Fiber 便是为了实现任务分割而诞生的
- 简述
- 在
React V16将调度算法进行了重构, 将之前的stack reconciler重构成新版的 fiberreconciler,变成了具有链表和指针的 单链表树遍历算法。通过指针映射,每个单元都记录着遍历当下的上一步与下一步,从而使遍历变得可以被暂停和重启 - 这里我理解为是一种 任务分割调度算法,主要是 将原先同步更新渲染的任务分割成一个个独立的 小任务单位,根据不同的优先级,将小任务分散到浏览器的空闲时间执行,充分利用主进程的事件循环机制
- 在
- 核心
Fiber这里可以具象为一个 数据结构
class Fiber {
constructor(instance) {
this.instance = instance
// 指向第一个 child 节点
this.child = child
// 指向父节点
this.return = parent
// 指向第一个兄弟节点
this.sibling = previous
}
}
- 链表树遍历算法 : 通过 节点保存与映射,便能够随时地进行 停止和重启,这样便能达到实现任务分割的基本前提
- 首先通过不断遍历子节点,到树末尾;
- 开始通过
sibling遍历兄弟节点; - return 返回父节点,继续执行2;
- 直到 root 节点后,跳出遍历;
- 任务分割 ,React 中的渲染更新可以分成两个阶段
- reconciliation 阶段 : vdom 的数据对比,是个适合拆分的阶段,比如对比一部分树后,先暂停执行个动画调用,待完成后再回来继续比对
- Commit 阶段 : 将 change list 更新到 dom 上,并不适合拆分,才能保持数据与 UI 的同步。否则可能由于阻塞 UI 更新,而导致数据更新和 UI 不一致的情况
- 分散执行: 任务分割后,就可以把小任务单元分散到浏览器的空闲期间去排队执行,而实现的关键是两个新API:
requestIdleCallback与requestAnimationFrame- 低优先级的任务交给
requestIdleCallback处理,这是个浏览器提供的事件循环空闲期的回调函数,需要pollyfill,而且拥有deadline参数,限制执行事件,以继续切分任务; - 高优先级的任务交给
requestAnimationFrame处理;
- 低优先级的任务交给
// 类似于这样的方式
requestIdleCallback((deadline) => {
// 当有空闲时间时,我们执行一个组件渲染;
// 把任务塞到一个个碎片时间中去;
while ((deadline.timeRemaining() > 0 || deadline.didTimeout) && nextComponent) {
nextComponent = performWork(nextComponent);
}
});
- 优先级策略: 文本框输入 > 本次调度结束需完成的任务 > 动画过渡 > 交互反馈 > 数据更新 > 不会显示但以防将来会显示的任务
- Fiber 其实可以算是一种编程思想,在其它语言中也有许多应用(Ruby Fiber)。
- 核心思想是 任务拆分和协同,主动把执行权交给主线程,使主线程有时间空挡处理其他高优先级任务。
- 当遇到进程阻塞的问题时,任务分割、异步调用 和 缓存策略 是三个显著的解决思路。
4 createElement过程
React.createElement(): 根据指定的第一个参数创建一个React元素
React.createElement(
type,
[props],
[...children]
)
- 第一个参数是必填,传入的是似HTML标签名称,eg: ul, li
- 第二个参数是选填,表示的是属性,eg: className
- 第三个参数是选填, 子节点,eg: 要显示的文本内容
//写法一:
var child1 = React.createElement('li', null, 'one');
var child2 = React.createElement('li', null, 'two');
var content = React.createElement('ul', { className: 'teststyle' }, child1, child2); // 第三个参数可以分开也可以写成一个数组
ReactDOM.render(
content,
document.getElementById('example')
);
//写法二:
var child1 = React.createElement('li', null, 'one');
var child2 = React.createElement('li', null, 'two');
var content = React.createElement('ul', { className: 'teststyle' }, [child1, child2]);
ReactDOM.render(
content,
document.getElementById('example')
);
5 调和阶段 setState内部干了什么
- 当调用 setState 时,React会做的第一件事情是将传递给 setState 的对象合并到组件的当前状态
- 这将启动一个称为和解(
reconciliation)的过程。和解(reconciliation)的最终目标是以最有效的方式,根据这个新的状态来更新UI。 为此,React将构建一个新的React元素树(您可以将其视为UI的对象表示) - 一旦有了这个树,为了弄清 UI 如何响应新的状态而改变,React 会将这个新树与上一个元素树相比较( diff )
通过这样做, React 将会知道发生的确切变化,并且通过了解发生什么变化,只需在绝对必要的情况下进行更新即可最小化 UI 的占用空间
6 setState
在了解setState之前,我们先来简单了解下 React 一个包装结构: Transaction:
事务 (Transaction)
是 React 中的一个调用结构,用于包装一个方法,结构为: initialize - perform(method) - close。通过事务,可以统一管理一个方法的开始与结束;处于事务流中,表示进程正在执行一些操作
- setState: React 中用于修改状态,更新视图。它具有以下特点:
异步与同步: setState并不是单纯的异步或同步,这其实与调用时的环境相关:
- 在合成事件 和 生命周期钩子(除 componentDidUpdate) 中,setState是"异步"的;
- 原因: 因为在setState的实现中,有一个判断: 当更新策略正在事务流的执行中时,该组件更新会被推入dirtyComponents队列中等待执行;否则,开始执行batchedUpdates队列更新;
- 在生命周期钩子调用中,更新策略都处于更新之前,组件仍处于事务流中,而componentDidUpdate是在更新之后,此时组件已经不在事务流中了,因此则会同步执行;
- 在合成事件中,React 是基于 事务流完成的事件委托机制 实现,也是处于事务流中;
- 问题: 无法在setState后马上从this.state上获取更新后的值。
- 解决: 如果需要马上同步去获取新值,setState其实是可以传入第二个参数的。setState(updater, callback),在回调中即可获取最新值;
- 原因: 因为在setState的实现中,有一个判断: 当更新策略正在事务流的执行中时,该组件更新会被推入dirtyComponents队列中等待执行;否则,开始执行batchedUpdates队列更新;
- 在 原生事件 和 setTimeout 中,setState是同步的,可以马上获取更新后的值;
- 原因: 原生事件是浏览器本身的实现,与事务流无关,自然是同步;而setTimeout是放置于定时器线程中延后执行,此时事务流已结束,因此也是同步;
- 批量更新 : 在 合成事件 和 生命周期钩子 中,setState更新队列时,存储的是 合并状态(Object.assign)。因此前面设置的 key 值会被后面所覆盖,最终只会执行一次更新;
- 函数式 : 由于 Fiber 及 合并 的问题,官方推荐可以传入 函数 的形式。setState(fn),在fn中返回新的state对象即可,例如this.setState((state, props) => newState);
- 使用函数式,可以用于避免setState的批量更新的逻辑,传入的函数将会被 顺序调用;
注意事项:
- setState 合并,在 合成事件 和 生命周期钩子 中多次连续调用会被优化为一次;
- 当组件已被销毁,如果再次调用setState,React 会报错警告,通常有两种解决办法
- 将数据挂载到外部,通过 props 传入,如放到 Redux 或 父级中;
- 在组件内部维护一个状态量 (isUnmounted),componentWillUnmount中标记为 true,在setState前进行判断;
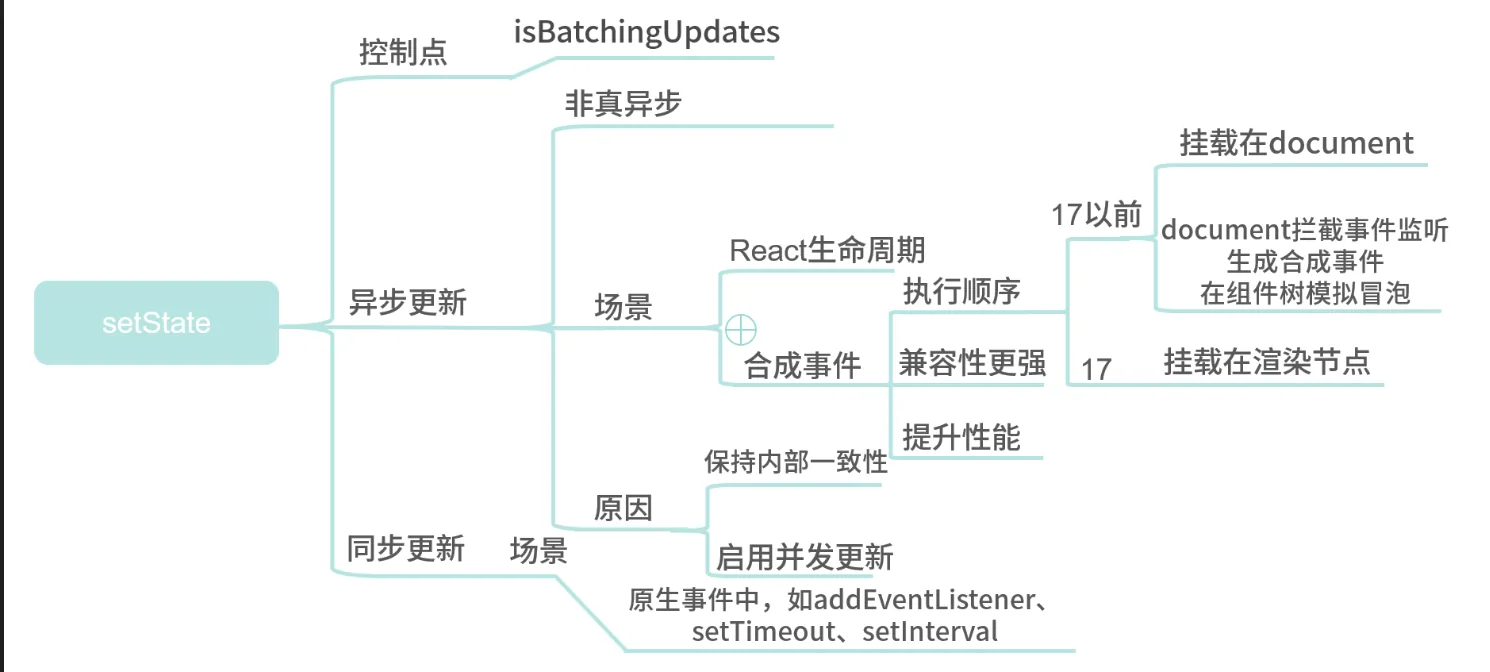
总结
setState 并非真异步,只是看上去像异步。在源码中,通过
isBatchingUpdates来判断
setState是先存进state队列还是直接更新,如果值为 true 则执行异步操作,为 false 则直接更新。- 那么什么情况下
isBatchingUpdates会为true呢?在 React 可以控制的地方,就为 true,比如在 React 生命周期事件和合成事件中,都会走合并操作,延迟更新的策略。 - 但在 React 无法控制的地方,比如原生事件,具体就是在
addEventListener、setTimeout、setInterval等事件中,就只能同步更新。
一般认为,
做异步设计是为了性能优化、减少渲染次数,React 团队还补充了两点。
- 保持内部一致性。如果将 state 改为同步更新,那尽管 state 的更新是同步的,但是 props不是。
- 启用并发更新,完成异步渲染。
setState只有在 React 自身的合成事件和钩子函数中是异步的,在原生事件和 setTimeout 中都是同步的setState的异步并不是说内部由异步代码实现,其实本身执行的过程和代码都是同步的,只是合成事件和钩子函数中没法立马拿到更新后的值,形成了所谓的异步。当然可以通过 setState 的第二个参数中的 callback 拿到更新后的结果setState的批量更新优化也是建立在异步(合成事件、钩子函数)之上的,在原生事件和 setTimeout 中不会批量更新,在异步中如果对同一个值进行多次 setState,setState 的批量更新策略会对其进行覆盖,去最后一次的执行,如果是同时 setState 多个不同的值,在更新时会对其进行合并批量更新
- 合成事件中是异步
- 钩子函数中的是异步
- 原生事件中是同步
- setTimeout中是同步



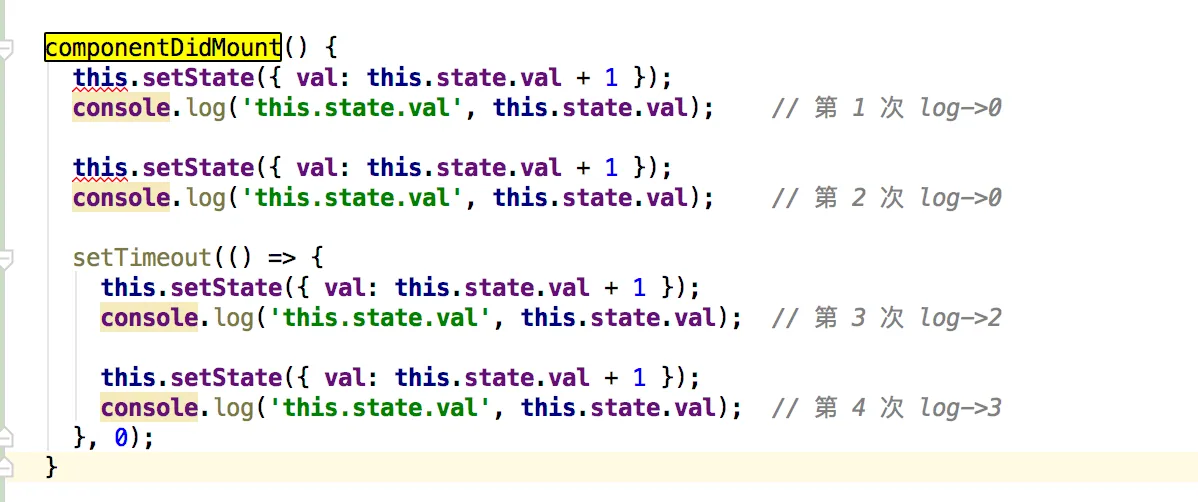
这是一道经常会出现的 React setState 笔试题:下面的代码输出什么呢?
class Test extends React.Component {
state = {
count: 0
};
componentDidMount() {
this.setState({count: this.state.count + 1});
console.log(this.state.count);
this.setState({count: this.state.count + 1});
console.log(this.state.count);
setTimeout(() => {
this.setState({count: this.state.count + 1});
console.log(this.state.count);
this.setState({count: this.state.count + 1});
console.log(this.state.count);
}, 0);
}
render() {
return null;
}
};
我们可以进行如下的分析:
- 首先第一次和第二次的
console.log,都在 React 的生命周期事件中,所以是异步的处理方式,则输出都为0; - 而在
setTimeout中的console.log处于原生事件中,所以会同步的处理再输出结果,但需要注意,虽然count在前面经过了两次的this.state.count + 1,但是每次获取的this.state.count都是初始化时的值,也就是0; - 所以此时
count是1,那么后续在setTimeout中的输出则是2和3。
所以完整答案是 0,0,2,3
同步场景
异步场景中的案例使我们建立了这样一个认知:setState 是异步的,但下面这个案例又会颠覆你的认知。如果我们将 setState 放在 setTimeout 事件中,那情况就完全不同了。
class Test extends Component {
state = {
count: 0
}
componentDidMount(){
this.setState({ count: this.state.count + 1 });
console.log(this.state.count);
setTimeout(() => {
this.setState({ count: this.state.count + 1 });
console.log("setTimeout: " + this.state.count);
}, 0);
}
render(){
...
}
}
那这时输出的应该是什么呢?如果你认为是 0,0,那么又错了。
正确的结果是 0,2。因为 setState 并不是真正的异步函数,它实际上是通过队列延迟执行操作实现的,通过 isBatchingUpdates 来判断 setState 是先存进 state 队列还是直接更新。值为 true 则执行异步操作,false 则直接同步更新
接下来这个案例的答案是什么呢
class Test extends Component {
state = {
count: 0
}
componentDidMount(){
this.setState({
count: this.state.count + 1
}, () => {
console.log(this.state.count)
})
this.setState({
count: this.state.count + 1
}, () => {
console.log(this.state.count)
})
}
render(){
...
}
}
如果你觉得答案是 1,2,那肯定就错了。这种迷惑性极强的考题在面试中非常常见,因为它反直觉。
如果重新仔细思考,你会发现当前拿到的 this.state.count 的值并没有变化,都是 0,所以输出结果应该是 1,1。
当然,也可以在 setState 函数中获取修改后的 state 值进行修改。
class Test extends Component {
state = {
count: 0
}
componentDidMount(){
this.setState(
preState=> ({
count:preState.count + 1
}),()=>{
console.log(this.state.count)
})
this.setState(
preState=>({
count:preState.count + 1
}),()=>{
console.log(this.state.count)
})
}
render(){
...
}
}
这些通通是异步的回调,如果你以为输出结果是 1,2,那就又错了,实际上是 2,2。
为什么会这样呢?当调用 setState 函数时,就会把当前的操作放入队列中。React 根据队列内容,合并 state 数据,完成后再逐一执行回调,根据结果更新虚拟 DOM,触发渲染。所以回调时,state 已经合并计算完成了,输出的结果就是 2,2 了。
7 setState原理分析
1. setState异步更新
- 我们都知道,
React通过this.state来访问state,通过this.setState()方法来更新state。当this.setState()方法被调用的时候,React会重新调用render方法来重新渲染UI - 首先如果直接在
setState后面获取state的值是获取不到的。在React内部机制能检测到的地方,setState就是异步的;在React检测不到的地方,例如setInterval,setTimeout,setState就是同步更新的
因为
setState是可以接受两个参数的,一个state,一个回调函数。因此我们可以在回调函数里面获取值

setState方法通过一个队列机制实现state更新,当执行setState的时候,会将需要更新的state合并之后放入状态队列,而不会立即更新this.state- 如果我们不使用
setState而是使用this.state.key来修改,将不会触发组件的re-render。 - 如果将
this.state赋值给一个新的对象引用,那么其他不在对象上的state将不会被放入状态队列中,当下次调用setState并对状态队列进行合并时,直接造成了state丢失
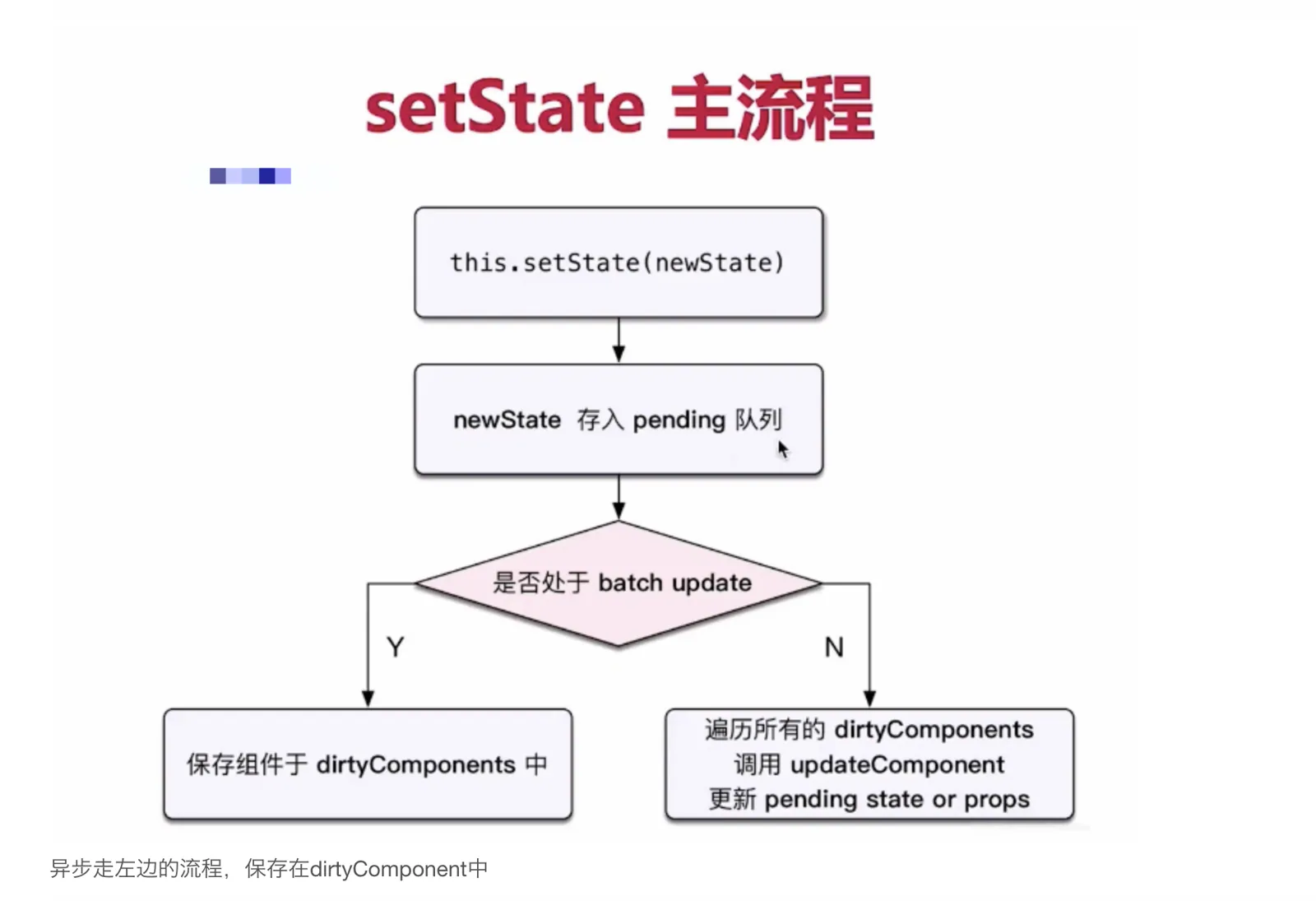
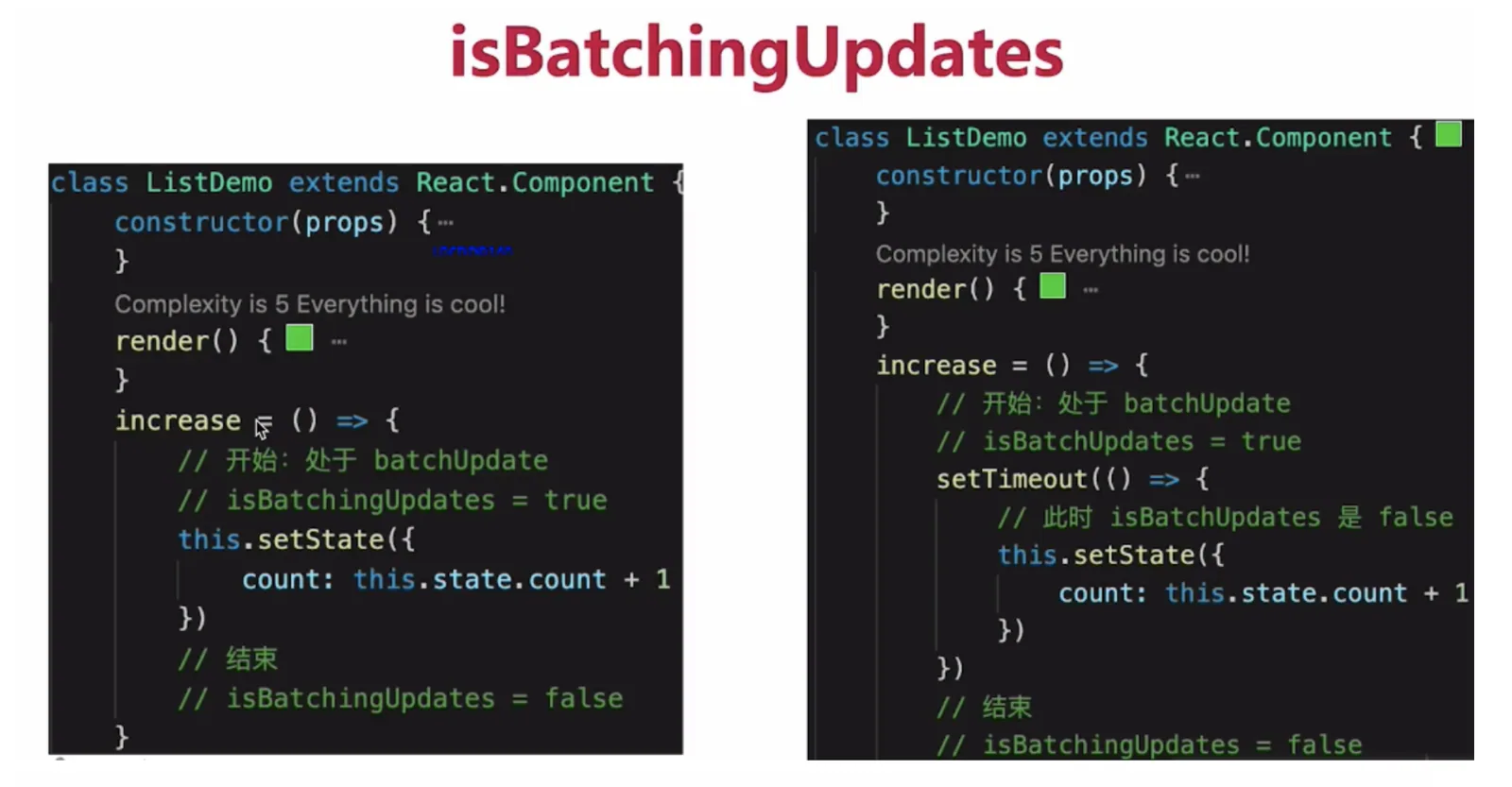
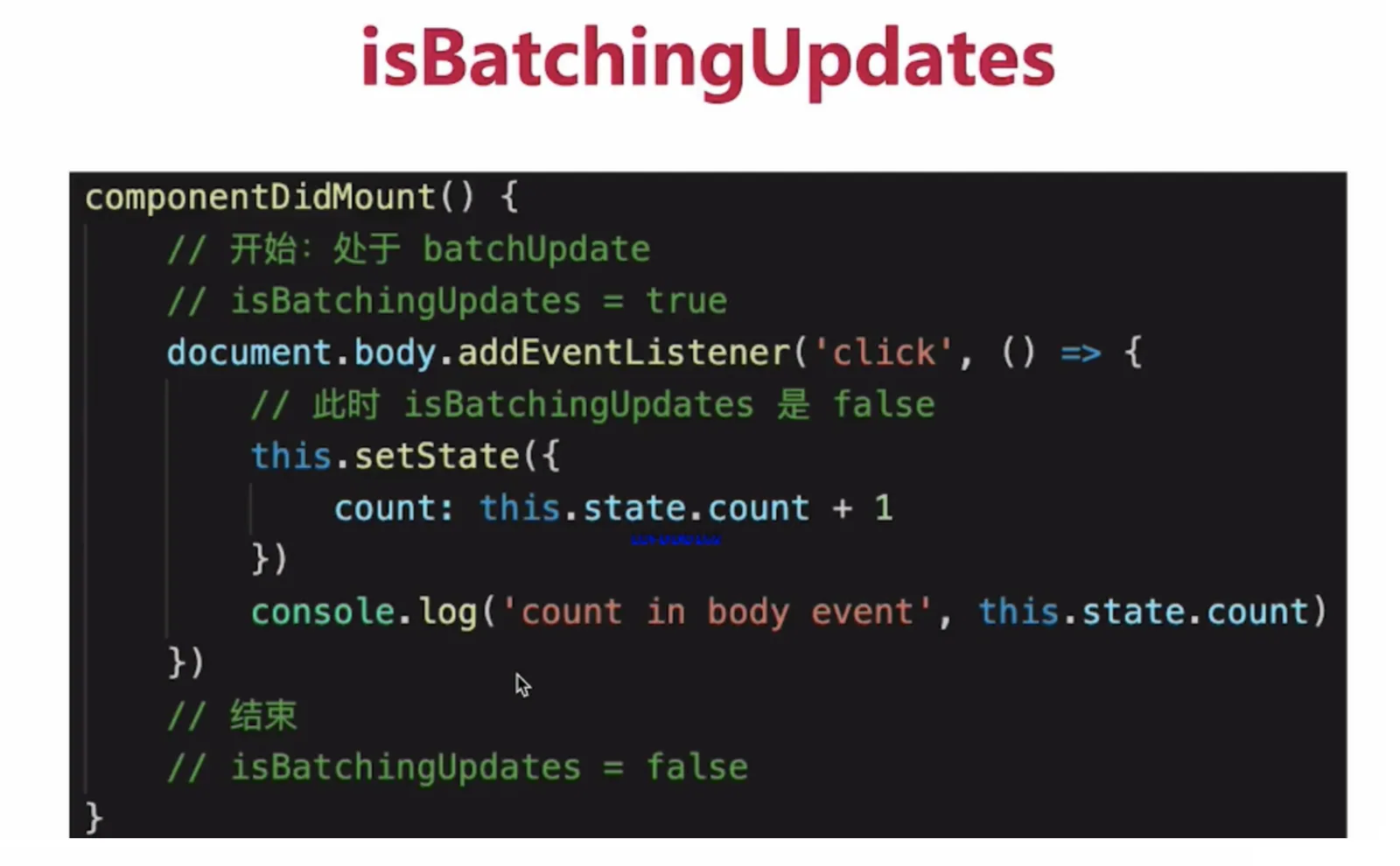
1.1 setState批量更新的过程
在
react生命周期和合成事件执行前后都有相应的钩子,分别是pre钩子和post钩子,pre钩子会调用batchedUpdate方法将isBatchingUpdates变量置为true,开启批量更新,而post钩子会将isBatchingUpdates置为false
isBatchingUpdates变量置为true,则会走批量更新分支,setState的更新会被存入队列中,待同步代码执行完后,再执行队列中的state更新。isBatchingUpdates为true,则把当前组件(即调用了setState的组件)放入dirtyComponents数组中;否则batchUpdate所有队列中的更新- 而在原生事件和异步操作中,不会执行
pre钩子,或者生命周期的中的异步操作之前执行了pre钩子,但是pos钩子也在异步操作之前执行完了,isBatchingUpdates必定为false,也就不会进行批量更新
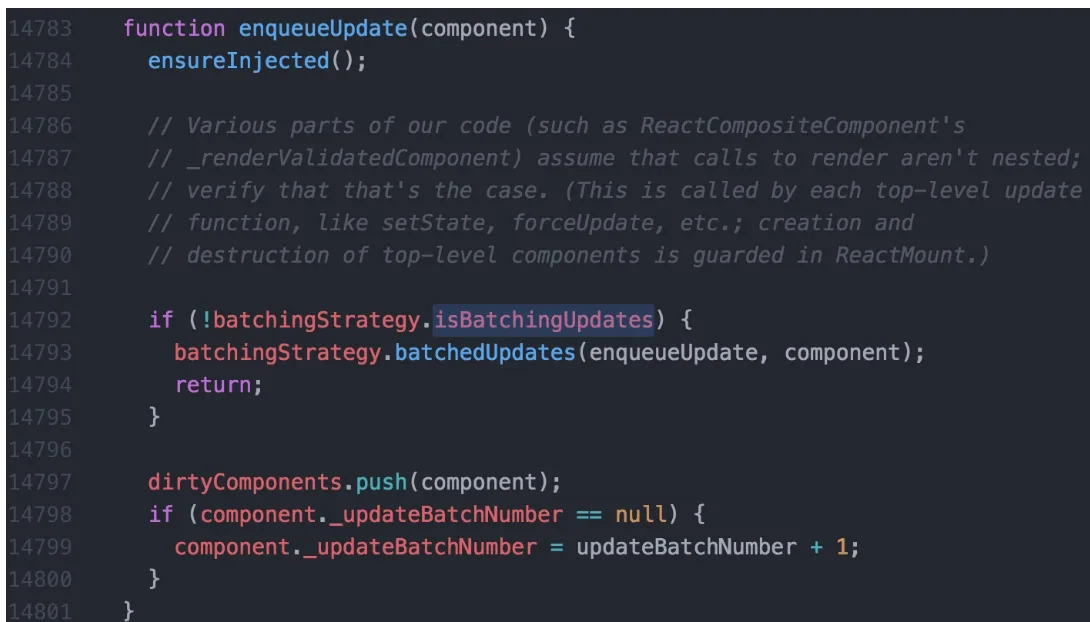
enqueueUpdate包含了React避免重复render的逻辑。mountComponent和updateComponent方法在执行的最开始,会调用到batchedUpdates进行批处理更新,此时会将isBatchingUpdates设置为true,也就是将状态标记为现在正处于更新阶段了。isBatchingUpdates为true,则把当前组件(即调用了setState的组件)放入dirtyComponents数组中;否则batchUpdate所有队列中的更新
1.2 为什么直接修改this.state无效
- 要知道
setState本质是通过一个队列机制实现state更新的。 执行setState时,会将需要更新的state合并后放入状态队列,而不会立刻更新state,队列机制可以批量更新state。 - 如果不通过
setState而直接修改this.state,那么这个state不会放入状态队列中,下次调用setState时对状态队列进行合并时,会忽略之前直接被修改的state,这样我们就无法合并了,而且实际也没有把你想要的state更新上去
1.3 什么是批量更新 Batch Update
在一些
mv*框架中,,就是将一段时间内对model的修改批量更新到view的机制。比如那前端比较火的React、vue(nextTick机制,视图的更新以及实现)
1.4 setState之后发生的事情
setState操作并不保证是同步的,也可以认为是异步的React在setState之后,会经对state进行diff,判断是否有改变,然后去diff dom决定是否要更新UI。如果这一系列过程立刻发生在每一个setState之后,就可能会有性能问题- 在短时间内频繁
setState。React会将state的改变压入栈中,在合适的时机,批量更新state和视图,达到提高性能的效果
1.5 如何知道state已经被更新
传入回调函数
setState({
index: 1
}}, function(){
console.log(this.state.index);
})
在钩子函数中体现
componentDidUpdate(){
console.log(this.state.index);
}
2. setState循环调用风险
- 当调用
setState时,实际上会执行enqueueSetState方法,并对partialState以及_pending-StateQueue更新队列进行合并操作,最终通过enqueueUpdate执行state更新 - 而
performUpdateIfNecessary方法会获取_pendingElement,_pendingStateQueue,_pending-ForceUpdate,并调用receiveComponent和updateComponent方法进行组件更新 - 如果在
shouldComponentUpdate或者componentWillUpdate方法中调用setState,此时this._pending-StateQueue != null,就会造成循环调用,使得浏览器内存占满后崩溃
3 事务
- 事务就是将需要执行的方法使用
wrapper封装起来,再通过事务提供的perform方法执行,先执行wrapper中的initialize方法,执行完perform之后,在执行所有的close方法,一组initialize及close方法称为一个wrapper。 - 那么事务和
setState方法的不同表现有什么关系,首先我们把4次setState简单归类,前两次属于一类,因为它们在同一调用栈中执行,setTimeout中的两次setState属于另一类 - 在
setState调用之前,已经处在batchedUpdates执行的事务中了。那么这次batchedUpdates方法是谁调用的呢,原来是ReactMount.js中的_renderNewRootComponent方法。也就是说,整个将React组件渲染到DOM中的过程就是处于一个大的事务中。而在componentDidMount中调用setState时,batchingStrategy的isBatchingUpdates已经被设为了true,所以两次setState的结果没有立即生效 - 再反观
setTimeout中的两次setState,因为没有前置的batchedUpdates调用,所以导致了新的state马上生效
4. 总结
- 通过
setState去更新this.state,不要直接操作this.state,请把它当成不可变的 - 调用
setState更新this.state不是马上生效的,它是异步的,所以不要天真以为执行完setState后this.state就是最新的值了 - 多个顺序执行的
setState不是同步地一个一个执行滴,会一个一个加入队列,然后最后一起执行,即批处理
8 React事务机制
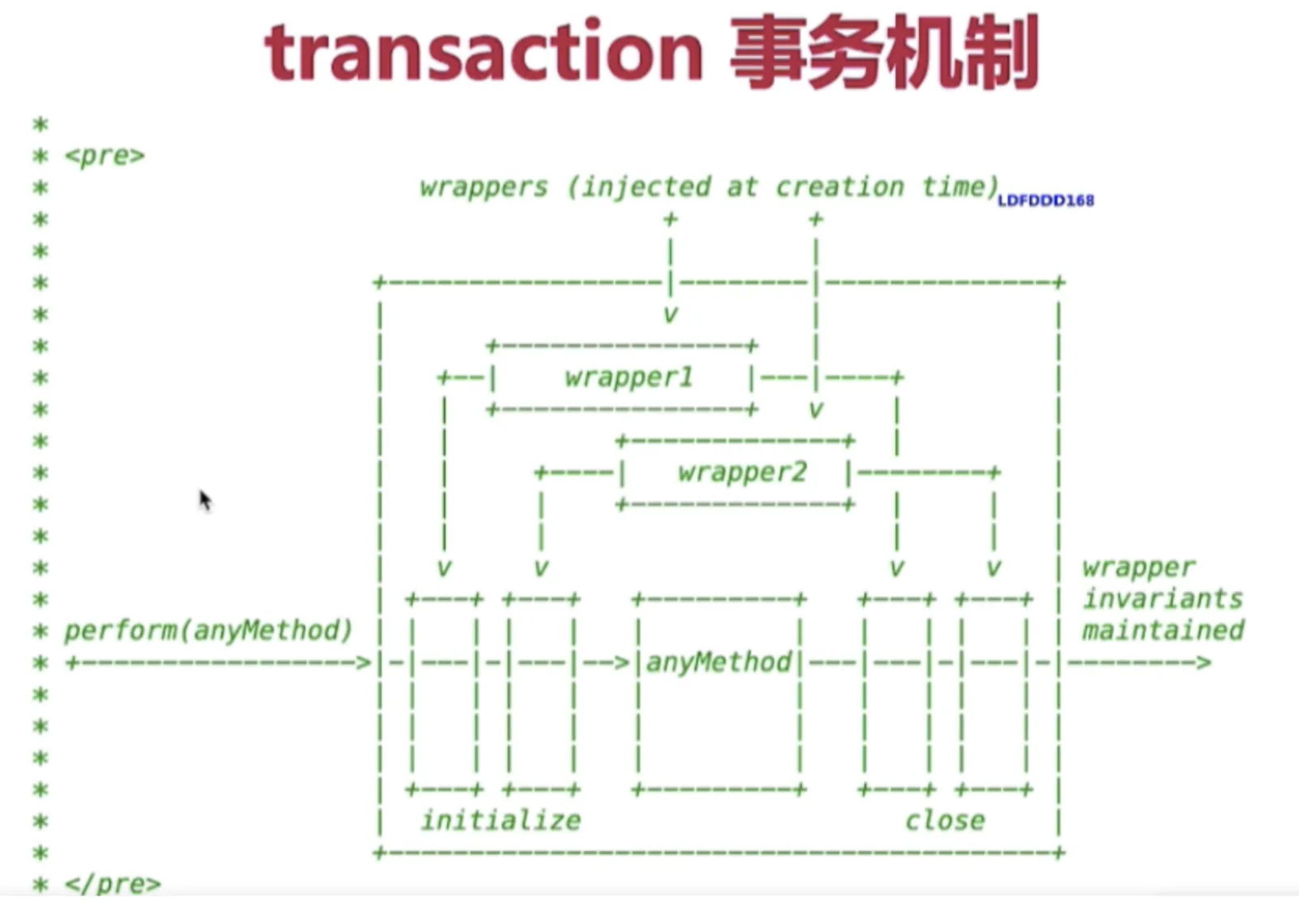

9 React组件和渲染更新过程
渲染和更新过程
- jsx如何渲染为页面
- setState之后如何更新页面
- 面试考察全流程
JSX本质和vdom
- JSX即
createElement函数 - 执行生成vnode
patch(elem,vnode)和patch(vnode,newNode)
组件渲染过程
props staterender()生成vnodepatch(elem, vnode)
组件更新过程
setState-->dirtyComponents(可能有子组件)render生成newVnodepatch(vnode, newVnode)
10 如何解释 React 的渲染流程
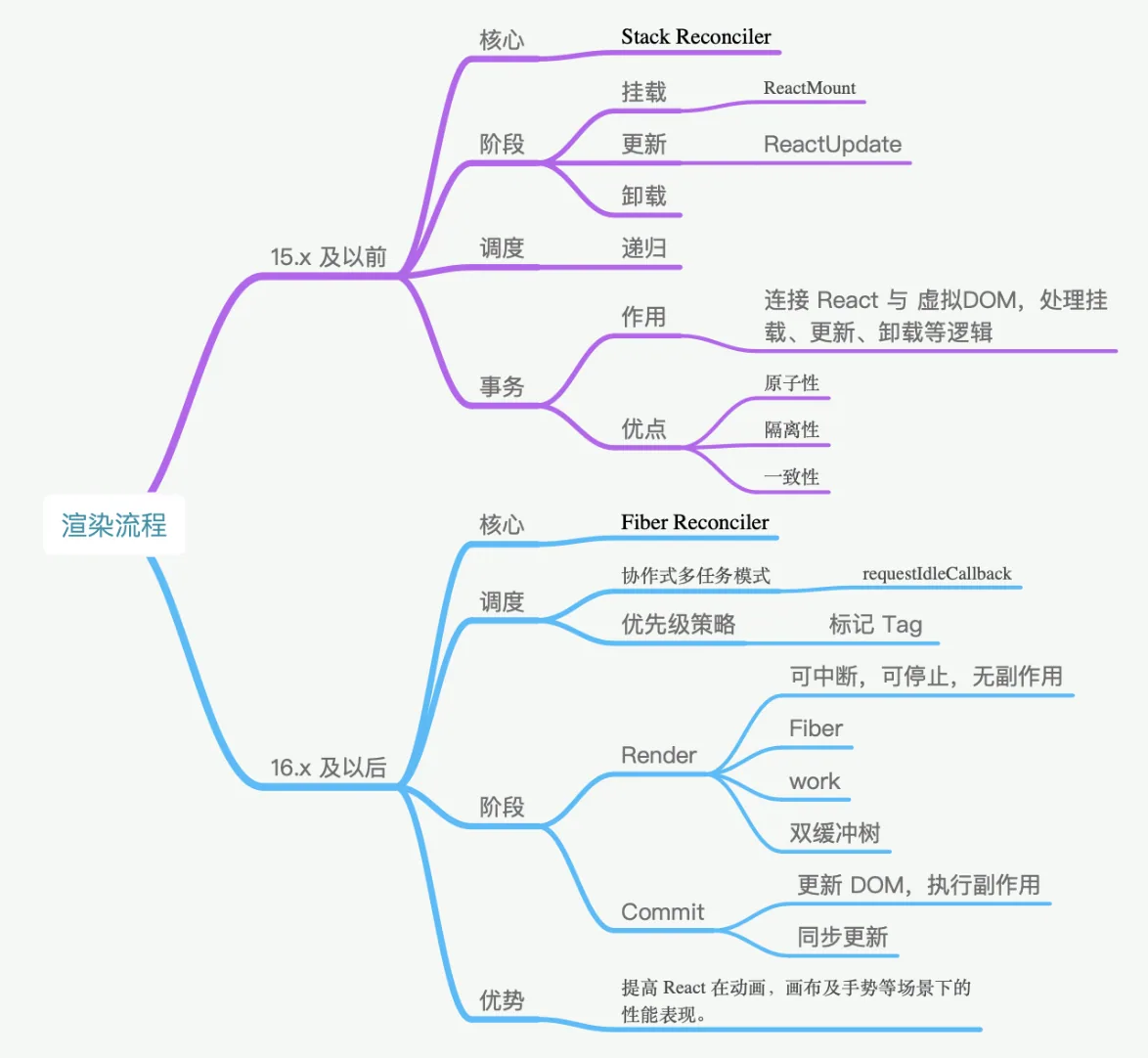
- React 的渲染过程大致一致,但协调并不相同,以
React 16为分界线,分为Stack Reconciler和Fiber Reconciler。这里的协调从狭义上来讲,特指 React 的 diff 算法,广义上来讲,有时候也指 React 的reconciler模块,它通常包含了diff算法和一些公共逻辑。 - 回到
Stack Reconciler中,Stack Reconciler的核心调度方式是递归。调度的基本处理单位是事务,它的事务基类是Transaction,这里的事务是 React 团队从后端开发中加入的概念。在 React 16 以前,挂载主要通过 ReactMount 模块完成,更新通过ReactUpdate模块完成,模块之间相互分离,落脚执行点也是事务。 - 在
React 16及以后,协调改为了Fiber Reconciler。它的调度方式主要有两个特点,第一个是协作式多任务模式,在这个模式下,线程会定时放弃自己的运行权利,交还给主线程,通过requestIdleCallback实现。第二个特点是策略优先级,调度任务通过标记tag的方式分优先级执行,比如动画,或者标记为high的任务可以优先执行。Fiber Reconciler的基本单位是Fiber,Fiber基于过去的React Element提供了二次封装,提供了指向父、子、兄弟节点的引用,为diff工作的双链表实现提供了基础。 - 在新的架构下,整个生命周期被划分为
Render 和 Commit 两个阶段。Render 阶段的执行特点是可中断、可停止、无副作用,主要是通过构造workInProgress树计算出diff。以current树为基础,将每个Fiber作为一个基本单位,自下而上逐个节点检查并构造 workInProgress 树。这个过程不再是递归,而是基于循环来完成 - 在执行上通过
requestIdleCallback来调度执行每组任务,每组中的每个计算任务被称为work,每个work完成后确认是否有优先级更高的work需要插入,如果有就让位,没有就继续。优先级通常是标记为动画或者high的会先处理。每完成一组后,将调度权交回主线程,直到下一次requestIdleCallback调用,再继续构建workInProgress树 - 在
commit阶段需要处理effect列表,这里的effect列表包含了根据diff 更新 DOM 树、回调生命周期、响应 ref等。 - 但一定要注意,这个阶段是同步执行的,不可中断暂停,所以不要在
componentDidMount、componentDidUpdate、componentWiilUnmount中去执行重度消耗算力的任务 - 如果只是一般的应用场景,比如管理后台、H5 展示页等,两者性能差距并不大,但在动画、画布及手势等场景下,
Stack Reconciler的设计会占用占主线程,造成卡顿,而fiber reconciler的设计则能带来高性能的表现
11 diff算法是怎么运作
每一种节点类型有自己的属性,也就是prop,每次进行diff的时候,react会先比较该节点类型,假如节点类型不一样,那么react会直接删除该节点,然后直接创建新的节点插入到其中,假如节点类型一样,那么会比较prop是否有更新,假如有prop不一样,那么react会判定该节点有更新,那么重渲染该节点,然后在对其子节点进行比较,一层一层往下,直到没有子节点
- 把树形结构按照层级分解,只比较同级元素。
- 给列表结构的每个单元添加唯一的
key属性,方便比较。 React只会匹配相同class的component(这里面的class指的是组件的名字)- 合并操作,调用
component的setState方法的时候,React将其标记为 -dirty.到每一个事件循环结束,React检查所有标记dirty的component重新绘制. - 选择性子树渲染。开发人员可以重写
shouldComponentUpdate提高diff的性能
优化⬇️
为了降低算法复杂度,
React的diff会预设三个限制:
- 只对同级元素进行
Diff。如果一个DOM节点在前后两次更新中跨越了层级,那么React不会尝试复用他。 - 两个不同类型的元素会产生出不同的树。如果元素由
div变为p,React会销毁div及其子孙节点,并新建p及其子孙节点。 - 开发者可以通过
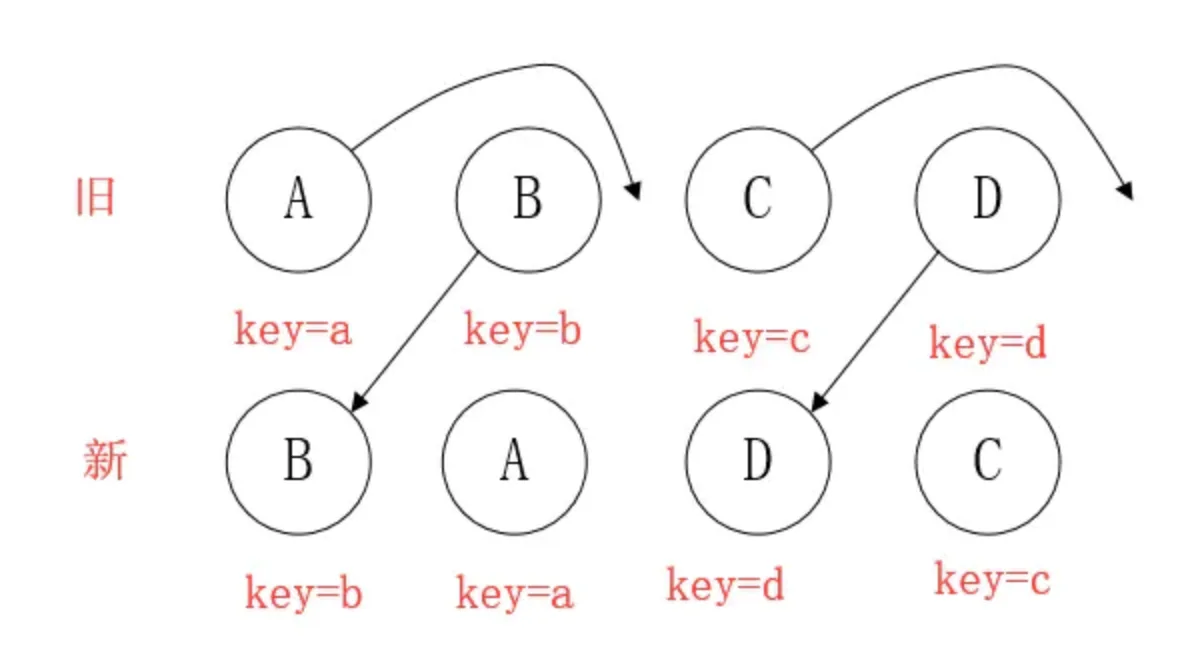
key prop来暗示哪些子元素在不同的渲染下能保持稳定。考虑如下例子:
Diff的思路
该如何设计算法呢?如果让我设计一个Diff算法,我首先想到的方案是:
- 判断当前节点的更新属于哪种情况
- 如果是
新增,执行新增逻辑 - 如果是
删除,执行删除逻辑 - 如果是
更新,执行更新逻辑
- 按这个方案,其实有个隐含的前提——不同操作的优先级是相同的
- 但是
React团队发现,在日常开发中,相较于新增和删除,更新组件发生的频率更高。所以Diff会优先判断当前节点是否属于更新。
基于以上原因,Diff算法的整体逻辑会经历两轮遍历:
- 第一轮遍历:处理
更新的节点。 - 第二轮遍历:处理剩下的不属于
更新的节点。
diff算法的作用
计算出Virtual DOM中真正变化的部分,并只针对该部分进行原生DOM操作,而非重新渲染整个页面。
传统diff算法
通过循环递归对节点进行依次对比,算法复杂度达到
O(n^3),n是树的节点数,这个有多可怕呢?——如果要展示1000个节点,得执行上亿次比较。。即便是CPU快能执行30亿条命令,也很难在一秒内计算出差异。
React的diff算法
- 什么是调和?
将Virtual DOM树转换成actual DOM树的最少操作的过程 称为 调和 。
- 什么是React diff算法?
diff算法是调和的具体实现。
diff策略
React用 三大策略 将O(n^3)复杂度 转化为 O(n)复杂度
策略一(tree diff):
- Web UI中DOM节点跨层级的移动操作特别少,可以忽略不计。
策略二(component diff):
- 拥有相同类的两个组件 生成相似的树形结构,
- 拥有不同类的两个组件 生成不同的树形结构。
策略三(element diff):
对于同一层级的一组子节点,通过唯一id区分。
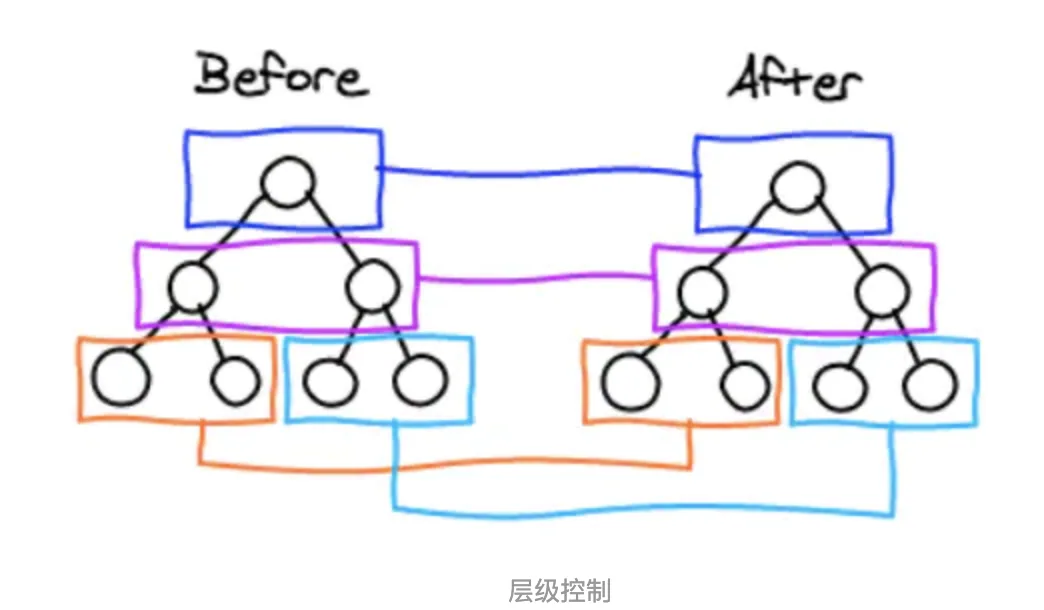
tree diff
- React通过updateDepth对Virtual DOM树进行层级控制。
- 对树分层比较,两棵树 只对同一层次节点 进行比较。如果该节点不存在时,则该节点及其子节点会被完全删除,不会再进一步比较。
- 只需遍历一次,就能完成整棵DOM树的比较。
那么问题来了,如果DOM节点出现了跨层级操作,diff会咋办呢?
答:diff只简单考虑同层级的节点位置变换,如果是跨层级的话,只有创建节点和删除节点的操作。
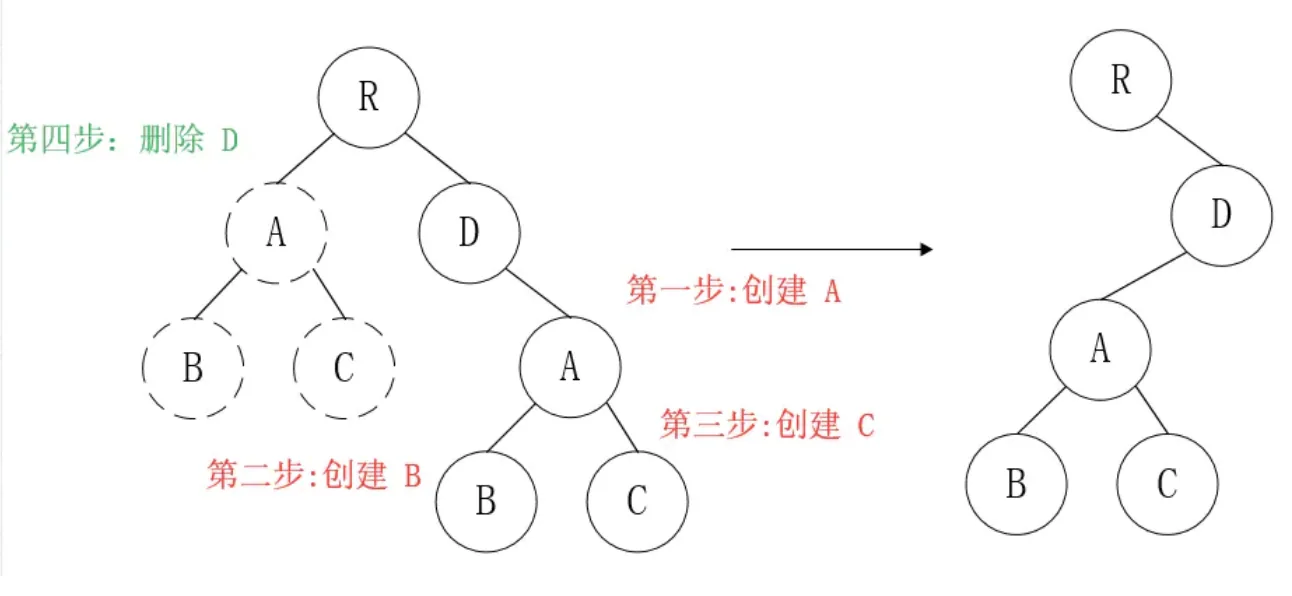
如上图所示,以A为根节点的整棵树会被重新创建,而不是移动,因此 官方建议不要进行DOM节点跨层级操作,可以通过CSS隐藏、显示节点,而不是真正地移除、添加DOM节点
component diff
React对不同的组件间的比较,有三种策略
- 同一类型的两个组件,按原策略(层级比较)继续比较Virtual DOM树即可。
- 同一类型的两个组件,组件A变化为组件B时,可能Virtual DOM没有任何变化,如果知道这点(变换的过程中,Virtual DOM没有改变),可节省大量计算时间,所以 用户 可以通过
shouldComponentUpdate()来判断是否需要 判断计算。 - 不同类型的组件,将一个(将被改变的)组件判断为
dirty component(脏组件),从而替换 整个组件的所有节点。
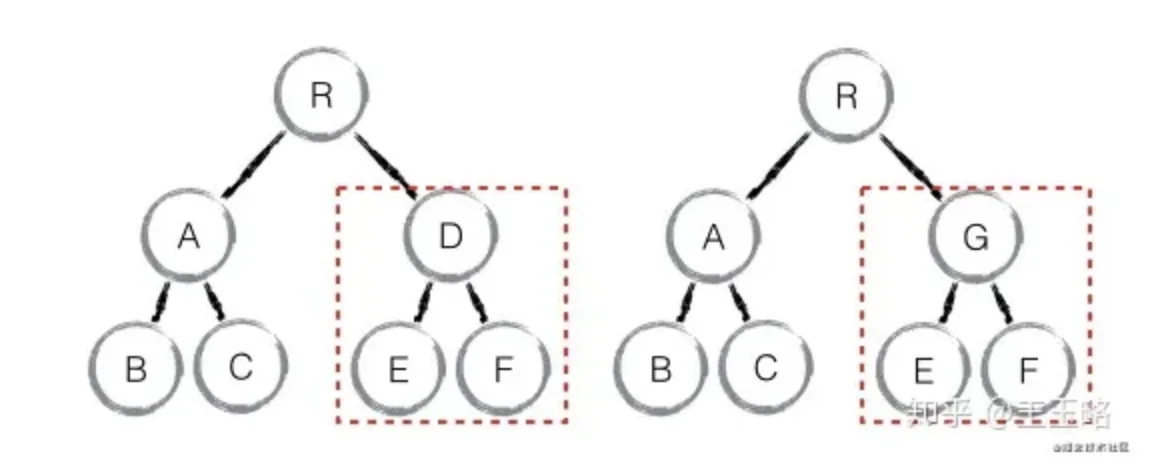
注意:如果组件D和组件G的结构相似,但是 React判断是 不同类型的组件,则不会比较其结构,而是删除 组件D及其子节点,创建组件G及其子节点。
element diff
当节点处于同一层级时,diff提供三种节点操作:删除、插入、移动。
- 插入:组件 C 不在集合(A,B)中,需要插入
- 删除:
- 组件 D 在集合(A,B,D)中,但 D的节点已经更改,不能复用和更新,所以需要删除 旧的 D ,再创建新的。
- 组件 D 之前在 集合(A,B,D)中,但集合变成新的集合(A,B)了,D 就需要被删除。
- 移动:组件D已经在集合(A,B,C,D)里了,且集合更新时,D没有发生更新,只是位置改变,如新集合(A,D,B,C),D在第二个,无须像传统diff,让旧集合的第二个B和新集合的第二个D 比较,并且删除第二个位置的B,再在第二个位置插入D,而是 (对同一层级的同组子节点) 添加唯一key进行区分,移动即��。
总结
tree diff:只对比同一层的 dom 节点,忽略 dom 节点的跨层级移动
如下图,react 只会对相同颜色方框内的 DOM 节点进行比较,即同一个父节点下的所有子节点。当发现节点不存在时,则该节点及其子节点会被完全删除掉,不会用于进一步的比较。
这样只需要对树进行一次遍历,便能完成整个 DOM 树的比较。
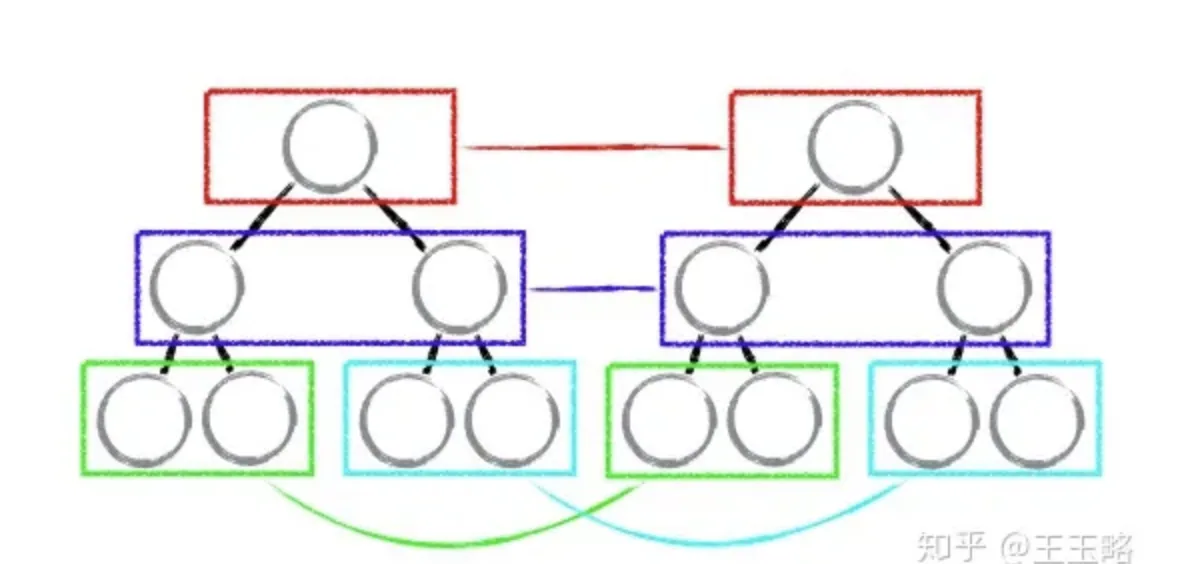
这就意味着,如果 dom 节点发生了跨层级移动,react 会删除旧的节点,生成新的节点,而不会复用。
component diff:如果不是同一类型的组件,会删除旧的组件,创建新的组件
element diff:对于同一层级的一组子节点,需要通过唯一 id 进行来区分
- 如果没有 id 来进行区分,一旦有插入动作,会导致插入位置之后的列表全部重新渲染
- 这也是为什么渲染列表时为什么要使用唯一的 key。
diff的不足与待优化的地方
尽量减少类似将最后一个节点移动到列表首部的操作,当节点数量过大或更新操作过于频繁时,会影响React的渲染性能
与其他框架相比,React 的 diff 算法有何不同?
diff 算法探讨的就是虚拟 DOM 树发生变化后,生成 DOM 树更新补丁的方式。它通过对比新旧两株虚拟 DOM 树的变更差异,将更新补丁作用于真实 DOM,以最小成本完成视图更新
具体的流程是这样的:
- 真实 DOM 与虚拟 DOM 之间存在一个映射关系。这个映射关系依靠初始化时的 JSX 建立完成;
- 当虚拟 DOM 发生变化后,就会根据差距计算生成 patch,这个 patch 是一个结构化的数据,内容包含了增加、更新、移除等;
- 最后再根据 patch 去更新真实的 DOM,反馈到用户的界面上。
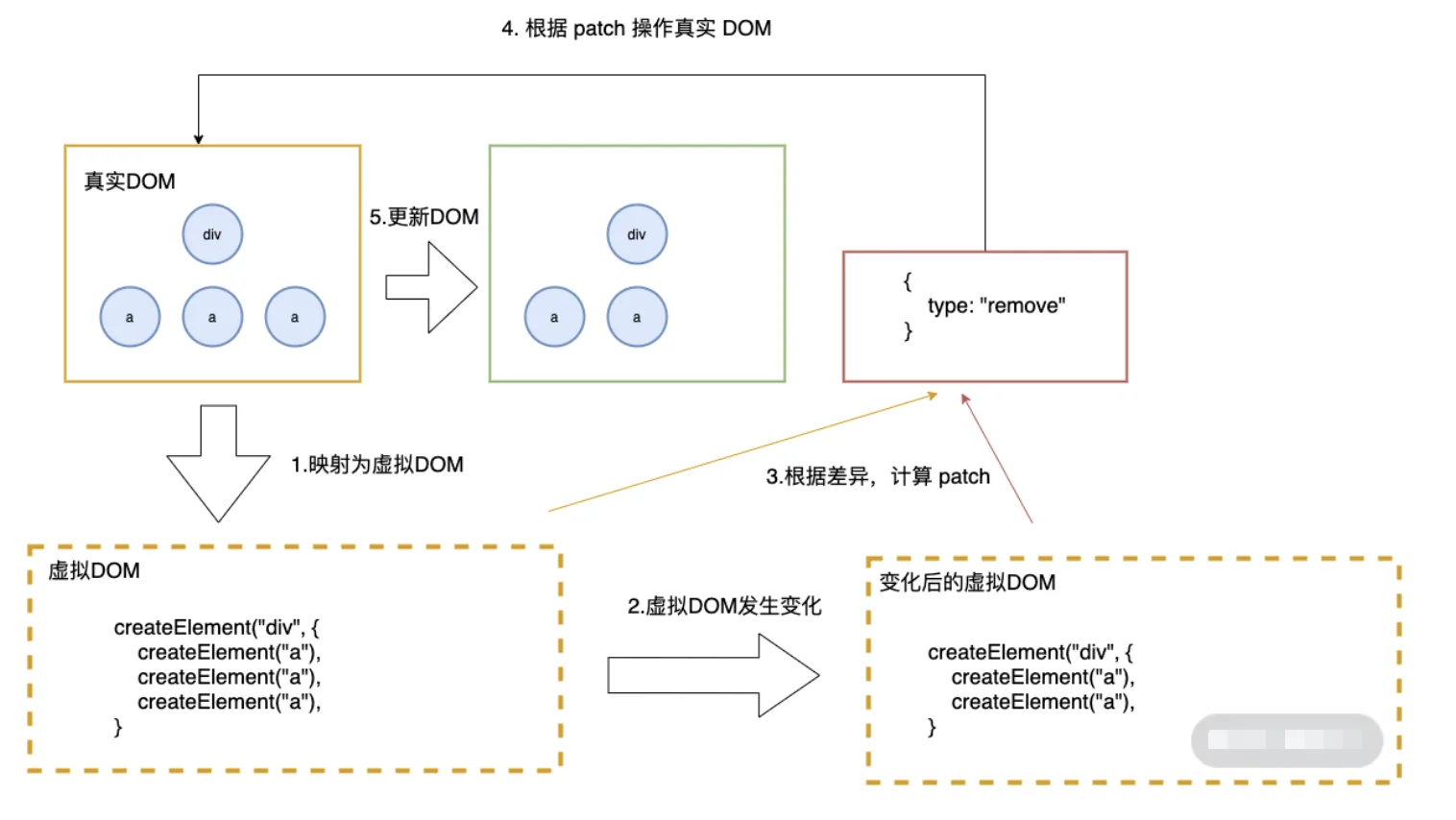
在回答有何不同之前,首先需要说明下什么是 diff 算法。
diff 算法是指生成更新补丁的方式,主要应用于虚拟 DOM 树变化后,更新真实 DOM。所以 diff 算法一定存在这样一个过程:触发更新 → 生成补丁 → 应用补丁- React 的 diff 算法,触发更新的时机主要在 state 变化与 hooks 调用之后。此时触发虚拟 DOM 树变更遍历,采用了深度优先遍历算法。但传统的遍历方式,效率较低。为了优化效率,使用了分治的方式。
将单一节点比对转化为了 3 种类型节点的比对,分别是树、组件及元素,以此提升效率。树比对:由于网页视图中较少有跨层级节点移动,两株虚拟 DOM 树只对同一层次的节点进行比较。组件比对:如果组件是同一类型,则进行树比对,如果不是,则直接放入到补丁中。元素比对:主要发生在同层级中,通过标记节点操作生成补丁,节点操作对应真实的 DOM 剪裁操作。同一层级的子节点,可以通过标记 key 的方式进行列表对比。
- 以上是经典的 React diff 算法内容。
自 React 16 起,引入了 Fiber 架构。为了使整个更新过程可随时暂停恢复,节点与树分别采用了FiberNode 与 FiberTree 进行重构。fiberNode 使用了双链表的结构,可以直接找到兄弟节点与子节点 - 然后拿 Vue 和 Preact 与 React 的 diff 算法进行对比
Preact的Diff算法相较于React,整体设计思路相似,但最底层的元素采用了真实DOM对比操作,也没有采用Fiber设计。Vue 的Diff算法整体也与React相似,同样未实现Fiber设计
- 然后进行横向比较,
React 拥有完整的 Diff 算法策略,且拥有随时中断更新的时间切片能力,在大批量节点更新的极端情况下,拥有更友好的交互体验。 - Preact 可以在一些对性能要求不高,仅需要渲染框架的简单场景下应用。
- Vue 的整体
diff 策略与 React 对齐,虽然缺乏时间切片能力,但这并不意味着 Vue 的性能更差,因为在 Vue 3 初期引入过,后期因为收益不高移除掉了。除了高帧率动画,在 Vue 中其他的场景几乎都可以使用防抖和节流去提高响应性能。
**学习原理的目的就是应用。那如何根据 React diff 算法原理优化代码呢?**这个问题其实按优化方式逆向回答即可。
- 根据
diff算法的设计原则,应尽量避免跨层级节点移动。 - 通过设置唯一
key进行优化,尽量减少组件层级深度。因为过深的层级会加深遍历深度,带来性能问题。 - 设置
shouldComponentUpdate或者React.pureComponet减少diff次数。
12 合成事件原理
为了解决跨浏览器兼容性问题,
React会将浏览器原生事件(Browser Native Event)封装为合成事件(SyntheticEvent)传入设置的事件处理器中。这里的合成事件提供了与原生事件相同的接口,不过它们屏蔽了底层浏览器的细节差异,保证了行为的一致性。另外有意思的是,React并没有直接将事件附着到子元素上,而是以单一事件监听器的方式将所有的事件发送到顶层进行处理。这样React在更新DOM的时候就不需要考虑如何去处理附着在DOM上的事件监听器,最终达到优化性能的目的
- 所有的事件挂在document上,DOM 事件触发后冒泡到 document;React 找到对应的组件,造出一个合成事件出来;并按组件树模拟一遍事件冒泡。
- event不是原生的,是SyntheticEvent合成事件对象
- 和Vue事件不同,和DOM事件也不同
React 17 之前的事件冒泡流程图
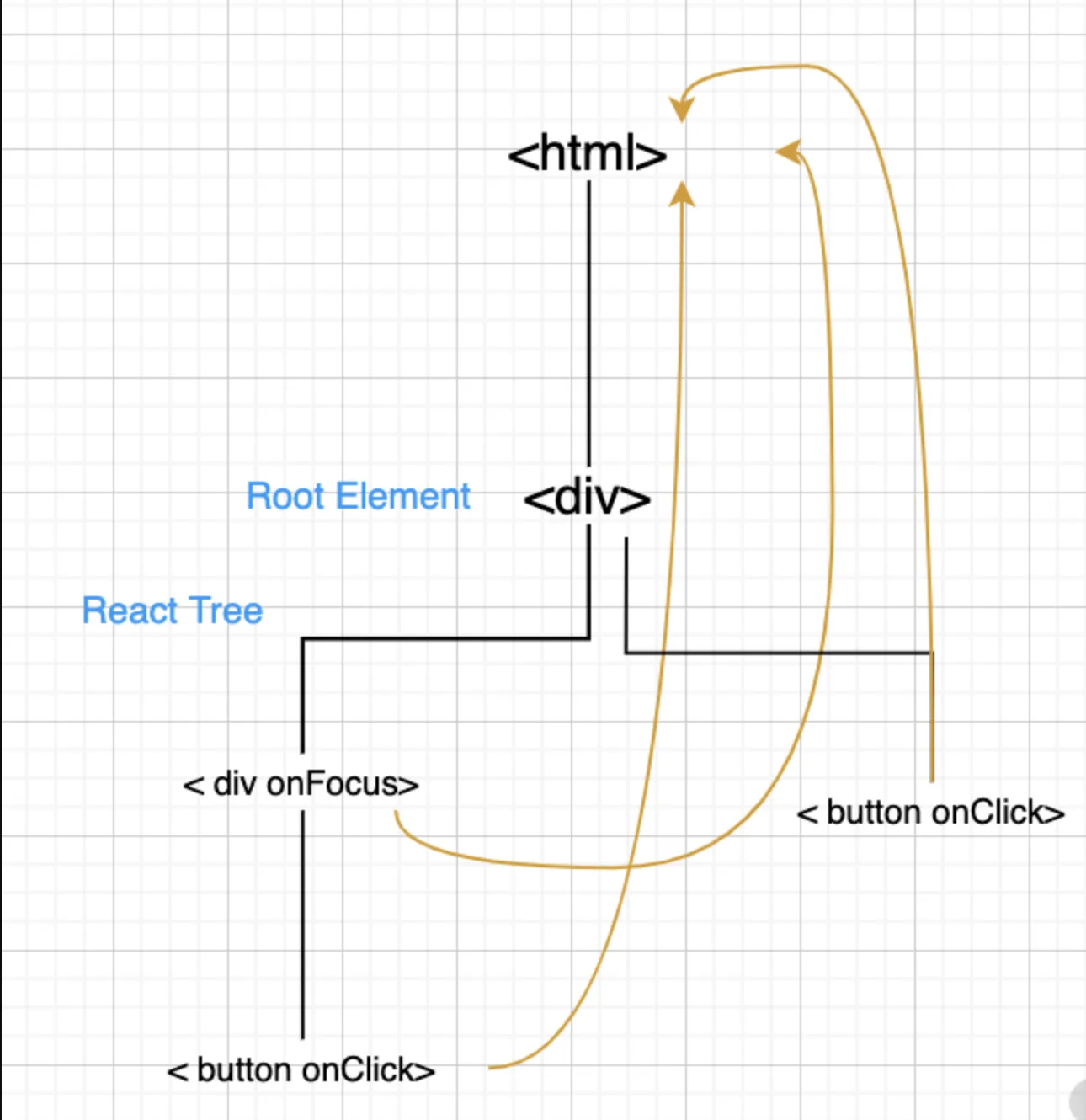
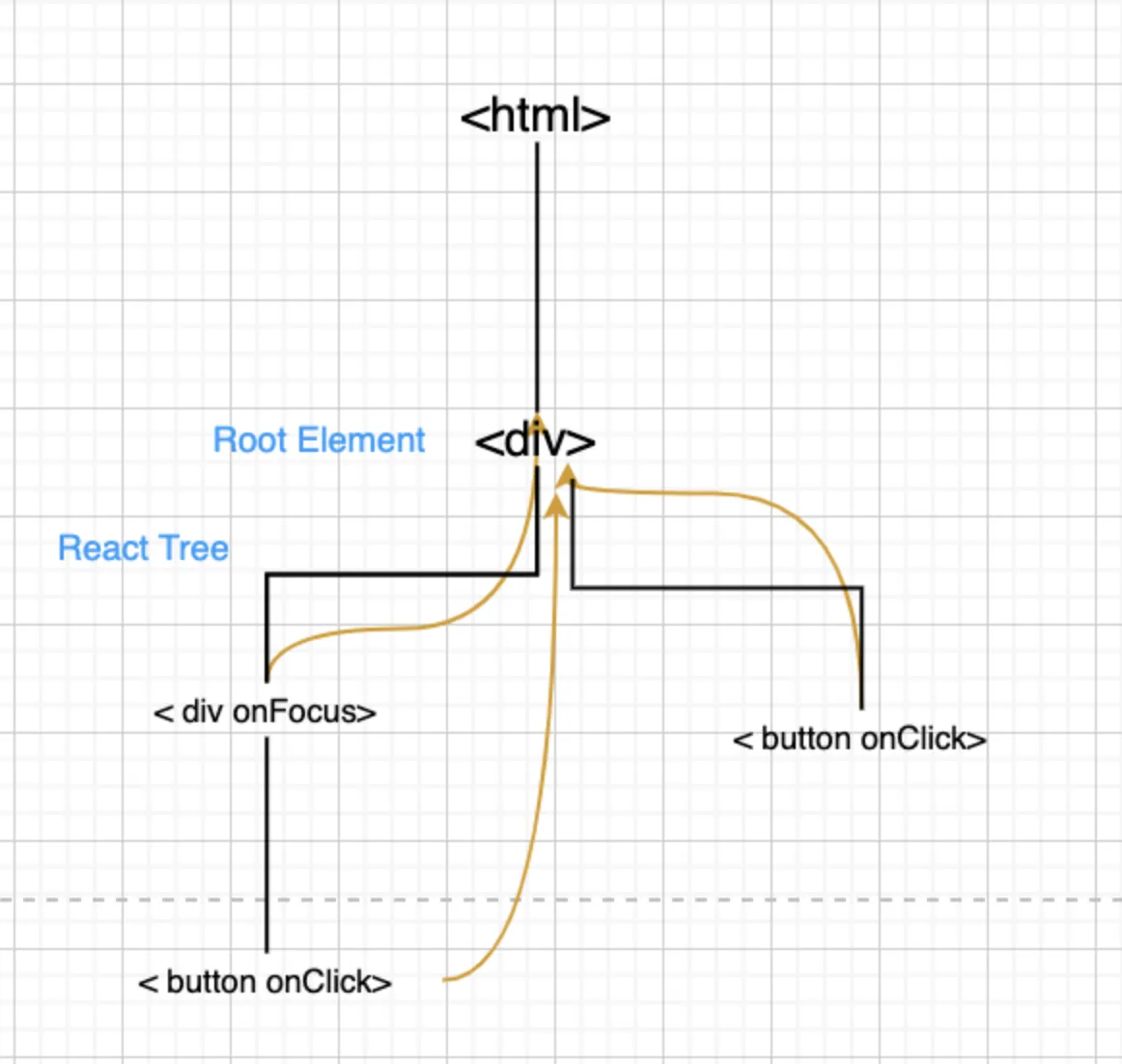
所以这就造成了,在一个页面中,只能有一个版本的 React。如果有多个版本,事件就乱套了。值得一提的是,这个问题在 React 17 中得到了解决,事件委托不再挂在 document 上,而是挂在 DOM 容器上,也就是
ReactDom.Render所调用的节点上。
React 17 后的事件冒泡流程图
那到底哪些事件会被捕获生成合成事件呢?可以从 React 的源码测试文件中一探究竟。下面的测试快照中罗列了大量的事件名,也只有在这份快照中的事件,才会被捕获生成合成事件。
// react/packages/react-dom/src/__tests__/__snapshots__/ReactTestUtils-test.js.snap
Array [
"abort",
"animationEnd",
"animationIteration",
"animationStart",
"auxClick",
"beforeInput",
"blur",
"canPlay",
"canPlayThrough",
"cancel",
"change",
"click",
"close",
"compositionEnd",
"compositionStart",
"compositionUpdate",
"contextMenu",
"copy",
"cut",
"doubleClick",
"drag",
"dragEnd",
"dragEnter",
"dragExit",
"dragLeave",
"dragOver",
"dragStart",
"drop",
"durationChange",
"emptied",
"encrypted",
"ended",
"error",
"focus",
"gotPointerCapture",
"input",
"invalid",
"keyDown",
"keyPress",
"keyUp",
"load",
"loadStart",
"loadedData",
"loadedMetadata",
"lostPointerCapture",
"mouseDown",
"mouseEnter",
"mouseLeave",
"mouseMove",
"mouseOut",
"mouseOver",
"mouseUp",
"paste",
"pause",
"play",
"playing",
"pointerCancel",
"pointerDown",
"pointerEnter",
"pointerLeave",
"pointerMove",
"pointerOut",
"pointerOver",
"pointerUp",
"progress",
"rateChange",
"reset",
"scroll",
"seeked",
"seeking",
"select",
"stalled",
"submit",
"suspend",
"timeUpdate",
"toggle",
"touchCancel",
"touchEnd",
"touchMove",
"touchStart",
"transitionEnd",
"volumeChange",
"waiting",
"wheel",
]
如果DOM上绑定了过多的事件处理函数,整个页面响应以及内存占用可能都会受到影响。React为了避免这类DOM事件滥用,同时屏蔽底层不同浏览器之间的事件系统的差异,实现了一个中间层
- SyntheticEvent
- 当用户在为onClick添加函数时,React并没有将Click绑定到DOM上面
- 而是在document处监听所有支持的事件,当事件发生并冒泡至document处时,React将事件内容封装交给中间层 SyntheticEvent (负责所有事件合成)
- 所以当事件触发的时候, 对使用统一的分发函数 dispatchEvent 将指定函数执行
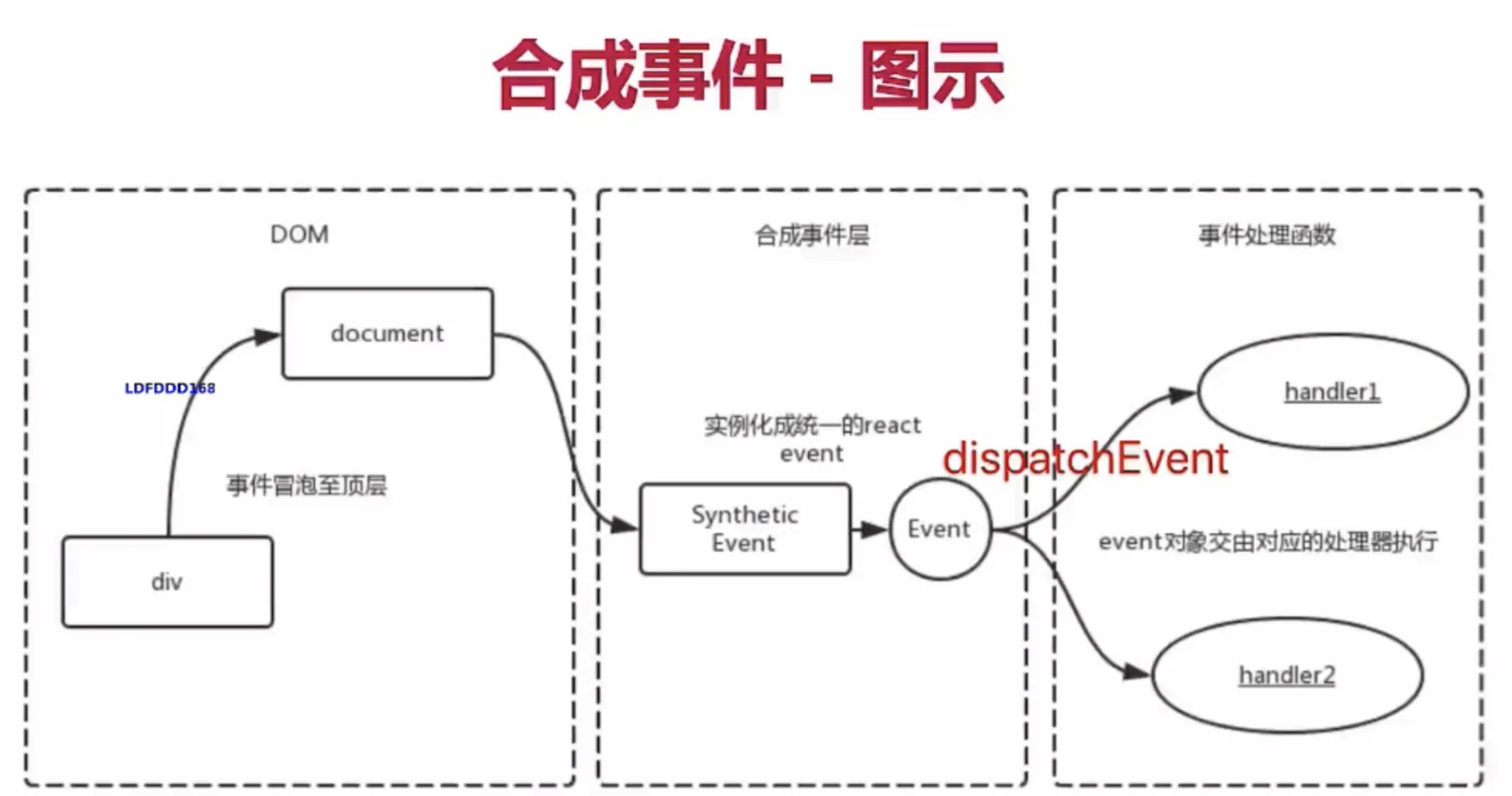
为何要合成事件
- 兼容性和跨平台
- 挂在统一的document上,减少内存消耗,避免频繁解绑
- 方便事件的统一管理(事务机制)
- dispatchEvent事件机制
13 JSX语法糖本质
JSX是语法糖,通过babel转成
React.createElement函数,在babel官网上可以在线把JSX转成React的JS语法
- 首先解析出来的话,就是一个
createElement函数 - 然后这个函数执行完后,会返回一个
vnode - 通过vdom的patch或者是其他的一个方法,最后渲染一个页面


script标签中不添加
text/babel解析jsx语法的情况下
<script>
const ele = React.createElement("h2", null, "Hello React!");
ReactDOM.render(ele, document.getElementById("app"));
</script>
JSX的本质是React.createElement()函数
createElement函数返回的对象是ReactEelement对象。
createElement的写法如下
class App extends React.Component {
constructor() {
super()
this.state = {}
}
render() {
return React.createElement("div", null,
/*第一个子元素,header*/
React.createElement("div", { className: "header" },
React.createElement("h1", { title: "\u6807\u9898" }, "\u6211\u662F\u6807\u9898")
),
/*第二个子元素,content*/
React.createElement("div", { className: "content" },
React.createElement("h2", null, "\u6211\u662F\u9875\u9762\u7684\u5185\u5BB9"),
React.createElement("button", null, "\u6309\u94AE"),
React.createElement("button", null, "+1"),
React.createElement("a", { href: "http://www.baidu.com" },
"\u767E\u5EA6\u4E00\u4E0B")
),
/*第三个子元素,footer*/
React.createElement("div", { className: "footer" },
React.createElement("p", null, "\u6211\u662F\u5C3E\u90E8\u7684\u5185\u5BB9")
)
);
}
}
ReactDOM.render(<App />, document.getElementById("app"));
实际开发中不会使用createElement来创建ReactElement的,一般都是使用JSX的形式开发。
ReactElement在程序中打印一下
render() {
let ele = (
<div>
<div className="header">
<h1 title="标题">我是标题</h1>
</div>
<div className="content">
<h2>我是页面的内容</h2>
<button>按钮</button>
<button>+1</button>
<a href="http://www.baidu.com">百度一下</a>
</div>
<div className="footer">
<p>我是尾部的内容</p>
</div>
</div>
)
console.log(ele);
return ele;
}
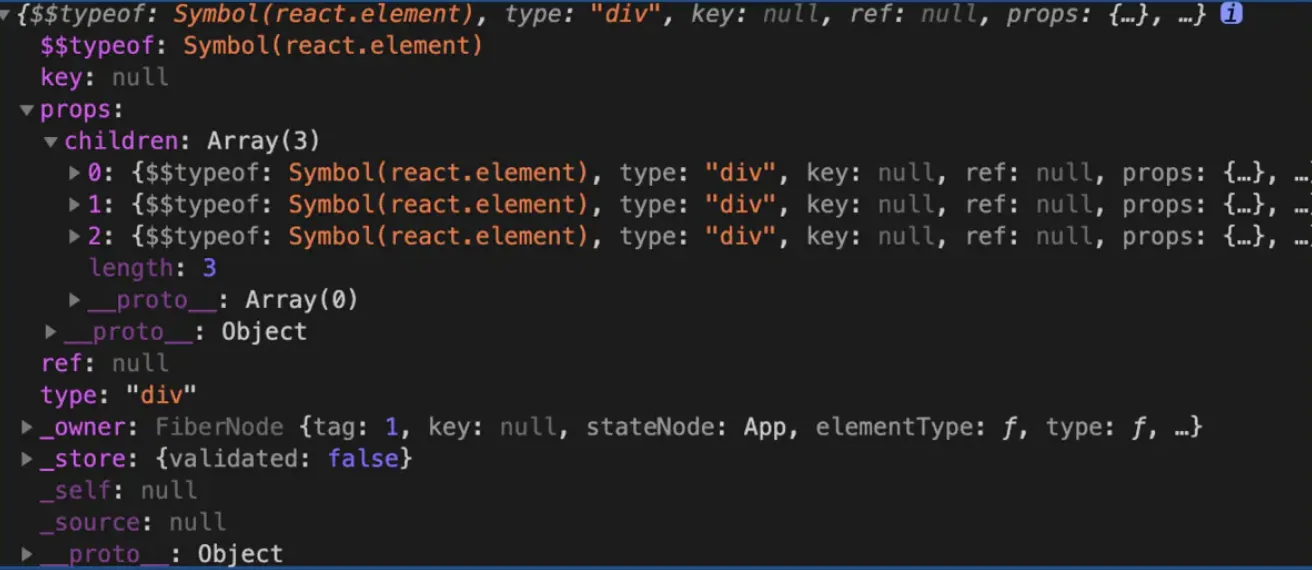
react通过babel把JSX转成
createElement函数,生成ReactElement对象,然后通过ReactDOM.render函数把ReactElement渲染成真实的DOM元素
为什么 React 使用 JSX
- 在回答问题之前,我首先解释下什么是 JSX 吧。JSX 是一个
JavaScript的语法扩展,结构类似 XML。 - JSX 主要用于声明
React元素,但 React 中并不强制使用JSX。即使使用了JSX,也会在构建过程中,通过 Babel 插件编译为React.createElement。所以 JSX 更像是React.createElement的一种语法糖 - 接下来与 JSX 以外的三种技术方案进行对比
- 首先是模板,React 团队认为模板不应该是开发过程中的关注点,因为引入了模板语法、模板指令等概念,是一种不佳的实现方案
- 其次是模板字符串,模板字符串编写的结构会造成多次内部嵌套,使整个结构变得复杂,并且优化代码提示也会变得困难重重
- 所以 React 最后选用了 JSX,因为 JSX 与其设计思想贴合,不需要引入过多新的概念,对编辑器的代码提示也极为友好。
Babel 插件如何实现 JSX 到 JS 的编译? 在 React 面试中,这个问题很容易被追问,也经常被要求手写。
它的实现原理是这样的。Babel 读取代码并解析,生成 AST,再将 AST 传入插件层进行转换,在转换时就可以将 JSX 的结构转换为 React.createElement 的函数。如下代码所示:
module.exports = function (babel) {
var t = babel.types;
return {
name: "custom-jsx-plugin",
visitor: {
JSXElement(path) {
var openingElement = path.node.openingElement;
var tagName = openingElement.name.name;
var args = [];
args.push(t.stringLiteral(tagName));
var attribs = t.nullLiteral();
args.push(attribs);
var reactIdentifier = t.identifier("React"); //object
var createElementIdentifier = t.identifier("createElement");
var callee = t.memberExpression(reactIdentifier, createElementIdentifier)
var callExpression = t.callExpression(callee, args);
callExpression.arguments = callExpression.arguments.concat(path.node.children);
path.replaceWith(callExpression, path.node);
},
},
};
};
React.createElement源码分析
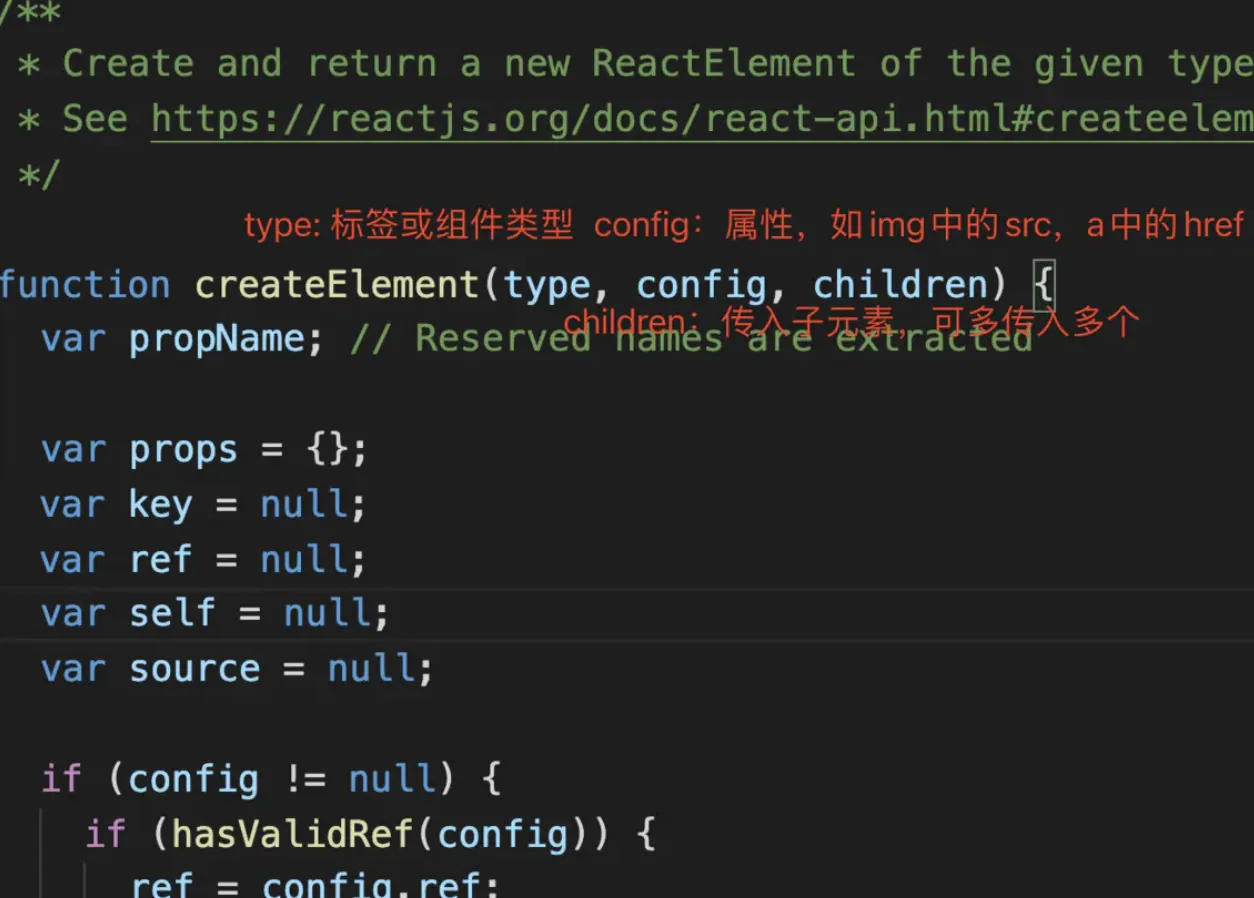
/**
101. React的创建元素方法
*/
export function createElement(type, config, children) {
// propName 变量用于储存后面需要用到的元素属性
let propName;
// props 变量用于储存元素属性的键值对集合
const props = {};
// key、ref、self、source 均为 React 元素的属性,此处不必深究
let key = null;
let ref = null;
let self = null;
let source = null;
// config 对象中存储的是元素的属性
if (config != null) {
// 进来之后做的第一件事,是依次对 ref、key、self 和 source 属性赋值
if (hasValidRef(config)) {
ref = config.ref;
}
// 此处将 key 值字符串化
if (hasValidKey(config)) {
key = '' + config.key;
}
self = config.__self === undefined ? null : config.__self;
source = config.__source === undefined ? null : config.__source;
// 接着就是要把 config 里面的属性都一个一个挪到 props 这个之前声明好的对象里面
for (propName in config) {
if (
// 筛选出可以提进 props 对象里的属性
hasOwnProperty.call(config, propName) &&
!RESERVED_PROPS.hasOwnProperty(propName)
) {
props[propName] = config[propName];
}
}
}
// childrenLength 指的是当前元素的子元素的个数,减去的 2 是 type 和 config 两个参数占用的长度
const childrenLength = arguments.length - 2;
// 如果抛去type和config,就只剩下一个参数,一般意味着文本节点出现了
if (childrenLength === 1) {
// 直接把这个参数的值赋给props.children
props.children = children;
// 处理嵌套多个子元素的情况
} else if (childrenLength > 1) {
// 声明一个子元素数组
const childArray = Array(childrenLength);
// 把子元素推进数组里
for (let i = 0; i < childrenLength; i++) {
childArray[i] = arguments[i + 2];
}
// 最后把这个数组赋值给props.children
props.children = childArray;
}
// 处理 defaultProps
if (type && type.defaultProps) {
const defaultProps = type.defaultProps;
for (propName in defaultProps) {
if (props[propName] === undefined) {
props[propName] = defaultProps[propName];
}
}
}
// 最后返回一个调用ReactElement执行方法,并传入刚才处理过的参数
return ReactElement(
type,
key,
ref,
self,
source,
ReactCurrentOwner.current,
props,
);
}
入参解读:创造一个元素需要知道哪些信息
export function createElement(type, config, children)
createElement 有 3 个入参,这 3 个入参囊括了 React 创建一个元素所需要知道的全部信息。
type:用于标识节点的类型。它可以是类似“h1”“div”这样的标准 HTML 标签字符串,也可以是 React 组件类型或React fragment类型。config:以对象形式传入,组件所有的属性都会以键值对的形式存储在 config 对象中。children:以对象形式传入,它记录的是组件标签之间嵌套的内容,也就是所谓的“子节点”“子元素”
React.createElement("ul", {
// 传入属性键值对
className: "list"
// 从第三个入参开始往后,传入的参数都是 children
}, React.createElement("li", {
key: "1"
}, "1"), React.createElement("li", {
key: "2"
}, "2"));
这个调用对应的 DOM 结构如下:
<ul className="list">
<li key="1">1</li>
<li key="2">2</li>
</ul>
createElement 函数体拆解
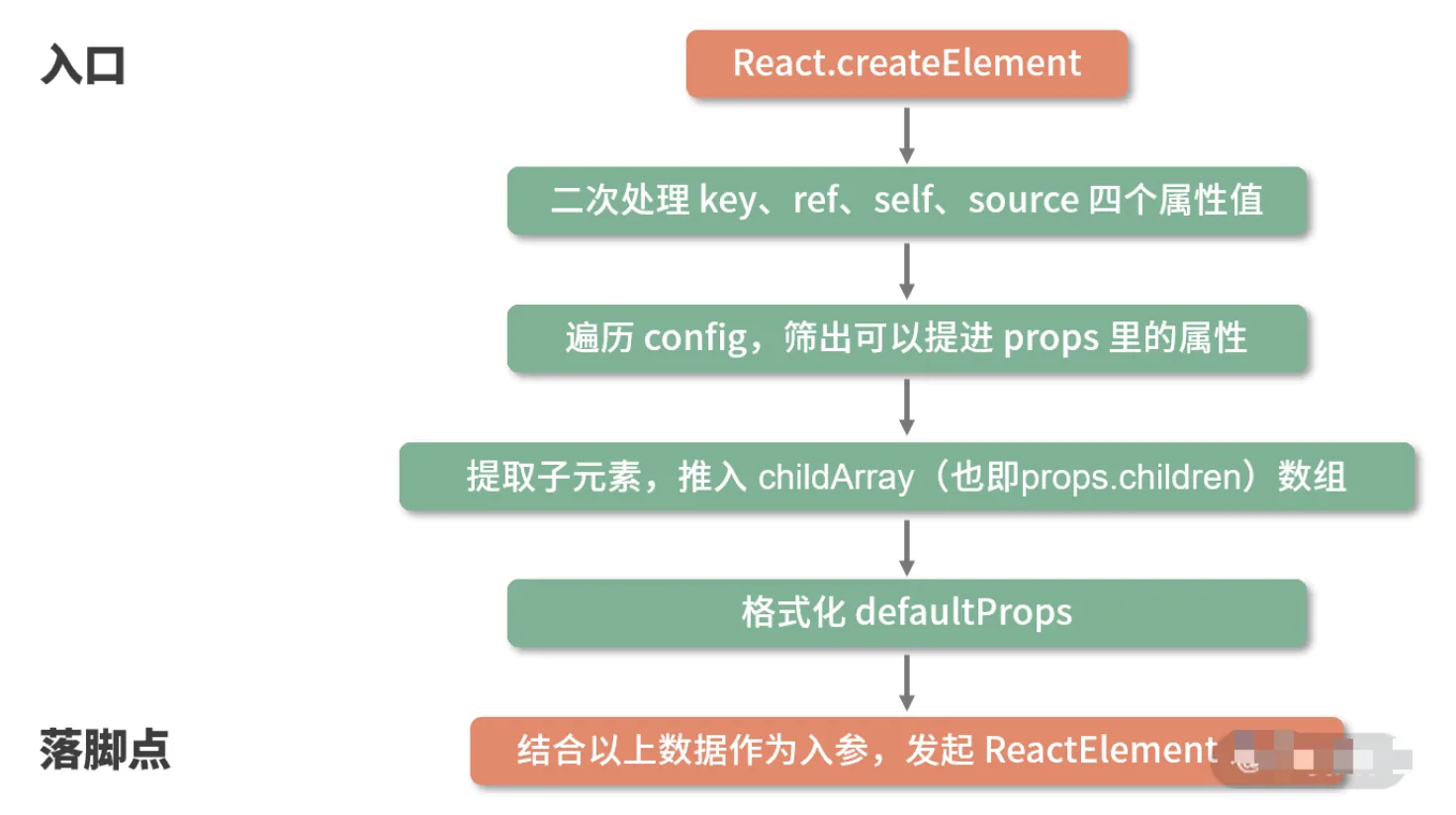
createElement 中并没有十分复杂的涉及算法或真实 DOM 的逻辑,它的每一个步骤几乎都是在格式化数据。
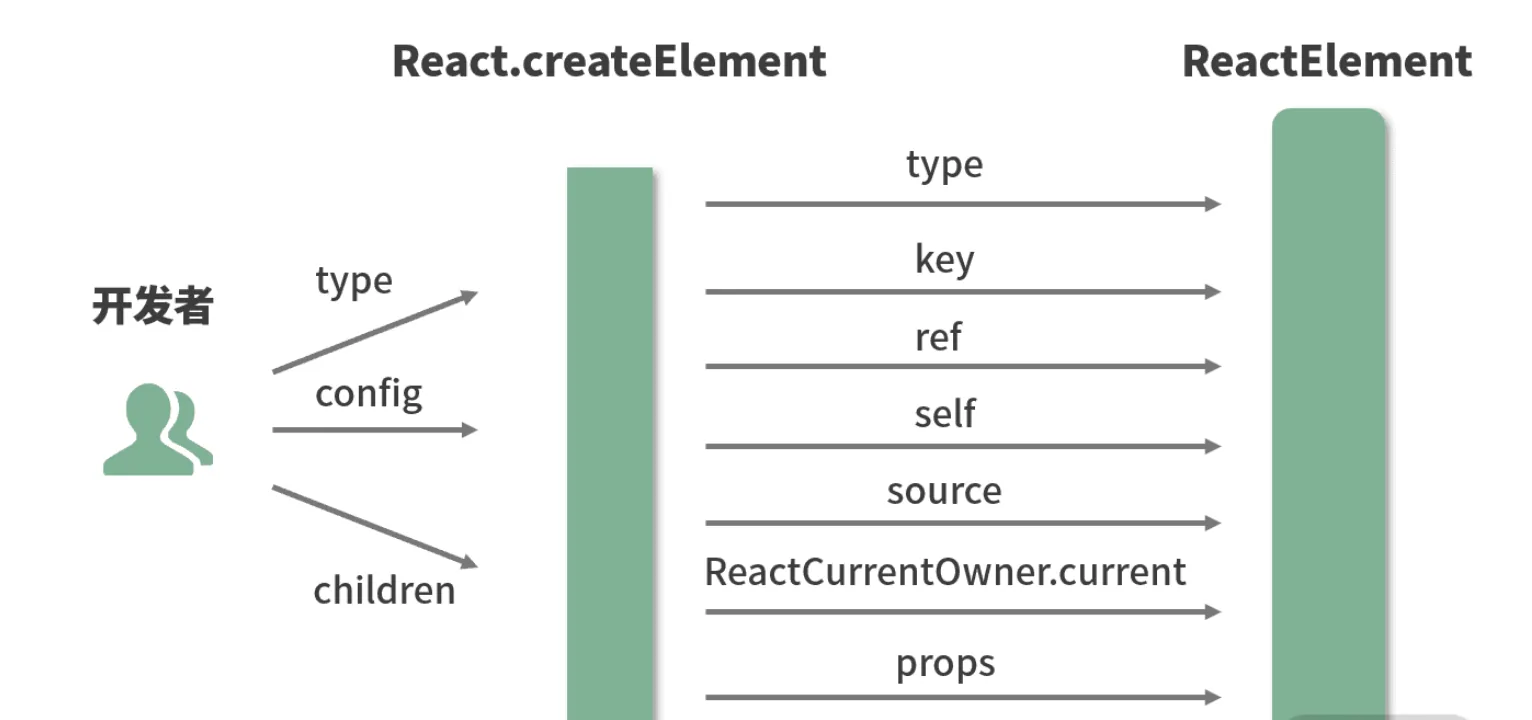
现在看来,
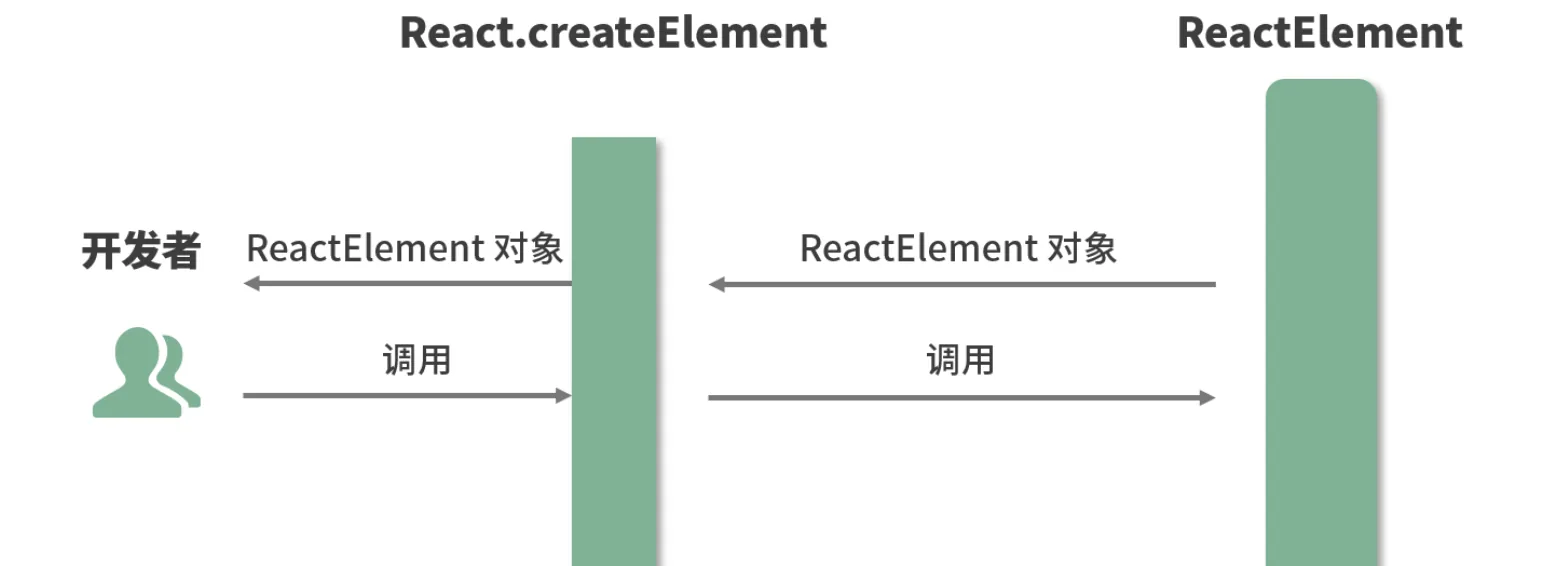
createElement原来只是个“参数中介”。此时我们的注意力自然而然地就聚焦在了ReactElement上
出参解读:初识虚拟 DOM
createElement执行到最后会 return 一个针对 ReactElement 的调用。这里关于 ReactElement,我依然先给出源码 + 注释形式的解析
const ReactElement = function(type, key, ref, self, source, owner, props) {
const element = {
// REACT_ELEMENT_TYPE是一个常量,用来标识该对象是一个ReactElement
$$typeof: REACT_ELEMENT_TYPE,
// 内置属性赋值
type: type,
key: key,
ref: ref,
props: props,
// 记录创造该元素的组件
_owner: owner,
};
//
if (__DEV__) {
// 这里是一些针对 __DEV__ 环境下的处理,对于大家理解主要逻辑意义不大,此处我直接省略掉,以免混淆视听
}
return element;
};
ReactElement其实只做了一件事情,那就是“创建”,说得更精确一点,是“组装”:ReactElement把传入的参数按照一定的规范,“组装”进了element对象里,并把它返回给了eact.createElement,最终React.createElement又把它交回到了开发者手中
const AppJSX = (<div className="App">
<h1 className="title">I am the title</h1>
<p className="content">I am the content</p>
</div>)
console.log(AppJSX)
你会发现它确实是一个标准的 ReactElement 对象实例

这个 ReactElement 对象实例,本质上是以 JavaScript 对象形式存在的对 DOM 的描述,也就是老生常谈的“虚拟 DOM”(准确地说,是虚拟 DOM 中的一个节点)
14 为什么 React 元素有一个 $$typeof 属性
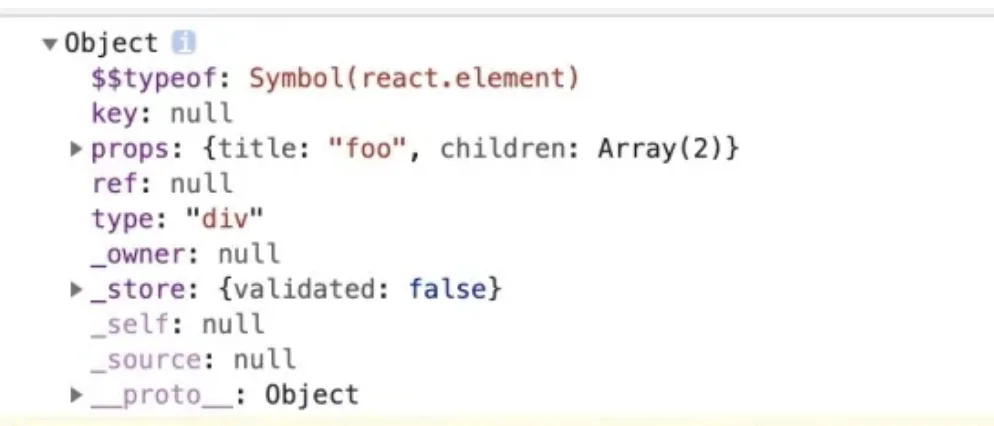
目的是为了防止 XSS 攻击。因为 Synbol 无法被序列化,所以 React 可以通过有没有 $$typeof 属性来断出当前的 element 对象是从数据库来的还是自己生成的。
- 如果没有 $$typeof 这个属性,react 会拒绝处理该元素。
- 在 React 的古老版本中,下面的写法会出现 XSS 攻击:
// 服务端允许用户存储 JSON
let expectedTextButGotJSON = {
type: 'div',
props: {
dangerouslySetInnerHTML: {
__html: '/* 把你想的搁着 */'
},
},
// ...
};
let message = { text: expectedTextButGotJSON };
// React 0.13 中有风险
<p>
{message.text}
</p>
15 Virtual DOM 的工作原理是什么
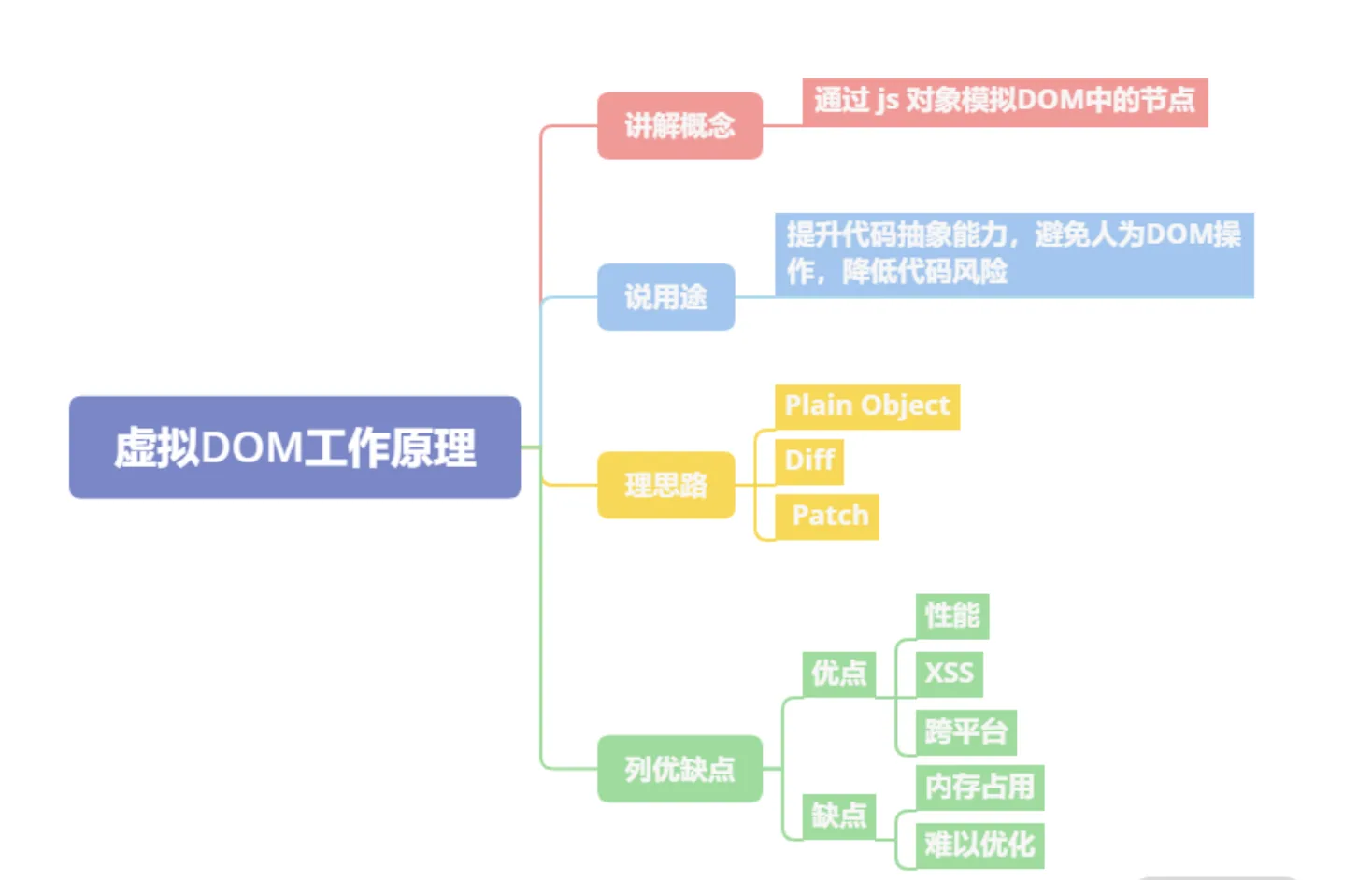
- 虚拟 DOM 的工作原理是
通过 JS 对象模拟 DOM 的节点。在 Facebook 构建 React 初期时,考虑到要提升代码抽象能力、避免人为的 DOM 操作、降低代码整体风险等因素,所以引入了虚拟 DOM - 虚拟 DOM 在实现上通常是
Plain Object,以 React 为例,在render函数中写的JSX会在Babel插件的作用下,编译为React.createElement执行JSX中的属性参数 React.createElement执行后会返回一个Plain Object,它会描述自己的tag类型、props属性以及children情况等。这些Plain Object通过树形结构组成一棵虚拟DOM树。当状态发生变更时,将变更前后的虚拟DOM树进行差异比较,这个过程称为diff,生成的结果称为patch。计算之后,会渲染Patch完成对真实DOM的操作。- 虚拟 DOM 的优点主要有三点:
改善大规模DOM操作的性能、规避 XSS 风险、能以较低的成本实现跨平台开发。 - 虚拟 DOM 的缺点在社区中主要有两点
- 内存占用较高,因为需要模拟整个网页的真实
DOM - 高性能应用场景存在难以优化的情况,类似像 Google Earth 一类的高性能前端应用在技术选型上往往不会选择 React
- 内存占用较高,因为需要模拟整个网页的真实
除了渲染页面,虚拟 DOM 还有哪些应用场景?
这个问题考验面试者的想象力。通常而言,我们只是将虚拟 DOM 与渲染绑定在一起,但实际上虚拟 DOM 的应用更为广阔。比如,只要你记录了真实 DOM 变更,它甚至可以应用于埋点统计与数据记录等。
SSR原理
借助虚拟dom,服务器中没有dom概念的,react巧妙的借助虚拟dom,然后可以在服务器中nodejs可以运行起来react代码。
16 React有哪些优化性能的手段
类组件中的优化手段
- 使用纯组件
PureComponent作为基类。 - 使用
shouldComponentUpdate生命周期函数来自定义渲染逻辑。
方法组件中的优化手段
- 使用
React.memo高阶函数包装组件,React.memo可以实现类似于shouldComponentUpdate或者PureComponent的效果 - 使用
useMemo- 使用
React.useMemo精细化的管控,useMemo 控制的则是是否需要重复执行某一段逻辑,而React.memo 控制是否需要重渲染一个组件
- 使用
- 使用
useCallBack。
其他方式
- 在列表需要频繁变动时,使用唯一 id 作为 key,而不是数组下标。
- 必要时通过改变 CSS 样式隐藏显示组件,而不是通过条件判断显示隐藏组件。
- 使用
Suspense和 lazy 进行懒加载,例如:
import React, { lazy, Suspense } from "react";
export default class CallingLazyComponents extends React.Component {
render() {
var ComponentToLazyLoad = null;
if (this.props.name == "Mayank") {
ComponentToLazyLoad = lazy(() => import("./mayankComponent"));
} else if (this.props.name == "Anshul") {
ComponentToLazyLoad = lazy(() => import("./anshulComponent"));
}
return (
<div>
<h1>This is the Base User: {this.state.name}</h1>
<Suspense fallback={<div>Loading...</div>}>
<ComponentToLazyLoad />
</Suspense>
</div>
)
}
}