三、结构型模式(1/2)
三、结构型模式
代理模式
代理模式 (Proxy Pattern)又称委托模式,它为目标对象创造了一个代理对象,以控制对目标对象的访问。
- 代理模式把代理对象插入到访问者和目标对象之间,从而为访问者对目标对象的访问引入一定的间接性。正是这种间接性,给了代理对象很多操作空间,比如在调用目标对象前和调用后进行一些预操作和后操作,从而实现新的功能或者扩展目标的功能。
1. 你曾见过的代理模式
明星总是有个助理,或者说经纪人,如果某导演来请这个明星演出,或者某个品牌来找明星做广告,需要经纪人帮明星做接洽工作。而且经纪人也起到过滤的作用,毕竟明星也不是什么电影和广告都会接。类似的场景还有很多,再比如领导和秘书…(emmm)
- 再看另一个例子。打官司是件非常麻烦的事,包括查找法律条文、起草法律文书、法庭辩论、签署法律文件、申请法院执行等等流程。此时,当事人就可聘请代理律师来完成整个打官司的所有事务。当事人只需与代理律师签订全权委托协议,那么整个打官司的过程,当事人都可以不用出现。法院的一些复杂事务都可以通过代理律师来完成,而法院需要当事人完成某些工作的时候,比如出庭,代理律师才会通知当事人,并为当事人出谋划策。
在类似的场景中,有以下特点:
- 导演/法院(访问者)对明星/当事人(目标)的访问都是通过经纪人/律师(代理)来完成;
- 经纪人/律师(代理)对访问有过滤的功能;
2. 实例的代码实现
我们使用 JavaScript 来将上面的明星例子实现一下。
/* 明星 */
var SuperStar = {
name: '小鲜肉',
playAdvertisement: function(ad) {
console.log(ad)
}
}
/* 经纪人 */
var ProxyAssistant = {
name: '经纪人张某',
playAdvertisement: function(reward, ad) {
if (reward > 1000000) { // 如果报酬超过100w
console.log('没问题,我们小鲜鲜最喜欢拍广告了!')
SuperStar.playAdvertisement(ad)
} else
console.log('没空,滚!')
}
}
ProxyAssistant.playAdvertisement(10000, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没空,滚
这里我们通过经纪人的方式来和明星取得联系,经纪人会视条件过滤一部分合作请求。
- 我们可以升级一下,比如如果明星没有档期的话,可以通过经纪人安排档期,当明星有空的时候才让明星来拍广告。这里通过
Promise的方式来实现档期的安排:
/* 明星 */
const SuperStar = {
name: '小鲜肉',
playAdvertisement(ad) {
console.log(ad)
}
}
/* 经纪人 */
const ProxyAssistant = {
name: '经纪人张某',
scheduleTime() {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log('小鲜鲜有空了')
resolve()
}, 2000) // 发现明星有空了
})
},
playAdvertisement(reward, ad) {
if (reward > 1000000) { // 如果报酬超过100w
console.log('没问题,我们小鲜鲜最喜欢拍广告了!')
ProxyAssistant.scheduleTime() // 安排上了
.then(() => SuperStar.playAdvertisement(ad))
} else
console.log('没空,滚!')
}
}
ProxyAssistant.playAdvertisement(10000, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没空,滚
ProxyAssistant.playAdvertisement(1000001, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没问题,我们小鲜鲜最喜欢拍广告了!
// 2秒后
// 输出: 小鲜鲜有空了
// 输出: 纯蒸酸牛奶,味道纯纯,尽享纯蒸
这里就简单实现了经纪人对请求的过滤,对明星档期的安排,实现了一个代理对象的基本功能。
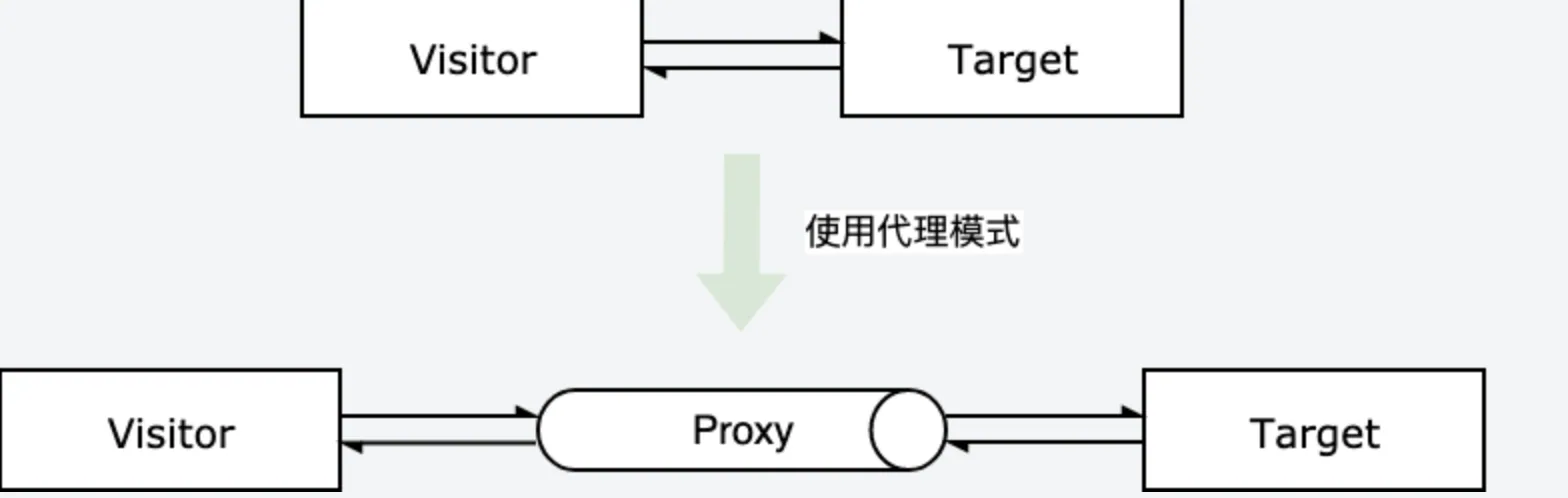
3. 代理模式的概念
对于上面的例子,明星就相当于被代理的目标对象(
Target),而经纪人就相当于代理对象(Proxy),希望找明星的人是访问者(Visitor),他们直接找不到明星,只能找明星的经纪人来进行业务商洽。主要有以下几个概念:
Target: 目标对象,也是被代理对象,是具体业务的实际执行者;Proxy: 代理对象,负责引用目标对象,以及对访问的过滤和预处理;
概略图如下:
ES6 原生提供了
Proxy构造函数,这个构造函数让我们可以很方便地创建代理对象:
var proxy = new Proxy(target, handler);
参数中
target是被代理对象,handler用来设置代理行为。
这里使用 Proxy 来实现一下上面的经纪人例子:
/* 明星 */
const SuperStar = {
name: '小鲜肉',
scheduleFlag: false, // 档期标识位,false-没空(默认值),true-有空
playAdvertisement(ad) {
console.log(ad)
}
}
/* 经纪人 */
const ProxyAssistant = {
name: '经纪人张某',
scheduleTime(ad) {
const schedule = new Proxy(SuperStar, { // 在这里监听 scheduleFlag 值的变化
set(obj, prop, val) {
if (prop !== 'scheduleFlag') return
if (obj.scheduleFlag === false &&
val === true) { // 小鲜肉现在有空了
obj.scheduleFlag = true
obj.playAdvertisement(ad) // 安排上了
}
}
})
setTimeout(() => {
console.log('小鲜鲜有空了')
schedule.scheduleFlag = true // 明星有空了
}, 2000)
},
playAdvertisement(reward, ad) {
if (reward > 1000000) { // 如果报酬超过100w
console.log('没问题,我们小鲜鲜最喜欢拍广告了!')
ProxyAssistant.scheduleTime(ad)
} else
console.log('没空,滚!')
}
}
ProxyAssistant.playAdvertisement(10000, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没空,滚
ProxyAssistant.playAdvertisement(1000001, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没问题,我们小鲜鲜最喜欢拍广告了!
// 2秒后
// 输出: 小鲜鲜有空了
// 输出: 纯蒸酸牛奶,味道纯纯,尽享纯蒸
在 ES6 之前,一般是使用 Object.defineProperty 来完成相同的功能,我们可以使用这个 API 改造一下:
/* 明星 */
const SuperStar = {
name: '小鲜肉',
scheduleFlagActually: false, // 档期标识位,false-没空(默认值),true-有空
playAdvertisement(ad) {
console.log(ad)
}
}
/* 经纪人 */
const ProxyAssistant = {
name: '经纪人张某',
scheduleTime(ad) {
Object.defineProperty(SuperStar, 'scheduleFlag', { // 在这里监听 scheduleFlag 值的变化
get() {
return SuperStar.scheduleFlagActually
},
set(val) {
if (SuperStar.scheduleFlagActually === false &&
val === true) { // 小鲜肉现在有空了
SuperStar.scheduleFlagActually = true
SuperStar.playAdvertisement(ad) // 安排上了
}
}
})
setTimeout(() => {
console.log('小鲜鲜有空了')
SuperStar.scheduleFlag = true
}, 2000) // 明星有空了
},
playAdvertisement(reward, ad) {
if (reward > 1000000) { // 如果报酬超过100w
console.log('没问题,我们小鲜鲜最喜欢拍广告了!')
ProxyAssistant.scheduleTime(ad)
} else
console.log('没空,滚!')
}
}
ProxyAssistant.playAdvertisement(10000, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没空,滚
ProxyAssistant.playAdvertisement(1000001, '纯蒸酸牛奶,味道纯纯,尽享纯蒸')
// 输出: 没问题,我们小鲜鲜最喜欢拍广告了!
// 2秒后
// 输出: 小鲜鲜有空了
// 输出: 纯蒸酸牛奶,味道纯纯,尽享纯蒸
4. 代理模式在实战中的应用 4.1 拦截器
上一小节使用代理模式代理对象的访问的方式,一般又被称为拦截器。
- 拦截器的思想在实战中应用非常多,比如我们在项目中经常使用
Axios的实例来进行HTTP的请求,使用拦截器interceptor可以提前对request请求和response返回进行一些预处理,比如: request请求头的设置,和Cookie信息的设置;- 权限信息的预处理,常见的比如验权操作或者
Token验证; - 数据格式的格式化,比如对组件绑定的
Date类型的数据在请求前进行一些格式约定好的序列化操作; - 空字段的格式预处理,根据后端进行一些过滤操作;
response的一些通用报错处理,比如使用Message控件抛出错误;除了HTTP相关的拦截器之外,还有路由跳转的拦截器,可以进行一些路由跳转的预处理等操作。
4.2 前端框架的数据响应式化
- 现在的很多前端框架或者状态管理框架都使用上面介绍的
Object.defineProperty和Proxy来实现数据的响应式化,比如Vue、Mobx、AvalonJS等,Vue 2.x与AvalonJS使用前者,而Vue 3.x与Mobx 5.x使用后者。 Vue 2.x中通过Object.defineProperty来劫持各个属性的setter/getter,在数据变动时,通过发布-订阅模式发布消息给订阅者,触发相应的监听回调,从而实现数据的响应式化,也就是数据到视图的双向绑定。
为什么
Vue 2.x到3.x要从Object.defineProperty改用Proxy呢,是因为前者的一些局限性,导致的以下缺陷:
- 无法监听利用索引直接设置数组的一个项,例如:
vm.items[indexOfItem] = newValue; - 无法监听数组的长度的修改,例如:
vm.items.length = newLength; - 无法监听
ES6的Set、WeakSet、Map、WeakMap的变化; - 无法监听
Class类型的数据; - 无法监听对象属性的新加或者删除;
- 除此之外还有性能上的差异,基于这些原因,
Vue 3.x改用Proxy来实现数据监听了。当然缺点就是对IE用户的不友好,兼容性敏感的场景需要做一些取舍。
4.3 缓存代理
在高阶函数的文章中,就介绍了备忘模式,备忘模式就是使用缓存代理的思想,将复杂计算的结果缓存起来,下次传参一致时直接返回之前缓存的计算结果。
4.4 保护代理和虚拟代理
有的书籍中着重强调代理的两种形式:保护代理和虚拟代理:
- 保护代理 :当一个对象可能会收到大量请求时,可以设置保护代理,通过一些条件判断对请求进行过滤;
- 虚拟代理 :在程序中可以能有一些代价昂贵的操作,此时可以设置虚拟代理,虚拟代理会在适合的时候才执行操作。
保护代理其实就是对访问的过滤,之前的经纪人例子就属于这种类型。
而虚拟代理是为一个开销很大的操作先占位,之后再执行,比如:
一个很大的图片加载前,一般使用菊花图、低质量图片等提前占位,优化图片加载导致白屏的情况; 现在很流行的页面加载前使用骨架屏来提前占位,很多
WebApp和NativeApp都采用这种方式来优化用户白屏体验
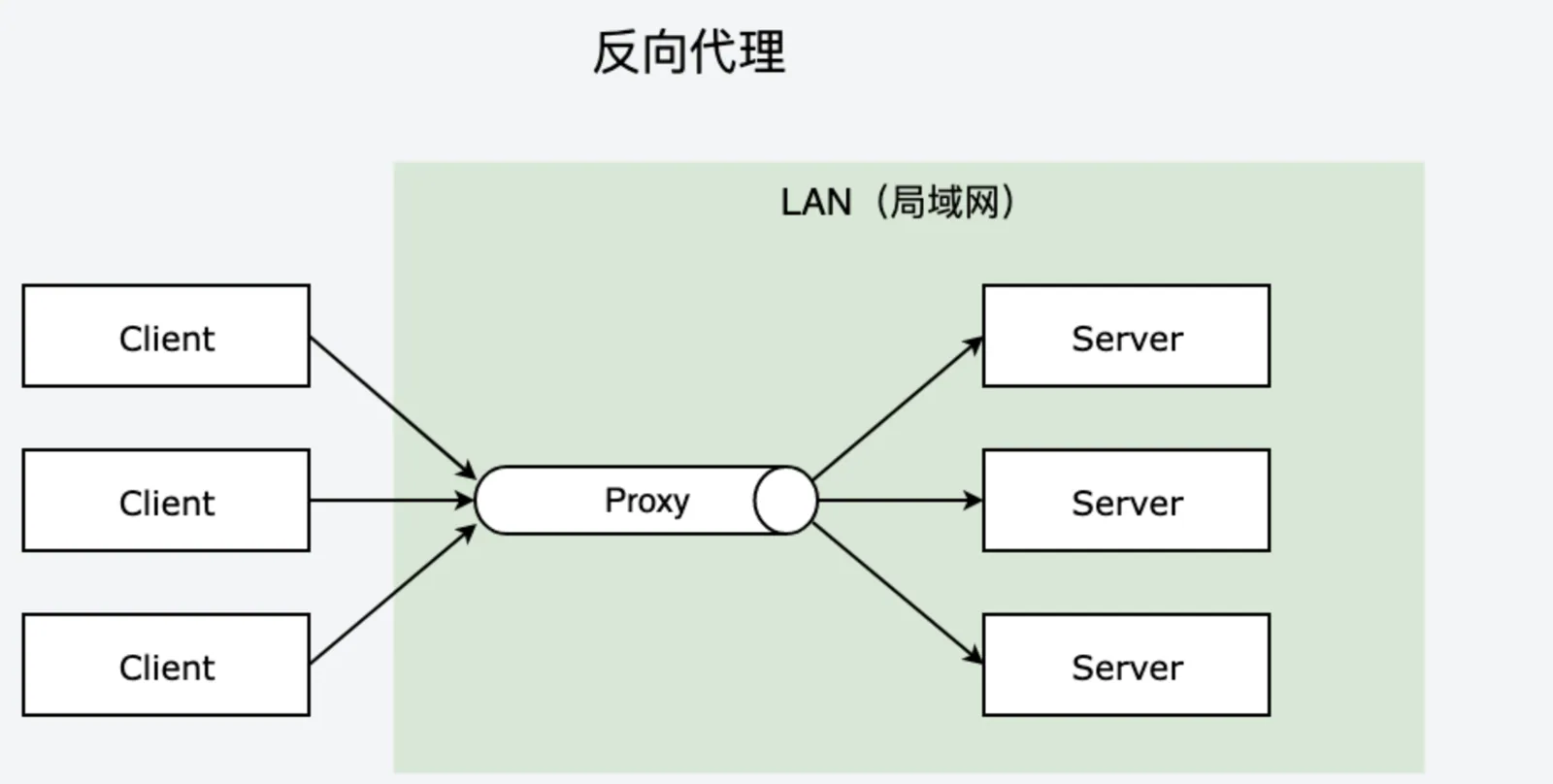
4.5 正向代理与反向代理
还有个经常用的例子是反向代理(Reverse Proxy),反向代理对应的是正向代理(Forward Proxy),他们的区别是:
- 正向代理: 一般的访问流程是客户端直接向目标服务器发送请求并获取内容,使用正向代理后,客户端改为向代理服务器发送请求,并指定目标服务器(原始服务器),然后由代理服务器和原始服务器通信,转交请求并获得的内容,再返回给客户端。正向代理隐藏了真实的客户端,为客户端收发请求,使真实客户端对服务器不可见;
- 反向代理: 与一般访问流程相比,使用反向代理后,直接收到请求的服务器是代理服务器,然后将请求转发给内部网络上真正进行处理的服务器,得到的结果返回给客户端。反向代理隐藏了真实的服务器,为服务器收发请求,使真实服务器对客户端不可见。
反向代理一般在处理跨域请求的时候比较常用,属于服务端开发人员的日常操作了,另外在缓存服务器、负载均衡服务器等等场景也是使用到代理模式的思想。
5. 代理模式的优缺点
代理模式的主要优点有:
- 代理对象在访问者与目标对象之间可以起到中介和保护目标对象的作用;
- 代理对象可以扩展目标对象的功能;
- 代理模式能将访问者与目标对象分离,在一定程度上降低了系统的耦合度,如果我们希望适度扩展目标对象的一些功能,通过修改代理对象就可以了,符合开闭原则;
- 代理模式的缺点主要是增加了系统的复杂度,要斟酌当前场景是不是真的需要引入代理模式(十八线明星就别请经纪人了)
6. 其他相关模式
很多其他的模式,比如状态模式、策略模式、访问者模式其实也是使用了代理模式,包括在之前高阶函数处介绍的备忘模式,本质上也是一种缓存代理。
6.1 代理模式与适配器模式
代理模式和适配器模式都为另一个对象提供间接性的访问,他们的区别:
- 适配器模式: 主要用来解决接口之间不匹配的问题,通常是为所适配的对象提供一个不同的接口;
- 代理模式: 提供访问目标对象的间接访问,以及对目标对象功能的扩展,一般提供和目标对象一样的接口;
6.2 代理模式与装饰者模式
装饰者模式实现上和代理模式类似,都是在访问目标对象之前或者之后执行一些逻辑,但是目的和功能不同:
- 装饰者模式: 目的是为了方便地给目标对象添加功能,也就是动态地添加功能;
- 代理模式: 主要目的是控制其他访问者对目标对象的访问;
享元模式
享元模式 (Flyweight Pattern)运用共享技术来有效地支持大量细粒度对象的复用,以减少创建的对象的数量。
享元模式的主要思想是共享细粒度对象,也就是说如果系统中存在多个相同的对象,那么只需共享一份就可以了,不必每个都去实例化每一个对象,这样来精简内存资源,提升性能和效率。
Fly 意为苍蝇,Flyweight 指轻蝇量级,指代对象粒度很小。
1. 你曾见过的享元模式
我们去驾考的时候,如果给每个考试的人都准备一辆车,那考场就挤爆了,考点都堆不下考试车,因此驾考现场一般会有几辆车给要考试的人依次使用。如果考生人数少,就分别少准备几个自动档和手动档的驾考车,考生多的话就多准备几辆。如果考手动档的考生比较多,就多准备几辆手动档的驾考车。
我们去考四六级的时候(为什么这么多考试?😅),如果给每个考生都准备一个考场,怕是没那么多考场也没有这么多监考老师,因此现实中的大多数情况都是几十个考生共用一个考场。四级考试和六级考试一般同时进行,如果考生考的是四级,那么就安排四级考场,听四级的听力和试卷,六级同理。
生活中类似的场景还有很多,比如咖啡厅的咖啡口味,餐厅的菜品种类,拳击比赛的重量级等等。
在类似场景中,这些例子有以下特点:
- 目标对象具有一些共同的状态,比如驾考考生考的是自动档还是手动档,四六级考生考的是四级还是六级;
- 这些共同的状态所对应的对象,可以被共享出来;
2. 实例的代码实现
首先假设考生的 ID 为奇数则考的是手动档,为偶数则考的是自动档。如果给所有考生都 new 一个驾考车,那么这个系统中就会创建了和考生数量一致的驾考车对象:
var candidateNum = 10 // 考生数量
var examCarNum = 0 // 驾考车的数量
/* 驾考车构造函数 */
function ExamCar(carType) {
examCarNum++
this.carId = examCarNum
this.carType = carType ? '手动档' : '自动档'
}
ExamCar.prototype.examine = function(candidateId) {
console.log('考生- ' + candidateId + ' 在' + this.carType + '驾考车- ' + this.carId + ' 上考试')
}
for (var candidateId = 1; candidateId <= candidateNum; candidateId++) {
var examCar = new ExamCar(candidateId % 2)
examCar.examine(candidateId)
}
console.log('驾考车总数 - ' + examCarNum)
// 输出: 驾考车总数 - 10
如果考生很多,那么系统中就会存在更多个驾考车对象实例,假如驾考车对象比较复杂,那么这些新建的驾考车实例就会占用大量内存。这时我们将同种类型的驾考车实例进行合并,手动档和自动档档驾考车分别引用同一个实例,就可以节约大量内存:
var candidateNum = 10 // 考生数量
var examCarNum = 0 // 驾考车的数量
/* 驾考车构造函数 */
function ExamCar(carType) {
examCarNum++
this.carId = examCarNum
this.carType = carType ? '手动档' : '自动档'
}
ExamCar.prototype.examine = function(candidateId) {
console.log('考生- ' + candidateId + ' 在' + this.carType + '驾考车- ' + this.carId + ' 上考试')
}
var manualExamCar = new ExamCar(true)
var autoExamCar = new ExamCar(false)
for (var candidateId = 1; candidateId <= candidateNum; candidateId++) {
var examCar = candidateId % 2 ? manualExamCar : autoExamCar
examCar.examine(candidateId)
}
console.log('驾考车总数 - ' + examCarNum)
// 输出: 驾考车总数 - 2
可以看到我们使用 2 个驾考车实例就实现了刚刚 10 个驾考车实例实现的功能。这是仅有 10 个考生的情况,如果有几百上千考生,这时我们节约的内存就比较可观了,这就是享元模式要达到的目的。
3. 享元模式改进
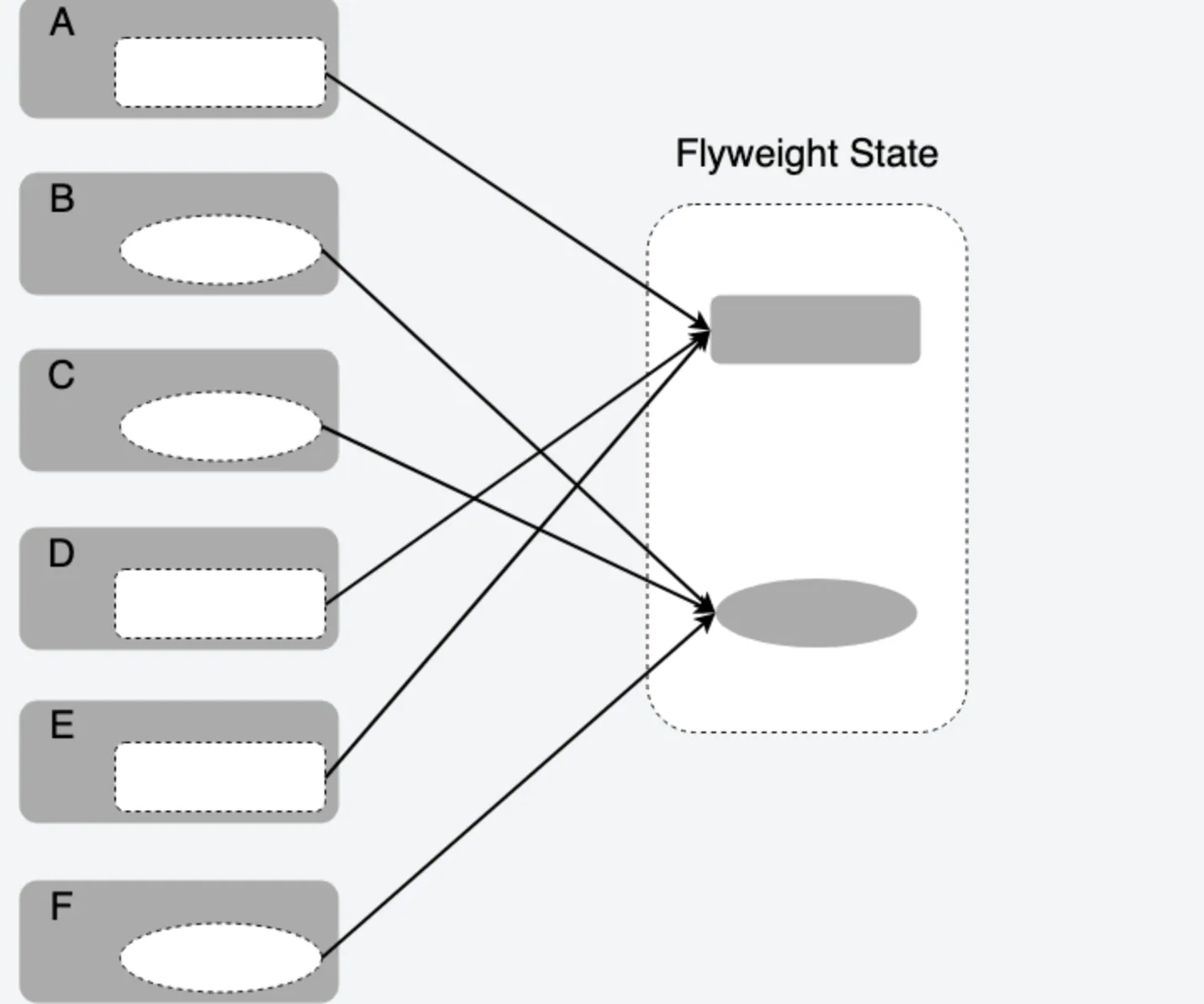
- 如果你阅读了之前文章关于继承部分的讲解,那么你实际上已经接触到享元模式的思想了。相比于构造函数窃取,在原型链继承和组合继承中,子类通过原型 prototype 来复用父类的方法和属性,如果子类实例每次都创建新的方法与属性,那么在子类实例很多的情况下,内存中就存在有很多重复的方法和属性,即使这些方法和属性完全一样,因此这部分内存完全可以通过复用来优化,这也是享元模式的思想。
- 传统的享元模式是将目标对象的状态区分为内部状态和外部状态,内部状态相同的对象可以被共享出来指向同一个内部状态。正如之前举的驾考和四六级考试的例子中,自动档还是手动档、四级还是六级,就属于驾考考生、四六级考生中的内部状态,对应的驾考车、四六级考场就是可以被共享的对象。而考生的年龄、姓名、籍贯等就属于外部状态,一般没有被共享出来的价值。
主要的原理可以参看下面的示意图:
- 享元模式的主要思想是细粒度对象的共享和复用,因此对之前的驾考例子,我们可以继续改进一下:
- 如果某考生正在使用一辆驾考车,那么这辆驾考车的状态就是被占用,其他考生只能选择剩下未被占用状态的驾考车;
- 如果某考生对驾考车的使用完毕,那么将驾考车开回考点,驾考车的状态改为未被占用,供给其他考生使用;
- 如果所有驾考车都被占用,那么其他考生只能等待正在使用驾考车的考生使用完毕,直到有驾考车的状态变为未被占用;
- 组织单位可以根据考生数量多准备几辆驾考车,比如手动档考生比较多,那么手动档驾考车就应该比自动档驾考车多准备几辆;
- 我们可以简单实现一下,为了方便起见,这里就直接使用 ES6 的语法。
- 首先创建 3 个手动档驾考车,然后注册 10 个考生参与考试,一开始肯定有 3 个考生同时上车,然后在某个考生考完之后其他考生接着后面考。为了实现这个过程,这里使用了 Promise,考试的考生在 0 到 2 秒后的随机时间考试完毕归还驾考车,其他考生在前面考生考完之后接着进行考试:
let examCarNum = 0 // 驾考车总数
/* 驾考车对象 */
class ExamCar {
constructor(carType) {
examCarNum++
this.carId = examCarNum
this.carType = carType ? '手动档' : '自动档'
this.usingState = false // 是否正在使用
}
/* 在本车上考试 */
examine(candidateId) {
return new Promise((resolve => {
this.usingState = true
console.log(`考生- ${ candidateId } 开始在${ this.carType }驾考车- ${ this.carId } 上考试`)
setTimeout(() => {
this.usingState = false
console.log(`%c考生- ${ candidateId } 在${ this.carType }驾考车- ${ this.carId } 上考试完毕`, 'color:#f40')
resolve() // 0~2秒后考试完毕
}, Math.random() * 2000)
}))
}
}
/* 手动档汽车对象池 */
ManualExamCarPool = {
_pool: [], // 驾考车对象池
_candidateQueue: [], // 考生队列
/* 注册考生 ID 列表 */
registCandidates(candidateList) {
candidateList.forEach(candidateId => this.registCandidate(candidateId))
},
/* 注册手动档考生 */
registCandidate(candidateId) {
const examCar = this.getManualExamCar() // 找一个未被占用的手动档驾考车
if (examCar) {
examCar.examine(candidateId) // 开始考试,考完了让队列中的下一个考生开始考试
.then(() => {
const nextCandidateId = this._candidateQueue.length && this._candidateQueue.shift()
nextCandidateId && this.registCandidate(nextCandidateId)
})
} else this._candidateQueue.push(candidateId)
},
/* 注册手动档车 */
initManualExamCar(manualExamCarNum) {
for (let i = 1; i <= manualExamCarNum; i++) {
this._pool.push(new ExamCar(true))
}
},
/* 获取状态为未被占用的手动档车 */
getManualExamCar() {
return this._pool.find(car => !car.usingState)
}
}
ManualExamCarPool.initManualExamCar(3) // 一共有3个驾考车
ManualExamCarPool.registCandidates([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) // 10个考生来考试
在浏览器中运行下试试:
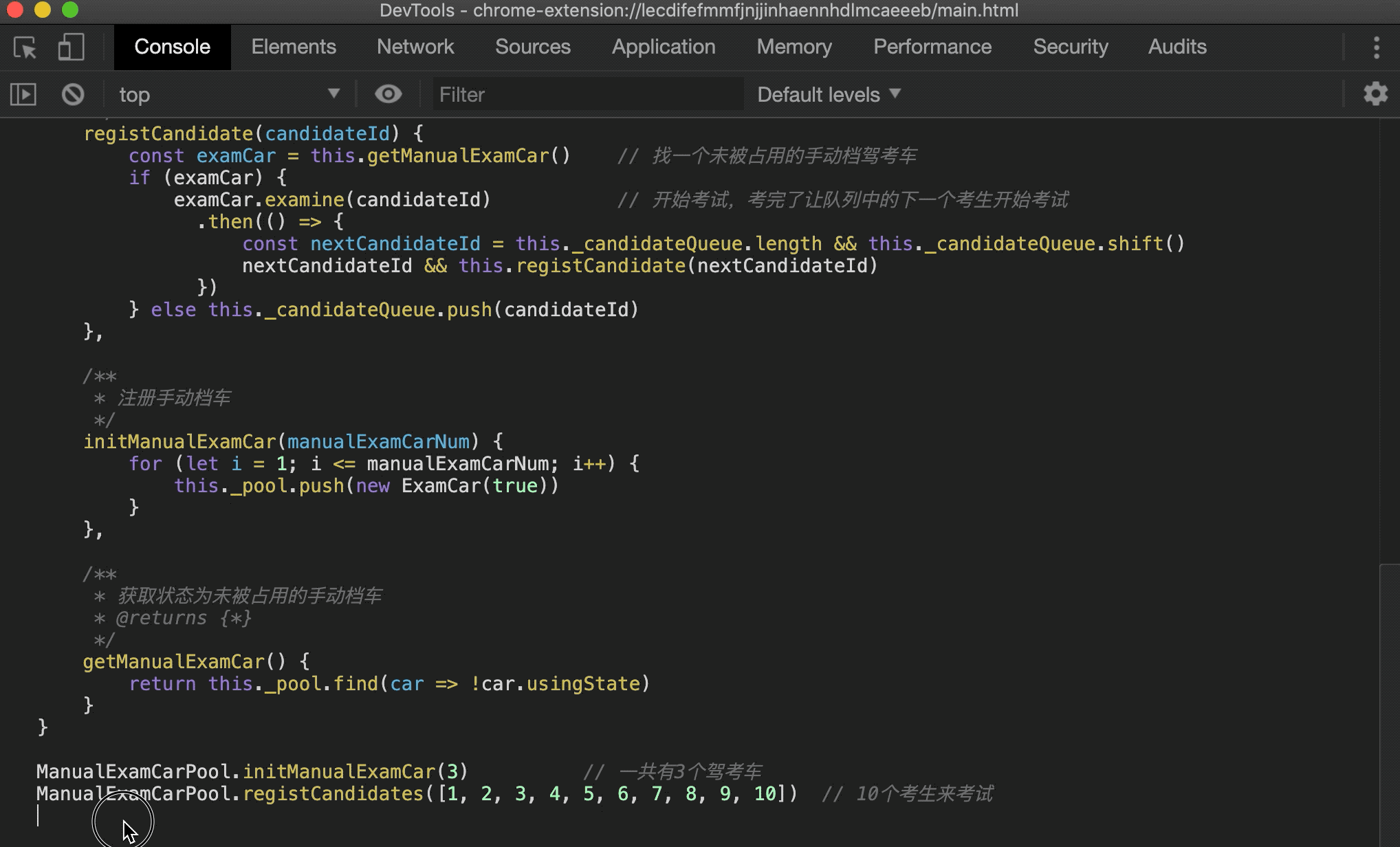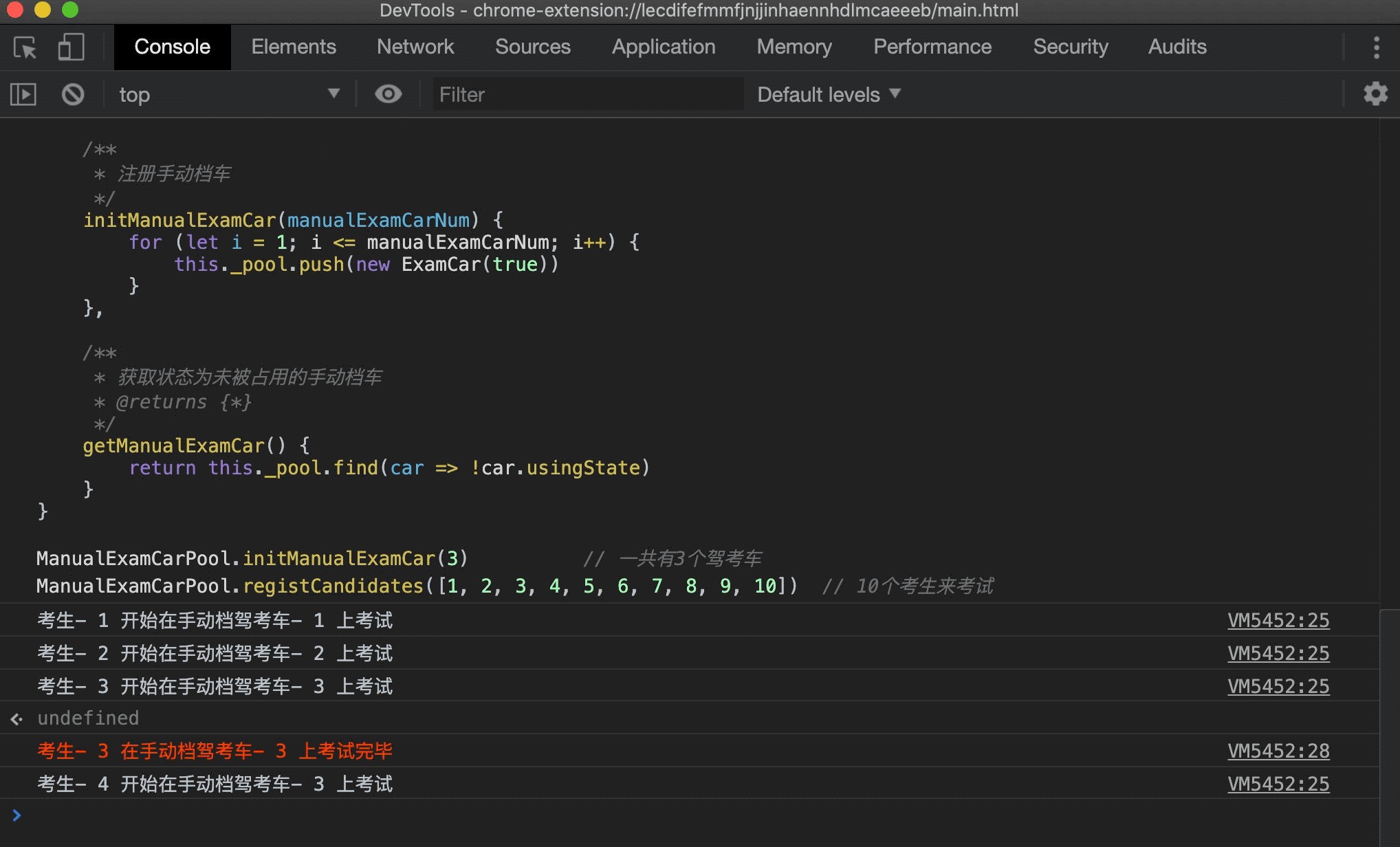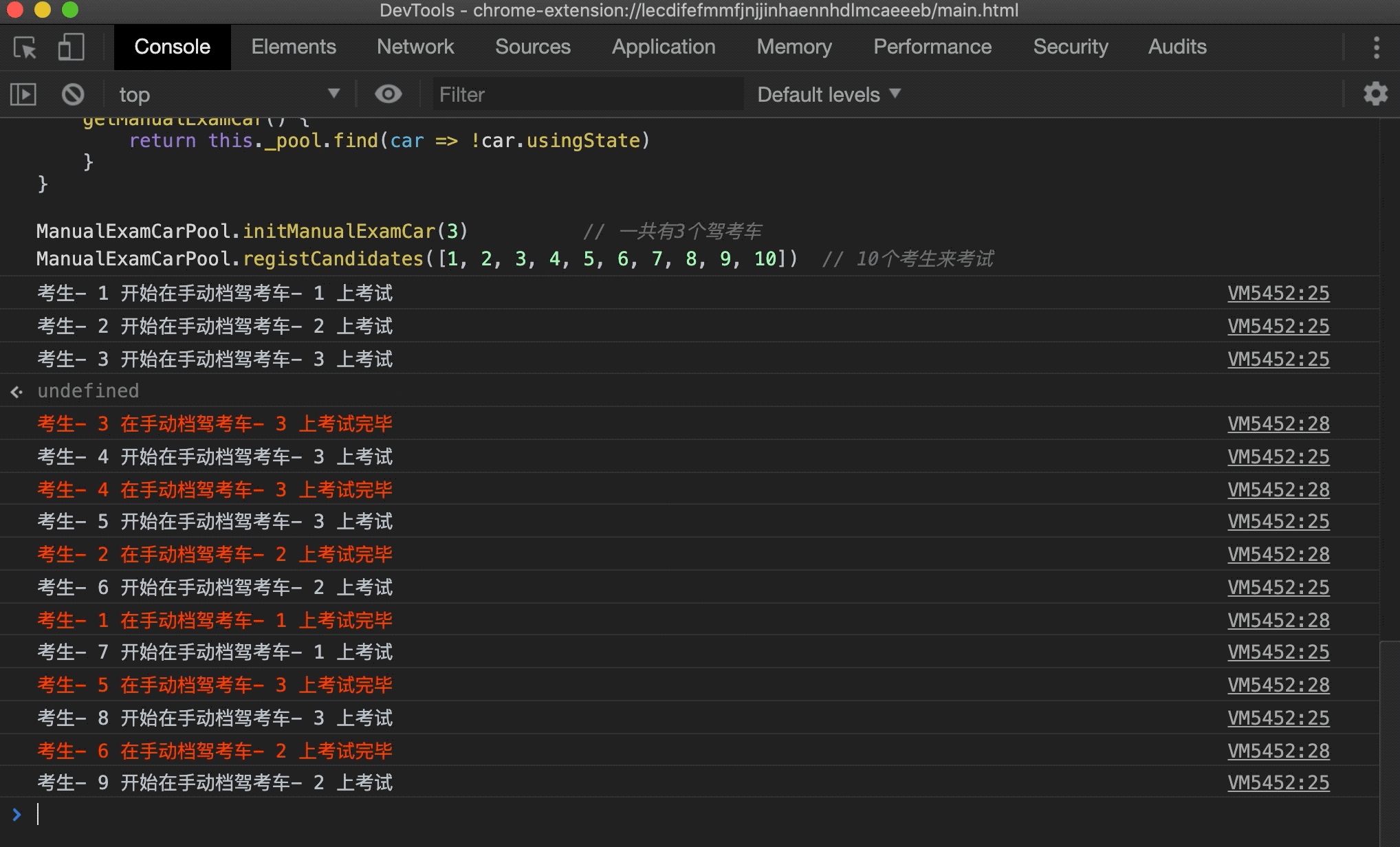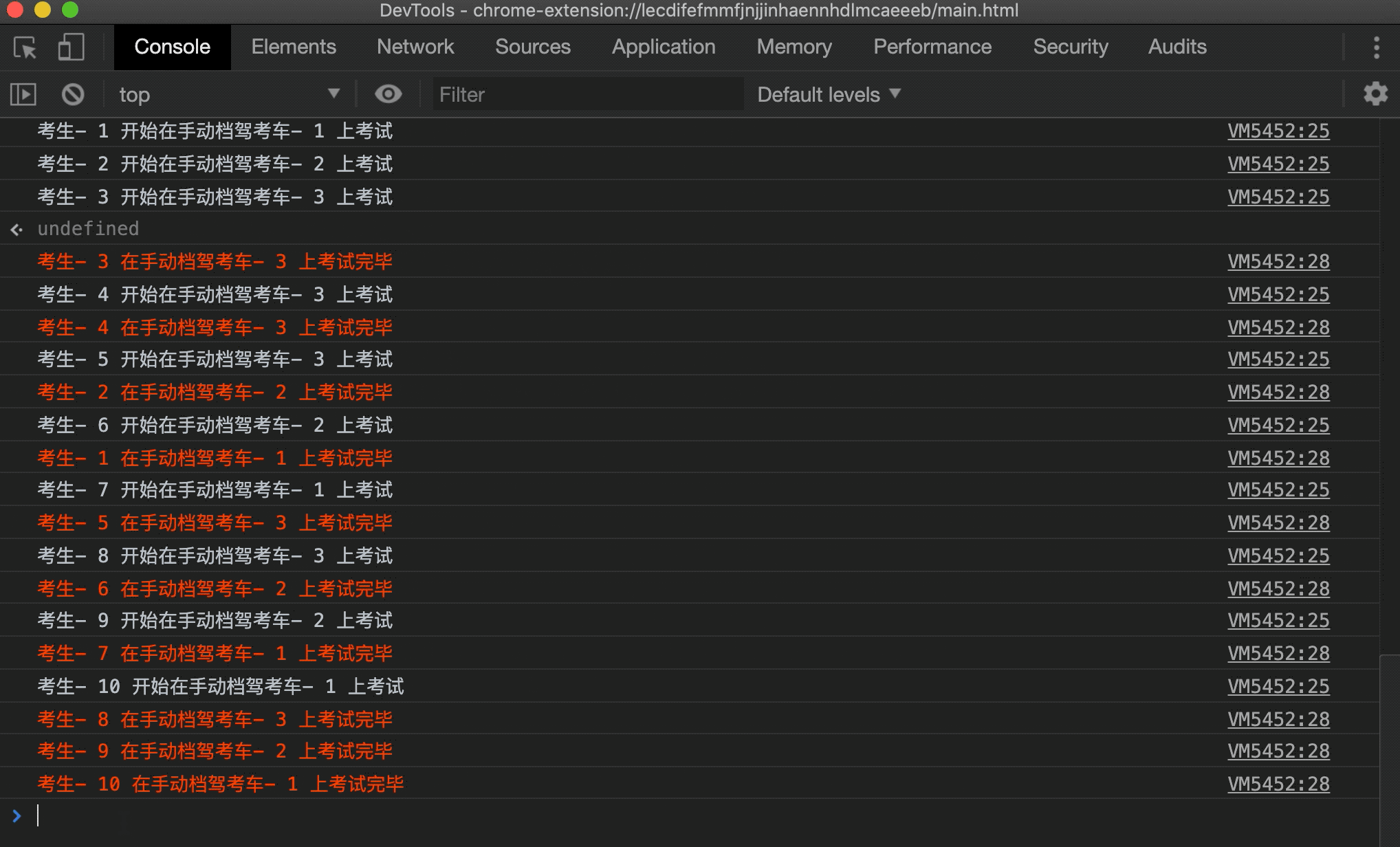
可以看到一个驾考的过程被模拟出来了,这里只简单实现了手动档,自动档驾考场景同理,就不进行实现了。上面的实现还可以进一步优化,比如考生多的时候自动新建驾考车,考生少的时候逐渐减少驾考车,但又不能无限新建驾考车对象,这些情况读者可以自行发挥~
- 如果可以将目标对象的内部状态和外部状态区分的比较明显,就可以将内部状态一致的对象很方便地共享出来,但是对 JavaScript 来说,我们并不一定要严格区分内部状态和外部状态才能进行资源共享,比如资源池模式。
4. 资源池 上
- 面这种改进的模式一般叫做资源池(Resource Pool),或者叫对象池(Object Pool),可以当作是享元模式的升级版,实现不一样,但是目的相同。资源池一般维护一个装载对象的池子,封装有获取、释放资源的方法,当需要对象的时候直接从资源池中获取,使用完毕之后释放资源等待下次被获取。
- 在上面的例子中,驾考车相当于有限资源,考生作为访问者根据资源的使用情况从资源池中获取资源,如果资源池中的资源都正在被占用,要么资源池创建新的资源,要么访问者等待占用的资源被释放。
- 资源池在后端应用相当广泛,比如缓冲池、连接池、线程池、字符常量池等场景,前端使用场景不多,但是也有使用,比如有些频繁的
DOM创建销毁操作,就可以引入对象池来节约一些 DOM 创建损耗。
下面介绍资源池的几种主要应用。
4.1 线程池
以
Node.js中的线程池为例,Node.js的JavaScript引擎是执行在单线程中的,启动的时候会新建 4 个线程放到线程池中,当遇到一些异步I/O操作(比如文件异步读写、DNS查询等)或者一些 CPU 密集的操作(Crypto、Zlib模块等)的时候,会在线程池中拿出一个线程去执行。如果有需要,线程池会按需创建新的线程。
线程池在整个
Node.js事件循环中的位置可以参照下图:
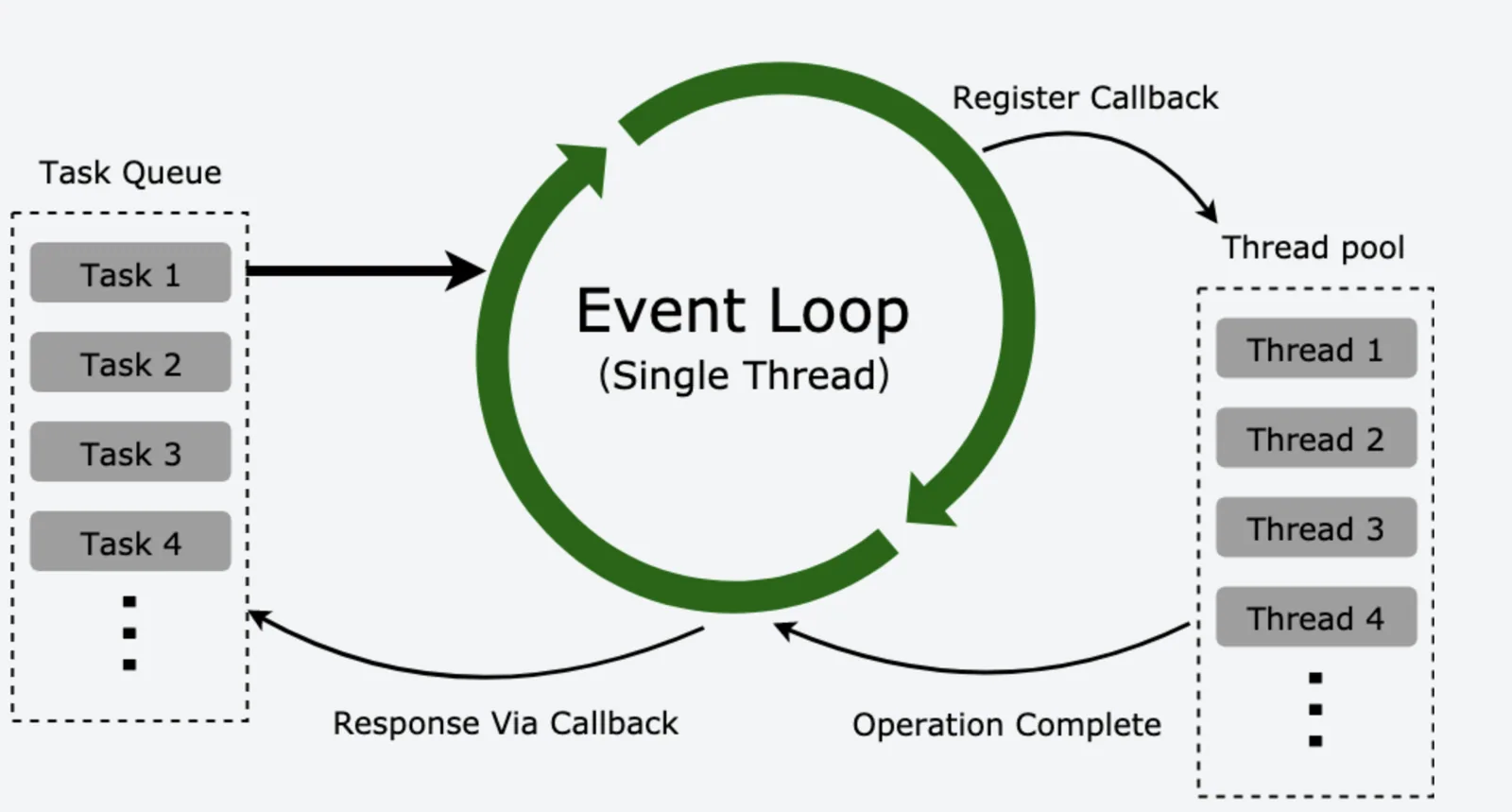
上面这个图就是 Node.js 的事件循环(Event Loop)机制,简单解读一下(扩展视野,不一定需要懂):
- 所有任务都在主线程上执行,形成执行栈(Execution Context Stack);
- 主线程之外维护一个任务队列(Task Queue),接到请求时将请求作为一个任务放入这个队列中,然后继续接收其他请求;
- 一旦执行栈中的任务执行完毕,主线程空闲时,主线程读取任务队列中的任务,检查队列中是否有要处理的事件,这时要分两种情况:如果是非 I/O 任务,就亲自处理,并通过回调函数返回到上层调用;如果是 I/O 任务,将传入的参数和回调函数封装成请求对象,并将这个请求对象推入线程池等待执行,主线程则读取下一个任务队列的任务,以此类推处理完任务队列中的任务;
- 线程池当线程可用时,取出请求对象执行 I/O 操作,任务完成以后归还线程,并把这个完成的事件放到任务队列的尾部,等待事件循环,当主线程再次循环到该事件时,就直接处理并返回给上层调用;
4.2 缓存
根据二八原则,80% 的请求其实访问的是 20% 的资源,我们可以将频繁访问的资源缓存起来,如果用户访问被缓存起来的资源就直接返回缓存的版本,这就是 Web 开发中经常遇到的缓存。
缓存服务器就是缓存的最常见应用之一,也是复用资源的一种常用手段。缓存服务器的示意图如下:
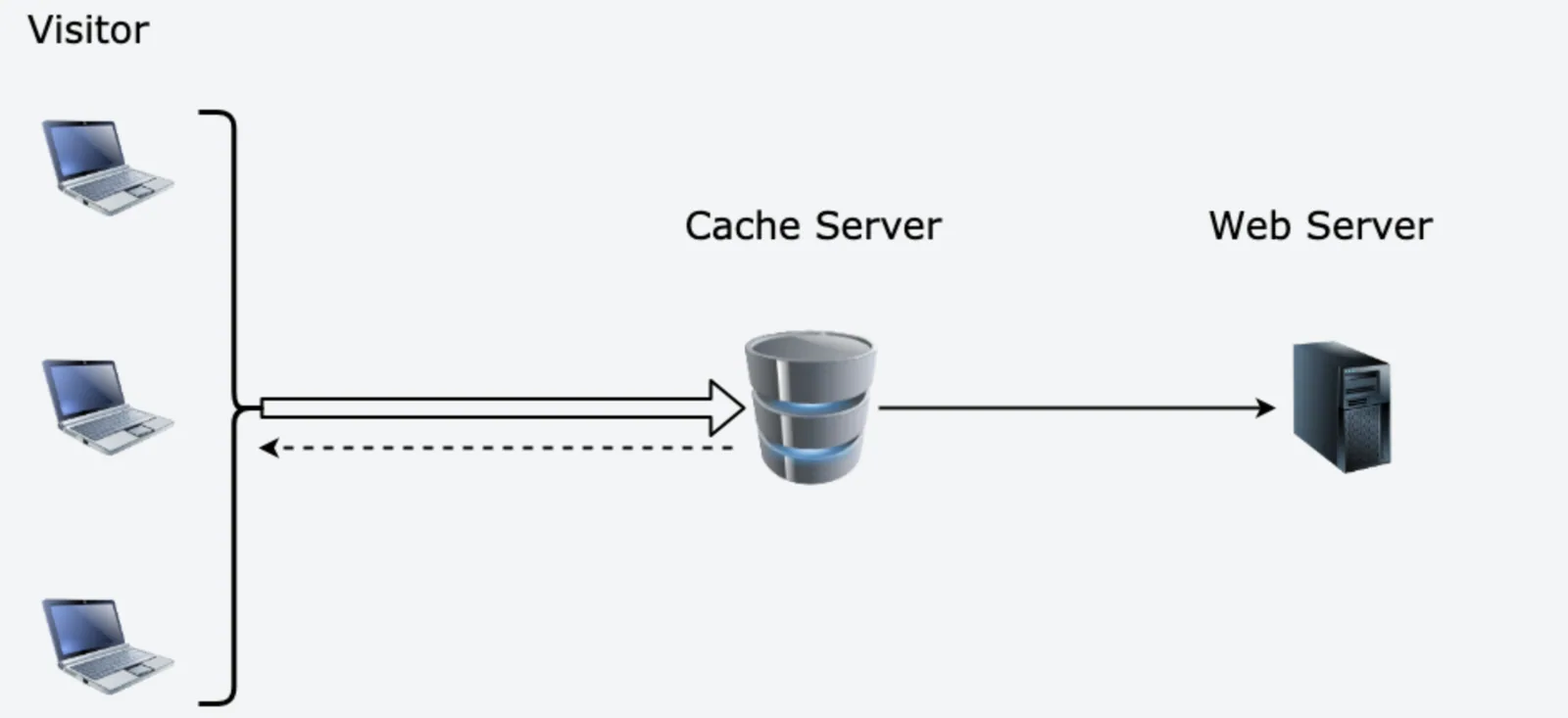
- 缓存服务器位于访问者与业务服务器之间,对业务服务器来说,减轻了压力,减小了负载,提高了数据查询的性能。对用户来说,提升了网页打开速度,优化了体验。
- 缓存技术用的非常多,不仅仅用在缓存服务器上,浏览器本地也有缓存,查询的 DNS 也有缓存,包括我们的电脑 CPU 上,也有缓存硬件。
4.3 连接池
我们知道对数据库进行操作需要先创建一个数据库连接对象,然后通过创建好的数据库连接来对数据库进行 CRUD(增删改查)操作。如果访问量不大,对数据库的 CRUD 操作就不多,每次访问都创建连接并在使用完销毁连接就没什么,但是如果访问量比较多,并发的要求比较高时,频繁创建和销毁连接就比较消耗资源了。
- 这时,可以不销毁连接,一直使用已创建的连接,就可以避免频繁创建销毁连接的损耗了。但是有个问题,一个连接同一时间只能做一件事,某使用者(一般是线程)正在使用时,其他使用者就不可以使用了,所以如果只创建一个不关闭的连接显然不符合要求,我们需要创建多个不关闭的连接。
- 这就是连接池的来源,创建多个数据库连接,当有调用的时候直接在创建好的连接中拿出来使用,使用完毕之后将连接放回去供其他调用者使用。
- 我们以
Node.js中mysql模块的连接池应用为例,看看后端一般是如何使用数据库连接池的。在 Node.js 中使用mysql创建单个连接,一般这样使用:
var mysql = require('mysql')
var connection = mysql.createConnection({ // 创建数据库连接
host: 'localhost',
user: 'root', // 用户名
password: '123456', // 密码
database: 'db', // 指定数据库
port: '3306' // 端口号
})
// 连接回调,在回调中增删改查
connection.connect(...)
// 关闭连接
connection.end(...)
在 Node.js 中使用 mysql 模块的连接池创建连接:
var mysql = require('mysql')
var pool = mysql.createPool({ // 创建数据库连接池
host: 'localhost',
user: 'root', // 用户名
password: '123456', // 密码
database: 'db', // 制定数据库
port: '3306' // 端口号
})
// 从连接池中获取一个连接,进行增删改查
pool.getConnection(function(err, connection) {
// ... 数据库操作
connection.release() // 将连接释放回连接池中
})
// 关闭连接池
pool.end()
- 一般连接池在初始化的时候,都会自动打开
n个连接,称为连接预热。如果这n个连接都被使用了,再从连接池中请求新的连接时,会动态地隐式创建额外连接,即自动扩容。如果扩容后的连接池一段时间后有不少连接没有被调用,则自动缩容,适当释放空闲连接,增加连接池中连接的使用效率。在连接失效的时候,自动抛弃无效连接。在系统关闭的时候,自动释放所有连接。为了维持连接池的有效运转和避免连接池无限扩容,还会给连接池设置最大最小连接数。 - 这些都是连接池的功能,可以看到连接池一般可以根据当前使用情况自动地进行缩容和扩容,来进行连接池资源的最优化,和连接池连接的复用效率最大化。这些连接池的功能点,看着是不是和之前驾考例子的优化过程有点似曾相识呢~
- 在实际项目中,除了数据库连接池外,还有
HTTP连接池。使用HTTP连接池管理长连接可以复用HTTP连接,省去创建TCP连接的3次握手和关闭TCP连接的4次挥手的步骤,降低请求响应的时间。
连接池某种程度也算是一种缓冲池,只不过这种缓冲池是专门用来管理连接的。
4.4 字符常量池
很多语言的引擎为了减少字符串对象的重复创建,会在内存中维护有一个特殊的内存,这个内存就叫字符常量池。当创建新的字符串时,引擎会对这个字符串进行检查,与字符常量池中已有的字符串进行比对,如果存在有相同内容的字符串,就直接将引用返回,否则在字符常量池中创建新的字符常量,并返回引用。
似于
Java、C#这些语言,都有字符常量池的机制。JavaScript 有多个引擎,以 Chrome 的 V8 引擎为例,V8 在把 JavaScript 编译成字节码过程中就引入了字符常量池这个优化手段,这就是为什么很多 JavaScript 的书籍都提到了 JavaScript 中的字符串具有不可变性,因为如果内存中的字符串可变,一个引用操作改变了字符串的值,那么其他同样的字符串也会受到影响。
可以引用《JavaScript 高级程序设计》中的话解释一下:
ECMAScript 中的字符串是不可变的,也就是说,字符串一旦创建,它们的值就不能改变。要改变某个变量保存的字符串,首先要销毁原来的字符串,然后再用另一个包含新值的字符串填充该变量。
字符常量池也是复用资源的一种手段,只不过这种手段通常用在编译器的运行过程中,通常开发(搬砖)过程用不到,了解即可。
5. 享元模式的优缺点
享元模式的优点:
- 由于减少了系统中的对象数量,提高了程序运行效率和性能,精简了内存占用,加快运行速度;
- 外部状态相对独立,不会影响到内部状态,所以享元对象能够在不同的环境被共享;
享元模式的缺点:
- 引入了共享对象,使对象结构变得复杂;
- 共享对象的创建、销毁等需要维护,带来额外的复杂度(如果需要把共享对象维护起来的话);
6. 享元模式的适用场景
- 如果一个程序中大量使用了相同或相似对象,那么可以考虑引入享元模式;
- 如果使用了大量相同或相似对象,并造成了比较大的内存开销;
- 对象的大多数状态可以被转变为外部状态;
- 剥离出对象的外部状态后,可以使用相对较少的共享对象取代大量对象;
- 在一些程序中,如果引入享元模式对系统的性能和内存的占用影响不大时,比如目标对象不多,或者场景比较简单,则不需要引入,以免适得其反。
7. 其他相关模式
- 享元模式和单例模式、工厂模式、组合模式、策略模式、状态模式等等经常会一起使用。
7.1 享元模式和工厂模式、单例模式
- 在区分出不同种类的外部状态后,创建新对象时需要选择不同种类的共享对象,这时就可以使用工厂模式来提供共享对象,在共享对象的维护上,经常会采用单例模式来提供单实例的共享对象。
7.2 享元模式和组合模式
- 在使用工厂模式来提供共享对象时,比如某些时候共享对象中的某些状态就是对象不需要的,可以引入组合模式来提升自定义共享对象的自由度,对共享对象的组成部分进一步归类、分层,来实现更复杂的多层次对象结构,当然系统也会更难维护。
7.3 享元模式和策略模式
策略模式中的策略属于一系列功能单一、细粒度的细粒度对象,可以作为目标对象来考虑引入享元模式进行优化,但是前提是这些策略是会被频繁使用的,如果不经常使用,就没有必要了。
适配器模式
- 适配器模式(Adapter Pattern)又称包装器模式,将一个类(对象)的接口(方法、属性)转化为用户需要的另一个接口,解决类(对象)之间接口不兼容的问题。
- 主要功能是进行转换匹配,目的是复用已有的功能,而不是来实现新的接口。也就是说,访问者需要的功能应该是已经实现好了的,不需要适配器模式来实现,适配器模式主要是负责把不兼容的接口转换成访问者期望的格式而已。
1. 你曾见过的适配器模式
- 现实生活中我们会遇到形形色色的适配器,最常见的就是转接头了,比如不同规格电源接口的转接头、iPhone 手机的 3.5 毫米耳机插口转接头、DP/miniDP/HDMI/DVI/VGA 等视频转接头、电脑、手机、ipad 的电源适配器,都是属于适配器的范畴。
- 还有一个比较典型的翻译官场景,比如老板张三去国外谈合作,带了个翻译官李四,那么李四就是作为讲不同语言的人之间交流的适配器 ?,老板张三的话的内容含义没有变化,翻译官将老板的话转换成国外客户希望的形式。
在类似场景中,这些例子有以下特点:
- 旧有接口格式已经不满足现在的需要;
- 通过增加适配器来更好地使用旧有接口;
2. 适配器模式的实现
我们可以实现一下电源适配器的例子,一开始我们使用的中国插头标准:
var chinaPlug = {
type: '中国插头',
chinaInPlug() {
console.log('开始供电')
}
}
chinaPlug.chinaInPlug()
// 输出:开始供电
但是我们出国旅游了,到了日本,需要增加一个日本插头到中国插头的电源适配器,来将我们原来的电源线用起来:
var chinaPlug = {
type: '中国插头',
chinaInPlug() {
console.log('开始供电')
}
}
var japanPlug = {
type: '日本插头',
japanInPlug() {
console.log('开始供电')
}
}
/* 日本插头电源适配器 */
function japanPlugAdapter(plug) {
return {
chinaInPlug() {
return plug.japanInPlug()
}
}
}
japanPlugAdapter(japanPlug).chinaInPlug()
// 输出:开始供电
由于适配器模式的例子太简单,如果希望看更多的实战相关应用,可以看下一个小节。
适配器模式的原理大概如下图:
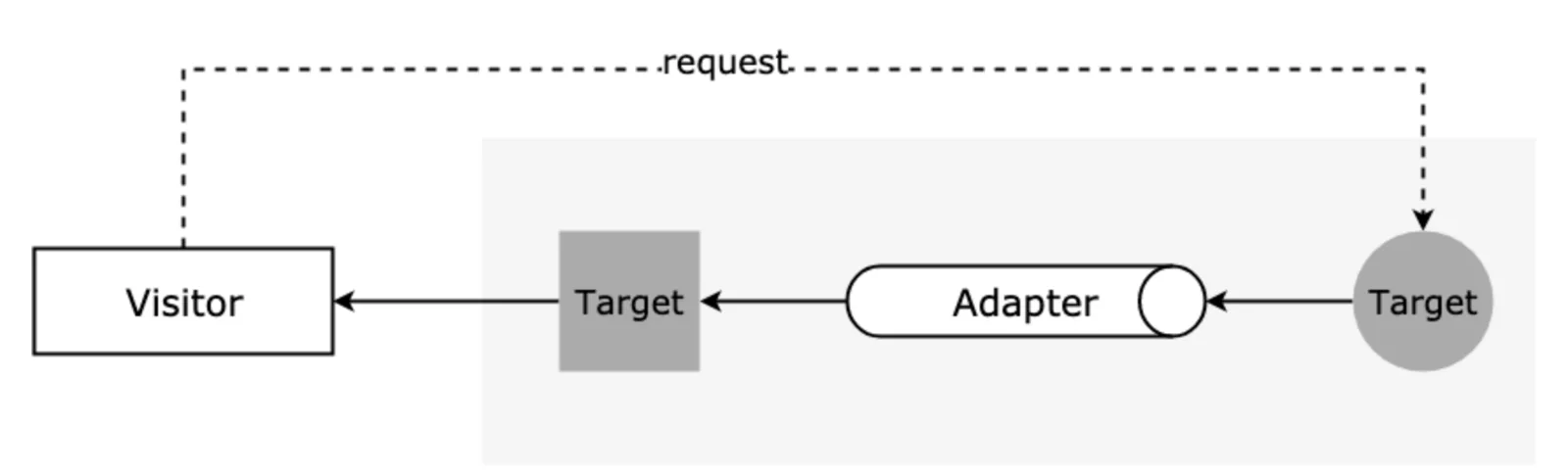
访问者需要目标对象的某个功能,但是这个对象的接口不是自己期望的,那么通过适配器模式对现有对象的接口进行包装,来获得自己需要的接口格式。
3. 适配器模式在实战中的应用
适配器模式在日常开发中还是比较频繁的,其实可能你已经使用了,但却不知道原来这就是适配器模式啊。 ?
我们可以推而广之,适配器可以将新的软件实体适配到老的接口,也可以将老的软件实体适配到新的接口,具体如何来进行适配,可以根据具体使用场景来灵活使用。
3.1 jQuery.ajax 适配 Axios
有的使用
jQuery的老项目使用$.ajax来发送请求,现在的新项目一般使用Axios,那么现在有个老项目的代码中全是$.ajax,如果你挨个修改,那么bug可能就跟地鼠一样到处冒出来让你焦头烂额,这时可以采用适配器模式来将老的使用形式适配到新的技术栈上:
/* 适配器 */
function ajax2AxiosAdapter(ajaxOptions) {
return axios({
url: ajaxOptions.url,
method: ajaxOptions.type,
responseType: ajaxOptions.dataType,
data: ajaxOptions.data
})
.then(ajaxOptions.success)
.catch(ajaxOptions.error)
}
/* 经过适配器包装 */
$.ajax = function(options) {
return ajax2AxiosAdapter(options)
}
$.ajax({
url: '/demo-url',
type: 'POST',
dataType: 'json',
data: {
name: '张三',
id: '2345'
},
success: function(data) {
console.log('访问成功!')
},
error: function(err) {
console.error('访问失败~')
}
})
可以看到老的代码表现形式依然不变,但是真正发送请求是通过新的发送方式来进行的。当然你也可以把
Axios的请求适配到$.ajax上,就看你如何使用适配器了。
补充(现代做法):新项目已基本不再用
$.ajax,而是直接使用浏览器原生fetch或Axios。即便如此,适配器思想依旧高频出现——典型做法是用 Axios 拦截器(axios.interceptors.request/response)统一改写出入参,或封装一层request()把后端不同风格的响应({code,data,msg}等)适配成前端统一结构。在 TypeScript 项目里,还会用「DTO → ViewModel」的映射函数把后端数据形状适配到前端组件需要的形状,本质都是适配器模式。
3.2 业务数据适配
- 在实际项目中,我们经常会遇到树形数据结构和表形数据结构的转换,比如全国省市区结构、公司组织结构、军队编制结构等等。以公司组织结构为例,在历史代码中,后端给了公司组织结构的树形数据,在以后的业务迭代中,会增加一些要求非树形结构的场景。比如增加了将组织维护起来的功能,因此就需要在新增组织的时候选择上级组织,在某个下拉菜单中选择这个新增组织的上级菜单。或者增加了将人员归属到某一级组织的需求,需要在某个下拉菜单中选择任一级组织。
- 在这些业务场景中,都需要将树形结构平铺开,但是我们又不能直接将旧有的树形结构状态进行修改,因为在项目别的地方已经使用了老的树形结构状态,这时我们可以引入适配器来将老的数据结构进行适配:
/* 原来的树形结构 */
const oldTreeData = [
{
name: '总部',
place: '一楼',
children: [
{ name: '财务部', place: '二楼' },
{ name: '生产部', place: '三楼' },
{
name: '开发部', place: '三楼', children: [
{
name: '软件部', place: '四楼', children: [
{ name: '后端部', place: '五楼' },
{ name: '前端部', place: '七楼' },
{ name: '技术支持部', place: '六楼' }]
}, {
name: '硬件部', place: '四楼', children: [
{ name: 'DSP部', place: '八楼' },
{ name: 'ARM部', place: '二楼' },
{ name: '调试部', place: '三楼' }]
}]
}
]
}
]
/* 树形结构平铺 */
function treeDataAdapter(treeData, lastArrayData = []) {
treeData.forEach(item => {
if (item.children) {
treeDataAdapter(item.children, lastArrayData)
}
const { name, place } = item
lastArrayData.push({ name, place })
})
return lastArrayData
}
treeDataAdapter(oldTreeData)
// 返回平铺的组织结构
增加适配器后,就可以将原先状态的树形结构转化为所需的结构,而并不改动原先的数据,也不对原来使用旧数据结构的代码有所影响。
3.3 Vue 计算属性
Vue中的计算属性也是一个适配器模式的实例,以官网的例子为例,我们可以一起来理解一下:
<template>
<div id="example">
<p>Original message: "{{ message }}"</p> <!-- Hello -->
<p>Computed reversed message: "{{ reversedMessage }}"</p> <!-- olleH -->
</div>
</template>
<script type='text/javascript'>
export default {
name: 'demo',
data() {
return {
message: 'Hello'
}
},
computed: {
reversedMessage: function() {
return this.message.split('').reverse().join('')
}
}
}
</script>
旧有
data中的数据不满足当前的要求,通过计算属性的规则来适配成我们需要的格式,对原有数据并没有改变,只改变了原有数据的表现形式。
4. 源码中的适配器模式
Axios是比较热门的网络请求库,在浏览器中使用的时候,Axios的用来发送请求的adapter本质上是封装浏览器提供的API XMLHttpRequest,我们可以看看源码中是如何封装这个API的,为了方便观看,进行了一些省略:
module.exports = function xhrAdapter(config) {
return new Promise(function dispatchXhrRequest(resolve, reject) {
var requestData = config.data
var requestHeaders = config.headers
var request = new XMLHttpRequest()
// 初始化一个请求
request.open(config.method.toUpperCase(),
buildURL(config.url, config.params, config.paramsSerializer), true)
// 设置最大超时时间
request.timeout = config.timeout
// readyState 属性发生变化时的回调
request.onreadystatechange = function handleLoad() { ... }
// 浏览器请求退出时的回调
request.onabort = function handleAbort() { ... }
// 当请求报错时的回调
request.onerror = function handleError() { ... }
// 当请求超时调用的回调
request.ontimeout = function handleTimeout() { ... }
// 设置HTTP请求头的值
if ('setRequestHeader' in request) {
request.setRequestHeader(key, val)
}
// 跨域的请求是否应该使用证书
if (config.withCredentials) {
request.withCredentials = true
}
// 响应类型
if (config.responseType) {
request.responseType = config.responseType
}
// 发送请求
request.send(requestData)
})
}
可以看到这个模块主要是对请求头、请求配置和一些回调的设置,并没有对原生的
API有改动,所以也可以在其他地方正常使用。这个适配器可以看作是对XMLHttpRequest的适配,是用户对Axios调用层到原生XMLHttpRequest这个 API 之间的适配层。
源码可以参见 Github 仓库: axios/lib/adapters/xhr.js
5. 适配器模式的优缺点
适配器模式的优点:
- 已有的功能如果只是接口不兼容,使用适配器适配已有功能,可以使原有逻辑得到更好的复用,有助于避免大规模改写现有代码;
- 可扩展性良好,在实现适配器功能的时候,可以调用自己开发的功能,从而方便地扩展系统的功能;
- 灵活性好,因为适配器并没有对原有对象的功能有所影响,如果不想使用适配器了,那么直接删掉即可,不会对使用原有对象的代码有影响;
- 适配器模式的缺点:会让系统变得零乱,明明调用 A,却被适配到了 B,如果系统中这样的情况很多,那么对可阅读性不太友好。如果没必要使用适配器模式的话,可以考虑重构,如果使用的话,可以考虑尽量把文档完善。
6. 适配器模式的适用场景
- 当你想用已有对象的功能,却想修改它的接口时,一般可以考虑一下是不是可以应用适配器模式。
- 如果你想要使用一个已经存在的对象,但是它的接口不满足需求,那么可以使用适配器模式,把已有的实现转换成你需要的接口;
- 如果你想创建一个可以复用的对象,而且确定需要和一些不兼容的对象一起工作,这种情况可以使用适配器模式,然后需要什么就适配什么;
7. 其他相关模式
适配器模式和代理模式、装饰者模式看起来比较类似,都是属于包装模式,也就是用一个对象来包装另一个对象的模式,他们之间的异同在代理模式中已经详细介绍了,这里再简单对比一下。
7.1 适配器模式与代理模式
- 适配器模式: 提供一个不一样的接口,由于原来的接口格式不能用了,提供新的接口以满足新场景下的需求;
- 代理模式: 提供一模一样的接口,由于不能直接访问目标对象,找个代理来帮忙访问,使用者可以就像访问目标对象一样来访问代理对象;
7.2 适配器模式、装饰者模式与代理模式
- 适配器模式: 功能不变,只转换了原有接口访问格式;
- 装饰者模式: 扩展功能,原有功能不变且可直接使用;
- 代理模式: 原有功能不变,但一般是经过限制访问的;
装饰者模式
装饰者模式 (Decorator Pattern)又称装饰器模式,在不改变原对象的基础上,通过对其添加属性或方法来进行包装拓展,使得原有对象可以动态具有更多功能。
本质是功能动态组合,即动态地给一个对象添加额外的职责,就增加功能角度来看,使用装饰者模式比用继承更为灵活。好处是有效地把对象的核心职责和装饰功能区分开,并且通过动态增删装饰去除目标对象中重复的装饰逻辑。
1. 你曾见过的装饰者模式
- 相信大家都有过房屋装修的经历,当毛坯房建好的时候,已经可以居住了,虽然不太舒适。一般我们自己住当然不会住毛坯,因此我们还会通水电、墙壁刷漆、铺地板、家具安装、电器安装等等步骤,让房屋渐渐具有各种各样的特性,比如墙壁刷漆和铺地板之后房屋变得更加美观,有了家具居住变得更加舒适,但这些额外的装修并没有影响房屋是用来居住的这个基本功能,这就是装饰的作用。
- 再比如现在我们经常喝的奶茶,除了奶茶之外,还可以添加珍珠、波霸、椰果、仙草、香芋等等辅料,辅料的添加对奶茶的饮用并无影响,奶茶喝起来还是奶茶的味道,只不过辅料的添加让这杯奶茶的口感变得更多样化。
- 生活中类似的场景还有很多,比如去咖啡厅喝咖啡,点了杯摩卡之后我们还可以选择添加糖、冰块、牛奶等等调味品,给咖啡添加特别的口感和风味,但这些调味品的添加并没有影响咖啡的基本性质,不会因为添加了调味品,咖啡就变成奶茶。
在类似场景中,这些例子有以下特点:
- 装饰不影响原有的功能,原有功能可以照常使用;
- 装饰可以增加多个,共同给目标对象添加额外功能;
2. 实例的代码实现
我们可以使用 JavaScript 来将装修房子的例子实现一下:
/* 毛坯房 - 目标对象 */
function OriginHouse() {}
OriginHouse.prototype.getDesc = function() {
console.log('毛坯房')
}
/* 搬入家具 - 装饰者 */
function Furniture(house) {
this.house = house
}
Furniture.prototype.getDesc = function() {
this.house.getDesc()
console.log('搬入家具')
}
/* 墙壁刷漆 - 装饰者 */
function Painting(house) {
this.house = house
}
Painting.prototype.getDesc = function() {
this.house.getDesc()
console.log('墙壁刷漆')
}
var house = new OriginHouse()
house = new Furniture(house)
house = new Painting(house)
house.getDesc()
// 输出: 毛坯房 搬入家具 墙壁刷漆
使用 ES6 的 Class 语法:
/* 毛坯房 - 目标对象 */
class OriginHouse {
getDesc() {
console.log('毛坯房')
}
}
/* 搬入家具 - 装饰者 */
class Furniture {
constructor(house) {
this.house = house
}
getDesc() {
this.house.getDesc()
console.log('搬入家具')
}
}
/* 墙壁刷漆 - 装饰者 */
class Painting {
constructor(house) {
this.house = house
}
getDesc() {
this.house.getDesc()
console.log('墙壁刷漆')
}
}
let house = new OriginHouse()
house = new Furniture(house)
house = new Painting(house)
house.getDesc()
// 输出: 毛坯房 搬入家具 墙壁刷漆
是不是感觉很麻烦,装饰个功能这么复杂?我们 JSer 大可不必走这一套面向对象花里胡哨的,毕竟 JavaScript 的优点就是灵活:
/* 毛坯房 - 目标对象 */
var originHouse = {
getDesc() {
console.log('毛坯房 ')
}
}
/* 搬入家具 - 装饰者 */
function furniture() {
console.log('搬入家具 ')
}
/* 墙壁刷漆 - 装饰者 */
function painting() {
console.log('墙壁刷漆 ')
}
/* 添加装饰 - 搬入家具 */
originHouse.getDesc = function() {
var getDesc = originHouse.getDesc
return function() {
getDesc()
furniture()
}
}()
/* 添加装饰 - 墙壁刷漆 */
originHouse.getDesc = function() {
var getDesc = originHouse.getDesc
return function() {
getDesc()
painting()
}
}()
originHouse.getDesc()
// 输出: 毛坯房 搬入家具 墙壁刷漆
简洁明了,且更符合前端日常使用的场景。
3. 装饰者模式的原理
装饰者模式的原理如下图:
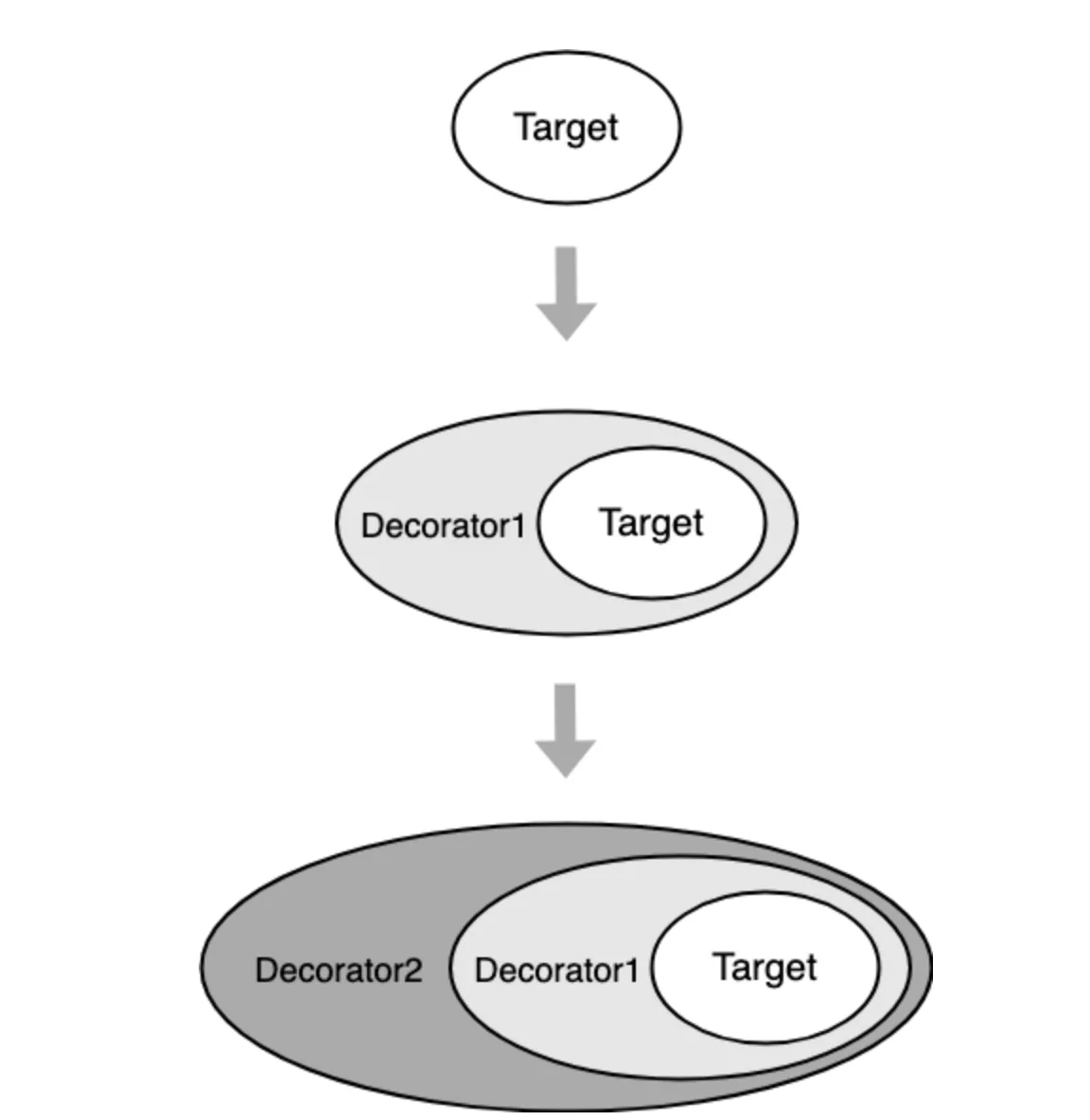
可以从上图看出,在表现形式上,装饰者模式和适配器模式比较类似,都属于包装模式。在装饰者模式中,一个对象被另一个对象包装起来,形成一条包装链,并增加了原先对象的功能。
4. 实战中的装饰者模式 4.1 给浏览器事件添加新功能
之前介绍的添加装饰器函数的方式,经常被用来给原有浏览器或
DOM绑定事件上绑定新的功能,比如在onload上增加新的事件,或在原来的事件绑定函数上增加新的功能,或者在原本的操作上增加用户行为埋点:
window.onload = function() {
console.log('原先的 onload 事件 ')
}
/* 发送埋点信息 */
function sendUserOperation() {
console.log('埋点:用户当前行为路径为 ...')
}
/* 将新的功能添加到 onload 事件上 */
window.onload = function() {
var originOnload = window.onload
return function() {
originOnload && originOnload()
sendUserOperation()
}
}()
// 输出: 原先的 onload 事件
// 输出: 埋点:用户当前行为路径为 ...
可以看到通过添加装饰函数,为
onload事件回调增加新的方法,且并不影响原本的功能,我们可以把上面的方法提取出来作为一个工具方法:
window.onload = function() {
console.log('原先的 onload 事件 ')
}
/* 发送埋点信息 */
function sendUserOperation() {
console.log('埋点:用户当前行为路径为 ...')
}
/* 给原生事件添加新的装饰方法 */
function originDecorateFn(originObj, originKey, fn) {
originObj[originKey] = function() {
var originFn = originObj[originKey]
return function() {
originFn && originFn()
fn()
}
}()
}
// 添加装饰功能
originDecorateFn(window, 'onload', sendUserOperation)
// 输出: 原先的 onload 事件
// 输出: 埋点:用户当前行为路径为 ...
4.2 TypeScript 中的装饰器
- 现在的越来越多的前端项目或
Node项目都在拥抱JavaScript的超集语言TypeScript,如果你了解过C#中的特性Attribute、Java中的注解Annotation、Python中的装饰器Decorator,那么你就不会对TypeScript中的装饰器感到陌生,下面我们简单介绍一下TypeScript中的装饰器。
TypeScript中的装饰器可以被附加到类声明、方法、访问符、属性和参数上,装饰器的类型有参数装饰器、方法装饰器、访问器或参数装饰器、参数装饰器。
TypeScript中的装饰器使用@expression这种形式,expression求值后为一个函数,它在运行时被调用,被装饰的声明信息会被做为参数传入。
多个装饰器应用使用在同一个声明上时:
- 由上至下依次对装饰器表达式求值;
- 求值的结果会被当成函数,由下至上依次调用;
那么使用官网的一个例子:
function f() {
console.log("f(): evaluated");
return function (target, propertyKey: string, descriptor: PropertyDescriptor) {
console.log("f(): called");
}
}
function g() {
console.log("g(): evaluated");
return function (target, propertyKey: string, descriptor: PropertyDescriptor) {
console.log("g(): called");
}
}
class C {
@f()
@g()
method() {}
}
// f(): evaluated
// g(): evaluated
// g(): called
// f(): called
可以看到上面的代码中,高阶函数
f与g返回了另一个函数(装饰器函数),所以f、g这里又被称为装饰器工厂,即帮助用户传递可供装饰器使用的参数的工厂。另外注意,演算的顺序是从下到上,执行的时候是从下到上的。
再比如下面一个场景
class Greeter {
greeting: string;
constructor(message: string) {
this.greeting = message;
}
greet() {
return "Hello, " + this.greeting;
}
}
for (let key in new Greeter('Jim')) {
console.log(key);
}
// 输出: greeting greet
如果我们不希望
greet被for-in循环遍历出来,可以通过装饰器的方式来方便地修改属性的属性描述符:
function enumerable(value: boolean) {
return function (target: any, propertyKey: string, descriptor: PropertyDescriptor) {
descriptor.enumerable = value;
};
}
class Greeter {
greeting: string;
constructor(message: string) {
this.greeting = message;
}
@enumerable(false)
greet() {
return "Hello, " + this.greeting;
}
}
for (let key in new Greeter('Jim')) {
console.log(key);
}
// 输出: greeting
- 这样
greet就变成不可枚举了,使用起来比较方便,对其他属性进行声明不可枚举的时候也只用在之前加一行@enumerable(false)即可,不用大费周章的Object.defineProperty(...)进行繁琐的声明了。 TypeScript的装饰器还有很多有用的用法,感兴趣的同学可以阅读一下TypeScript的Decorators官网文档 相关内容。
5. 装饰者模式的优缺点
装饰者模式的优点:
- 我们经常使用继承的方式来实现功能的扩展,但这样会给系统中带来很多的子类和复杂的继承关系,装饰者模式允许用户在不引起子类数量暴增的前提下动态地修饰对象,添加功能,装饰者和被装饰者之间松耦合,可维护性好;
- 被装饰者可以使用装饰者动态地增加和撤销功能,可以在运行时选择不同的装饰器,实现不同的功能,灵活性好;
- 装饰者模式把一系列复杂的功能分散到每个装饰器当中,一般一个装饰器只实现一个功能,可以给一个对象增加多个同样的装饰器,也可以把一个装饰器用来装饰不同的对象,有利于装饰器功能的复用;
- 可以通过选择不同的装饰者的组合,创造不同行为和功能的结合体,原有对象的代码无须改变,就可以使得原有对象的功能变得更强大和更多样化,符合开闭原则;
装饰者模式的缺点:
- 使用装饰者模式时会产生很多细粒度的装饰者对象,这些装饰者对象由于接口和功能的多样化导致系统复杂度增加,功能越复杂,需要的细粒度对象越多;
- 由于更大的灵活性,也就更容易出错,特别是对于多级装饰的场景,错误定位会更加繁琐;
6. 装饰者模式的适用场景
- 如果不希望系统中增加很多子类,那么可以考虑使用装饰者模式;
- 需要通过对现有的一组基本功能进行排列组合而产生非常多的功能时,采用继承关系很难实现,这时采用装饰者模式可以很好实现;
- 当对象的功能要求可以动态地添加,也可以动态地撤销,可以考虑使用装饰者模式;
7. 其他相关模式 7.1 装饰者模式与适配器模式
装饰者模式和适配器模式都是属于包装模式,然而他们的意图有些不一样:
- 装饰者模式: 扩展功能,原有功能还可以直接使用,一般可以给目标对象多次叠加使用多个装饰者;
- 适配器模式: 功能不变,但是转换了原有接口的访问格式,一般只给目标对象使用一次;
7.2 装饰者模式与组合模式
这两个模式有相似之处,都涉及到对象的递归调用,从某个角度来说,可以把装饰者模式看做是只有一个组件的组合模式。
- 装饰者模式: 动态地给对象增加功能;
- 组合模式: 管理组合对象和叶子对象,为它们提供一致的操作接口给客户端,方便客户端的使用;
7.3 装饰者模式与策略模式
装饰者模式和策略模式都包含有许多细粒度的功能模块,但是他们的使用思路不同:
- 装饰者模式: 可以递归调用,使用多个功能模式,功能之间可以叠加组合使用;
- 策略模式: 只有一层选择,选择某一个功能;
外观模式
外观模式 (Facade Pattern)又叫门面模式,定义一个将子系统的一组接口集成在一起的高层接口,以提供一个一致的外观。外观模式让外界减少与子系统内多个模块的直接交互,从而减少耦合,让外界可以更轻松地使用子系统。本质是封装交互,简化调用。
外观模式在源码中使用很多,具体可以参考后文中源码阅读部分。
1. 你曾见过的外观模式
最近这些年无人机很流行,特别是大疆的旋翼无人机。旋翼无人机的种类也很多,四旋翼、六旋翼、八旋翼、十六旋翼甚至是共轴双桨旋翼机,他们因为结构不同而各自有一套原理类似,但实现细节不同的旋翼控制方式。
- 如果用户需要把每种旋翼的控制原理弄清楚,那么门槛就太高了,所以无人机厂商会把具体旋翼控制的细节封装起来,用户所要接触的只是手上的遥控器,无论什么类型的无人机,遥控器的控制方式都一样,前后左右上下和左转右转。
- 对于使用者来说,遥控器就相当于是无人机系统的外观,使用者只要操纵遥控器就可以达到控制无人机的目的,而具体无人机内部的飞行控制器、电调(电子调速器)、电机、数字电传、陀螺仪、加速度计等等子模块之间复杂的调用关系将被封装起来,对于使用者而言不需要了解,因此也降低了使用难度。
- 类似的例子也有不少,比如常见的空调、冰箱、洗衣机、洗碗机,内部结构都并不简单,对于我们使用者而言,理解他们内部的运行机制的门槛比较高,但是理解遥控器/控制面板上面寥寥几个按钮就相对容易的多,这就是外观模式的意义。
在类似场景中,这些例子有以下特点:
- 一个统一的外观为复杂的子系统提供一个简单的高层功能接口;
- 原本访问者直接调用子系统内部模块导致的复杂引用关系,现在可以通过只访问这个统一的外观来避免;
2. 实例的代码实现
无人机系统的模块图大概如下:
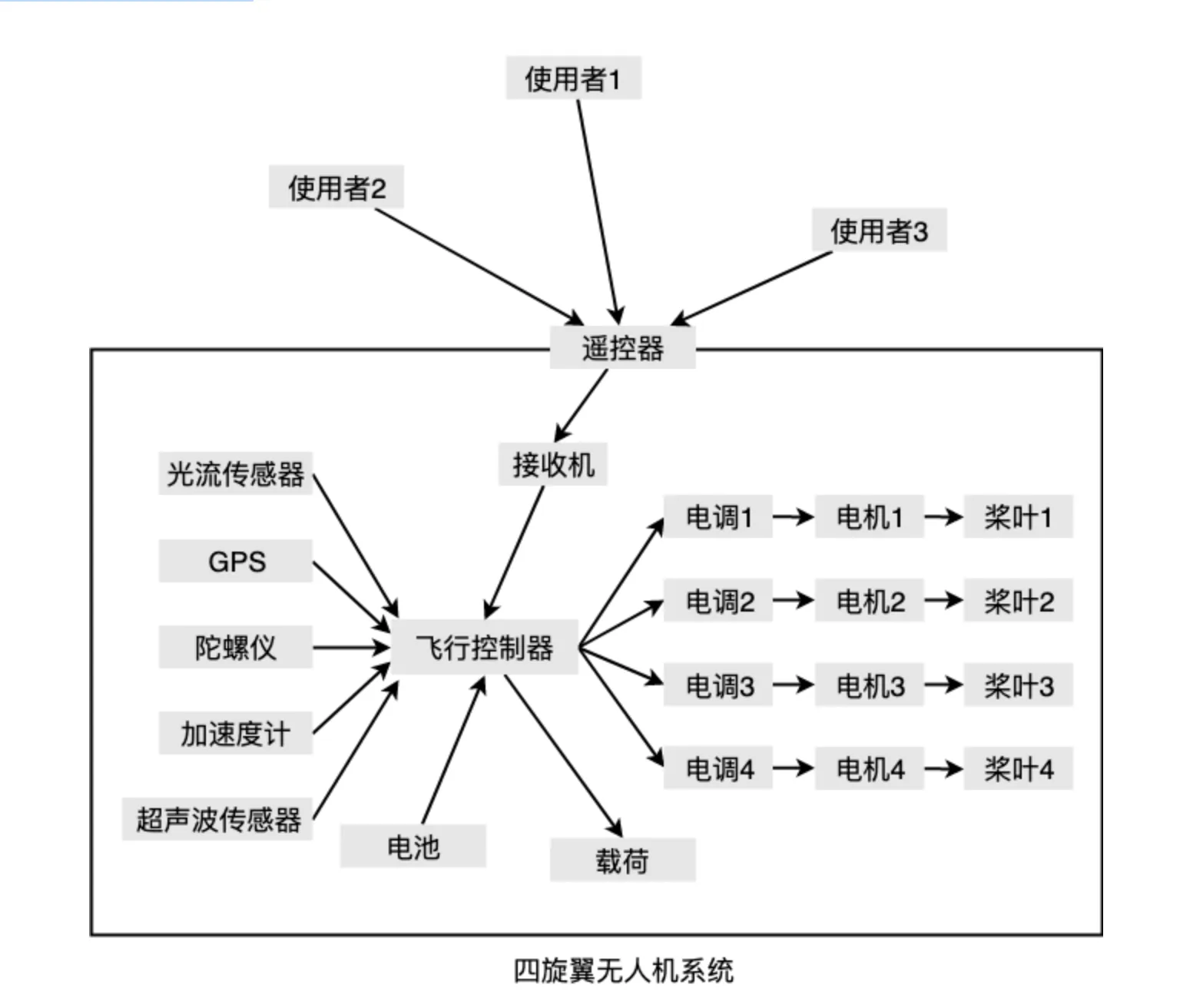
可以看到无人机系统还是比较复杂的,系统内模块众多,如果用户需要对每个模块的作用都了解的话,那就太麻烦了,有了遥控器之后,使用者只要操作摇杆,发出前进、后退等等的命令,无人机系统接受到信号之后会经过算法把计算后的指令发送到电调,控制对应电机以不同转速带动桨叶,给无人机提供所需的扭矩和升力,从而实现目标运动。
关于无人机的例子,因为子模块众多,写成代码有点太啰嗦,这里只给出一个简化版本的代码:
var uav = {
/* 电子调速器 */
diantiao1: {
up() {
console.log('电调1发送指令:电机1增大转速')
uav.dianji1.up()
},
down() {
console.log('电调1发送指令:电机1减小转速')
uav.dianji1.up()
}
},
diantiao2: {
up() {
console.log('电调2发送指令:电机2增大转速')
uav.dianji2.up()
},
down() {
console.log('电调2发送指令:电机2减小转速')
uav.dianji2.down()
}
},
diantiao3: {
up() {
console.log('电调3发送指令:电机3增大转速')
uav.dianji3.up()
},
down() {
console.log('电调3发送指令:电机3减小转速')
uav.dianji3.down()
}
},
diantiao4: {
up() {
console.log('电调4发送指令:电机4增大转速')
uav.dianji4.up()
},
down() {
console.log('电调4发送指令:电机4减小转速')
uav.dianji4.down()
}
},
/* 电机 */
dianji1: {
up() { console.log('电机1增大转速') },
down() { console.log('电机1减小转速') }
},
dianji2: {
up() { console.log('电机2增大转速') },
down() { console.log('电机2减小转速') }
},
dianji3: {
up() { console.log('电机3增大转速') },
down() { console.log('电机3减小转速') }
},
dianji4: {
up() { console.log('电机4增大转速') },
down() { console.log('电机4减小转速') }
},
/* 遥控器 */
controller: {
/* 上升 */
up() {
uav.diantiao1.up()
uav.diantiao2.up()
uav.diantiao3.up()
uav.diantiao4.up()
},
/* 前进 */
forward() {
uav.diantiao1.down()
uav.diantiao2.down()
uav.diantiao3.up()
uav.diantiao4.up()
},
/* 下降 */
down() {
uav.diantiao1.down()
uav.diantiao2.down()
uav.diantiao3.down()
uav.diantiao4.down()
},
/* 左转 */
left() {
uav.diantiao1.up()
uav.diantiao2.down()
uav.diantiao3.up()
uav.diantiao4.down()
}
}
}
/* 操纵无人机 */
uav.controller.down() // 发送下降指令
uav.controller.left() // 发送左转指令
无人机系统是比较复杂,但是可以看到无人机的操纵却比较简单,正是因为有遥控器这个外观的存在。
3. 外观模式的原理
- 正如之前无人机的例子,虽然无人机实际操控比较复杂,但是通过对 controller 这个遥控器的使用,让使用者对无人机这个系统的控制变得简单,只需调用遥控器这个外观提供的方法即可,而这个方法里封装的一系列复杂操作,则不是我们要关注的重点。
- 从中就可以理解外观模式的意义了,遥控器作为无人机系统的功能出口,降低了使用者对复杂的无人机系统使用的难度,甚至让广场上的小朋友都能玩起来了
概略图如下:
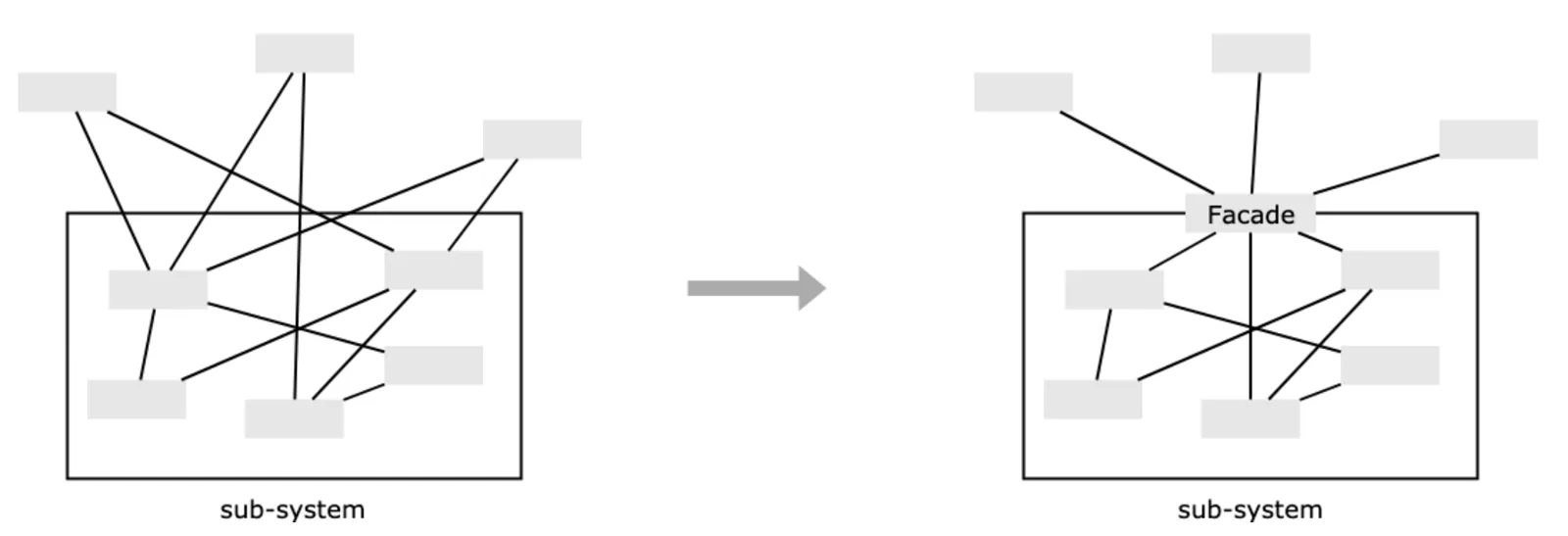
注意:外观模式一般是作为子系统的功能出口出现,使用的时候可以在其中增加新的功能,但是不推介这样做,因为外观应该是对已有功能的包装,不应在其中掺杂新的功能。
4. 实战中的外观模式 4.1 函数参数重载
有一种情况,比如某个函数有多个参数,其中一个参数可以传递也可以不传递,你当然可以直接弄两个接口,但是使用函数参数重载的方式,可以让使用者获得更大的自由度,让两个使用上基本类似的方法获得统一的外观。
function domBindEvent(nodes, type, selector, fn) {
if (fn === undefined) {
fn = selector
selector = null
}
// ... 剩下相关逻辑
}
domBindEvent(nodes, 'click', '#div1', fn)
domBindEvent(nodes, 'click', fn)
- 这种方式在一些工具库或者框架提供的多功能方法上经常得到使用,特别是在通用 API 的某些参数可传可不传的时候。
- 参数重载之后的函数在使用上会获得更大的自由度,而不必重新创建一个新的
API,这在Vue、React、jQuery、Lodash等库中使用非常频繁。
4.2 抹平浏览器兼容性问题
外观模式经常被用于
JavaScript的库中,封装一些接口用于兼容多浏览器,让我们可以间接调用我们封装的外观,从而屏蔽了浏览器差异,便于使用。
比如经常用的兼容不同浏览器的事件绑定方法:
function addEvent(element, type, fn) {
if (element.addEventListener) { // 支持 DOM2 级事件处理方法的浏览器
element.addEventListener(type, fn, false)
} else if (element.attachEvent) { // 不支持 DOM2 级但支持 attachEvent
element.attachEvent('on' + type, fn)
} else {
element['on' + type] = fn // 都不支持的浏览器
}
}
var myInput = document.getElementById('myinput')
addEvent(myInput, 'click', function() {
console.log('绑定 click 事件')
})
- 下面一个小节我们可以看看 jQuery 的源码是如何进行事件绑定的。
- 除了事件绑定之外,在抹平浏览器兼容性的其他问题上我们也经常使用外观模式:
// 移除 DOM 上的事件
function removeEvent(element, type, fn) {
if (element.removeEventListener) {
element.removeEventListener(type, fn, false)
} else if (element.detachEvent) {
element.detachEvent('on' + type, fn)
} else {
element['on' + type] = null
}
}
// 获取样式
function getStyle(obj, styleName) {
if (window.getComputedStyle) {
var styles = getComputedStyle(obj, null)[styleName]
} else {
var styles = obj.currentStyle[styleName]
}
return styles
}
// 阻止默认事件
var preventDefault = function(event) {
if (event.preventDefault) {
event.preventDefault()
} else { // IE 下
event.returnValue = false
}
}
// 阻止事件冒泡
var cancelBubble = function(event) {
if (event.stopPropagation) {
event.stopPropagation()
} else { // IE 下
event.cancelBubble = true
}
}
通过将处理不同浏览器兼容性问题的过程封装成一个外观,我们在使用的时候可以直接使用外观方法即可,在遇到兼容性问题的时候,这个外观方法自然帮我们解决,方便又不容易出错。
5. 源码中的外观模式 5.1 Vue 源码中的函数参数重载
Vue提供的一个创建元素的方法createElement就使用了函数参数重载,使得使用者在使用这个参数的时候很灵活:
export function createElement(
context,
tag,
data,
children,
normalizationType,
alwaysNormalize
) {
if (Array.isArray(data) || isPrimitive(data)) { // 参数的重载
normalizationType = children
children = data
data = undefined
}
// ...
}
createElement方法里面对第三个参数data进行了判断,如果第三个参数的类型是array、string、number、boolean中的一种,那么说明是createElement(tag [, data], children, ...)这样的使用方式,用户传的第二个参数不是data,而是children。data这个参数是包含模板相关属性的数据对象,如果用户没有什么要设置,那这个参数自然不传,不使用函数参数重载的情况下,需要用户手动传递null或者undefined之类,参数重载之后,用户对data这个参数可传可不传,使用自由度比较大,也很方便。createElement方法的源码参见 Github 链接vue/src/core/vdom/create-element.js
5.2 Lodash 源码中的函数参数重载
Lodash的 range 方法的 API 为_.range([start=0], end, [step=1]),这就很明显使用了参数重载,这个方法调用了一个内部函数createRange:
function createRange(fromRight) {
return (start, end, step) => {
// ...
if (end === undefined) {
end = start
start = 0
}
// ...
}
}
意思就是,如果没有传第二个参数,那么就把传入的第一个参数作为 end,并把 start 置为默认值。
createRange 方法的源码参见 Github 链接 lodash/.internal/createRange.js
5.3 jQuery 源码中的函数参数重载
函数参数重载在源码中使用比较多,jQuery 中也有大量使用,比如
on、off、bind、one、load、ajaxPrefilter等方法,这里以off方法为例,该方法在选择元素上移除一个或多个事件的事件处理函数。源码如下:
off: function (types, selector, fn) {
// ...
if (selector === false || typeof selector === 'function') {
// ( types [, fn] ) 的使用方式
fn = selector
selector = undefined
}
// ...
}
可以看到如果传入第二个参数为
false或者是函数的时候,就是off(types [, fn])的使用方式。
off方法的源码参见 Github 链接jquery/src/event.js
再比如 load 方法的源码:
jQuery.fn.load = function(url, params, callback) {
// ...
if (isFunction(params)) {
callback = params
params = undefined
}
// ...
}
- 可以看到
jQuery对第二个参数进行了判断,如果是函数,就是load(url [, callback])的使用方式。 load方法的源码参见 Github 链接jquery/src/ajax/load.js
5.4 jQuery 源码中的外观模式
当我们使用
jQuery的$(document).ready(...)来给浏览器加载事件添加回调时,jQuery会使用源码中的bindReady方法:
bindReady: function() {
// ...
// Mozilla, Opera and webkit 支持
if (document.addEventListener) {
document.addEventListener('DOMContentLoaded', DOMContentLoaded, false)
// A fallback to window.onload, that will always work
window.addEventListener('load', jQuery.ready, false)
// 如果使用了 IE 的事件绑定形式
} else if (document.attachEvent) {
document.attachEvent('onreadystatechange', DOMContentLoaded)
// A fallback to window.onload, that will always work
window.attachEvent('onload', jQuery.ready)
}
// ...
}
- 通过这个方法,
jQuery帮我们将不同浏览器下的不同绑定形式隐藏起来,从而简化了使用。 bindReady 方法的源码参见 Github 链接jquery/src/core.js
除了屏蔽浏览器兼容性问题之外,jQuery 还有其他的一些其他外观模式的应用:
- 比如修改
css的时候可以$('p').css('color', 'red'),也可以$('p').css('width', 100),对不同样式的操作被封装到同一个外观方法中,极大地方便了使用,对不同样式的特殊处理(比如设置width的时候不用加px)也一同被封装了起来。 - 源码参见 Github 链接
jquery/src/css.js - 再比如
jQuery的ajax的API$.ajax(url [, settings]),当我们在设置以JSONP的形式发送请求的时候,只要传入dataType: 'jsonp'设置,jQuery会进行一些额外操作帮我们启动JSONP流程,并不需要使用者手动添加代码,这些都被封装在$.ajax()这个外观方法中了。
源码参见 Github 链接 jquery/src/ajax/jsonp.js
5.5 Axios 源码中的外观模式
Axios可以使用在不同环境中,那么在不同环境中发送HTTP请求的时候会使用不同环境中的特有模块,Axios这里是使用外观模式来解决这个问题的:
function getDefaultAdapter() {
// ...
if (typeof process !== 'undefined' && Object.prototype.toString.call(process) === '[object process]') {
// Nodejs 中使用 HTTP adapter
adapter = require('./adapters/http');
} else if (typeof XMLHttpRequest !== 'undefined') {
// 浏览器使用 XHR adapter
adapter = require('./adapters/xhr');
}
// ...
}
这个方法进行了一个判断,如果在
Nodejs的环境中则使用Nodejs的HTTP模块来发送请求,在浏览器环境中则使用XMLHTTPRequest这个浏览器API。
getDefaultAdapter方法源码参见 Github 链接axios/lib/defaults.js
6. 外观模式的优缺点
外观模式的优点:
- 访问者不需要再了解子系统内部模块的功能,而只需和外观交互即可,使得访问者对子系统的使用变得简单,符合最少知识原则,增强了可移植性和可读性;
- 减少了与子系统模块的直接引用,实现了访问者与子系统中模块之间的松耦合,增加了可维护性和可扩展性;
- 通过合理使用外观模式,可以帮助我们更好地划分系统访问层次,比如把需要暴露给外部的功能集中到外观中,这样既方便访问者使用,也很好地隐藏了内部的细节,提升了安全性;
外观模式的缺点:
- 不符合开闭原则,对修改关闭,对扩展开放,如果外观模块出错,那么只能通过修改的方式来解决问题,因为外观模块是子系统的唯一出口;
- 不需要或不合理的使用外观会让人迷惑,过犹不及;
7. 外观模式的适用场景
- 维护设计粗糙和难以理解的遗留系统,或者系统非常复杂的时候,可以为这些系统设置外观模块,给外界提供清晰的接口,以后新系统只需与外观交互即可;
- 你写了若干小模块,可以完成某个大功能,但日后常用的是大功能,可以使用外观来提供大功能,因为外界也不需要了解小模块的功能;
- 团队协作时,可以给各自负责的模块建立合适的外观,以简化使用,节约沟通时间;
- 如果构建多层系统,可以使用外观模式来将系统分层,让外观模块成为每层的入口,简化层间调用,松散层间耦合;
8. 其他相关模式 8.1 外观模式与中介者模式
- 外观模式: 封装子使用者对子系统内模块的直接交互,方便使用者对子系统的调用;
- 中介者模式: 封装子系统间各模块之间的直接交互,松散模块间的耦合;
8.2 外观模式与单例模式
有时候一个系统只需要一个外观,比如之前举的
Axios的HTTP模块例子。这时我们可以将外观模式和单例模式可以一起使用,把外观实现为单例。
组合模式
组合模式 (Composite Pattern)又叫整体-部分模式,它允许你将对象组合成树形结构来表现整体- 部分层次结构,让使用者可以以一致的方式处理组合对象以及部分对象
1. 你曾见过的组合模式
大家电脑里的文件夹结构相比很熟悉了,文件夹下面可以有子文件夹,也可以有文件,子文件夹下面还可以有文件夹和文件,以此类推,共同组成了一个文件树,结构如下:
Folder 1
├── Folder 2
│ ├── File 1.txt
│ ├── File 2.txt
│ └── File 3.txt
└── Folder 3
├── File 4.txt
├── File 5.txt
└── File 6.txt
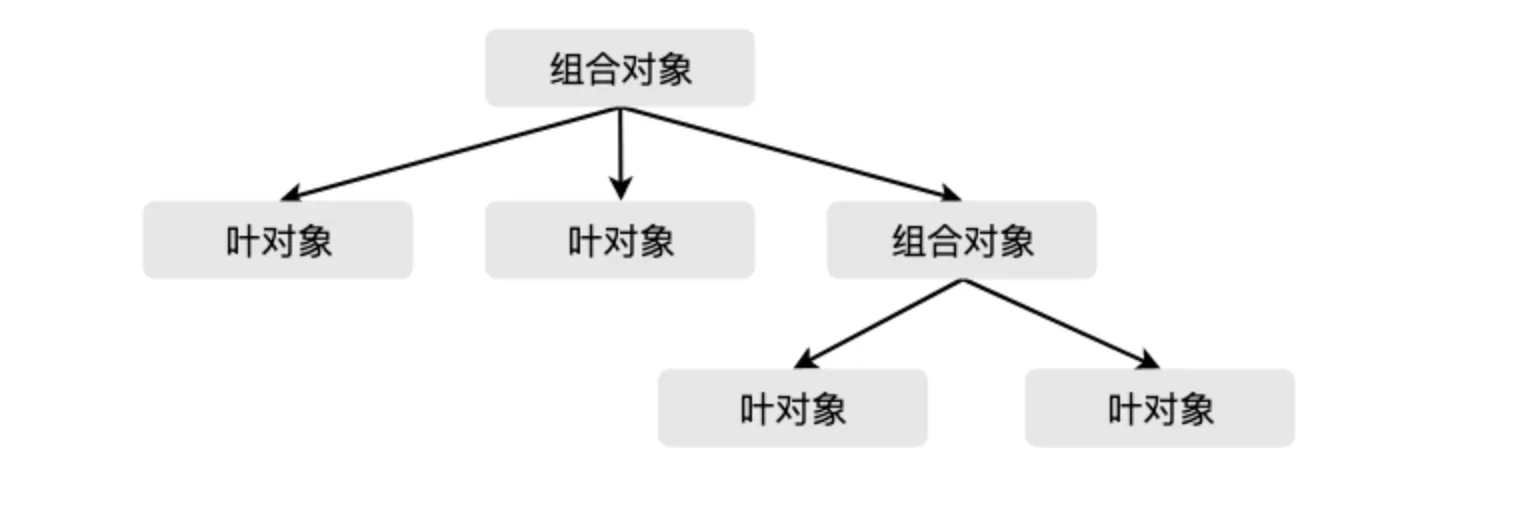
文件夹是树形结构的容器节点,容器节点可以继续包含其他容器节点,像树枝上还可以有其他树枝一样;也可以包含文件,不再增加新的层级,就像树的叶子一样处于末端,因此被称为叶节点。本文中,叶节点又称为叶对象,容器节点因为可以包含容器节点和非容器节点,又称为组合对象。
- 类似这样的结构还有公司的组织层级,比如企业下面可以有部门,部门有部门员工和科室,科室可以有科室员工和团队,团队下面又可以有团队员工和组,依次类推,共同组成完整的企业。还有生活中的容器,比如柜子可以直接放东西,也可以放盆,盆里可以放东西也可以放碗,以此类推。甚至我们的家庭结构也属于这种结构,祖父家庭有父亲家庭、伯伯家庭、叔叔家庭、姑姑家庭等,父亲家庭又有哥哥家庭、弟弟家庭,这也是很典型的整体-部分层次的结构。
- 当我们在某个文件夹下搜索某个文件的时候,通常我们希望搜索的结果包含组合对象的所有子孙对象;开家族会议的时候,开会的命令会被传达到家族中的每一个成员;领导希望我们 996 的时候,只要跟部门领导说一声,部门领导就会通知所有的员工来修福报,无论你是下属哪个组织的,都跑不掉…😅
在类似的场景中,有以下特点:
- 结构呈整体-部分的树形关系,整体部分一般称为组合对象,组合对象下还可以有组合对象和叶对象;
- 组合对象和叶对象有一致的接口和数据结构,以保证操作一致;
- 请求从树的最顶端往下传递,如果当前处理请求的对象是叶对象,叶对象自身会对请求作出相应的处理;如果当前处理的是组合对象,则遍历其下的子节点(叶对象),将请求继续传递给这些子节点;
2. 实例的代码实现
我们可以使用 JavaScript 来将之前的文件夹例子实现一下。
在本地一个「电影」文件夹下有两个子文件夹「漫威英雄电影」和「DC英雄电影」,分别各自有一些电影文件,我们要做的就是在这个电影文件夹里找大于 2G 的电影文件,无论是在这个文件夹下还是在子文件夹下,并输出它的文件名和文件大小。
/* 创建文件夹 */
var createFolder = function(name) {
return {
name: name,
_children: [],
/* 在文件夹下增加文件或文件夹 */
add(fileOrFolder) {
this._children.push(fileOrFolder)
},
/* 扫描方法 */
scan(cb) {
this._children.forEach(function(child) {
child.scan(cb)
})
}
}
}
/* 创建文件 */
var createFile = function(name, size) {
return {
name: name,
size: size,
/* 在文件下增加文件,应报错 */
add() {
throw new Error('文件下面不能再添加文件')
},
/* 执行扫描方法 */
scan(cb) {
cb(this)
}
}
}
var foldMovies = createFolder('电影')
// 创建子文件夹,并放入根文件夹
var foldMarvelMovies = createFolder('漫威英雄电影')
foldMovies.add(foldMarvelMovies)
var foldDCMovies = createFolder('DC英雄电影')
foldMovies.add(foldDCMovies)
// 为两个子文件夹分别添加电影
foldMarvelMovies.add(createFile('钢铁侠.mp4', 1.9))
foldMarvelMovies.add(createFile('蜘蛛侠.mp4', 2.1))
foldMarvelMovies.add(createFile('金刚狼.mp4', 2.3))
foldMarvelMovies.add(createFile('黑寡妇.mp4', 1.9))
foldMarvelMovies.add(createFile('美国队长.mp4', 1.4))
foldDCMovies.add(createFile('蝙蝠侠.mp4', 2.4))
foldDCMovies.add(createFile('超人.mp4', 1.6))
console.log('size 大于2G的文件有:')
foldMovies.scan(function(item) {
if (item.size > 2) {
console.log('name:' + item.name + ' size:' + item.size + 'GB')
}
})
// size 大于2G的文件有:
// name:蜘蛛侠.mp4 size:2.1GB
// name:金刚狼.mp4 size:2.3GB
// name:蝙蝠侠.mp4 size:2.4GB
作为灵活的 JavaScript,我们还可以使用链模式来进行改造一下,让我们添加子文件更加直观和方便。对链模式还不熟悉的同学可以看一下后面有一篇单独介绍链模式的文章~
/* 创建文件夹 */
const createFolder = function(name) {
return {
name: name,
_children: [],
/* 在文件夹下增加文件或文件夹 */
add(...fileOrFolder) {
this._children.push(...fileOrFolder)
return this
},
/* 扫描方法 */
scan(cb) {
this._children.forEach(child => child.scan(cb))
}
}
}
/* 创建文件 */
const createFile = function(name, size) {
return {
name: name,
size: size,
/* 在文件下增加文件,应报错 */
add() {
throw new Error('文件下面不能再添加文件')
},
/* 执行扫描方法 */
scan(cb) {
cb(this)
}
}
}
const foldMovies = createFolder('电影')
.add(
createFolder('漫威英雄电影')
.add(createFile('钢铁侠.mp4', 1.9))
.add(createFile('蜘蛛侠.mp4', 2.1))
.add(createFile('金刚狼.mp4', 2.3))
.add(createFile('黑寡妇.mp4', 1.9))
.add(createFile('美国队长.mp4', 1.4)),
createFolder('DC英雄电影')
.add(createFile('蝙蝠侠.mp4', 2.4))
.add(createFile('超人.mp4', 1.6))
)
console.log('size 大于2G的文件有:')
foldMovies.scan(item => {
if (item.size > 2) {
console.log(`name:${ item.name } size:${ item.size }GB`)
}
})
// size 大于2G的文件有:
// name:蜘蛛侠.mp4 size:2.1GB
// name:金刚狼.mp4 size:2.3GB
// name:蝙蝠侠.mp4 size:2.4GB
上面的代码比较 JavaScript 特色,如果我们使用传统的类呢,也是可以实现的,下面使用 ES6 的 class 语法来改写一下:
/* 文件夹类 */
class Folder {
constructor(name, children) {
this.name = name
this.children = children
}
/* 在文件夹下增加文件或文件夹 */
add(...fileOrFolder) {
this.children.push(...fileOrFolder)
return this
}
/* 扫描方法 */
scan(cb) {
this.children.forEach(child => child.scan(cb))
}
}
/* 文件类 */
class File {
constructor(name, size) {
this.name = name
this.size = size
}
/* 在文件下增加文件,应报错 */
add(...fileOrFolder) {
throw new Error('文件下面不能再添加文件')
}
/* 执行扫描方法 */
scan(cb) {
cb(this)
}
}
const foldMovies = new Folder('电影', [
new Folder('漫威英雄电影', [
new File('钢铁侠.mp4', 1.9),
new File('蜘蛛侠.mp4', 2.1),
new File('金刚狼.mp4', 2.3),
new File('黑寡妇.mp4', 1.9),
new File('美国队长.mp4', 1.4)]),
new Folder('DC英雄电影', [
new File('蝙蝠侠.mp4', 2.4),
new File('超人.mp4', 1.6)])
])
console.log('size 大于2G的文件有:')
foldMovies.scan(item => {
if (item.size > 2) {
console.log(`name:${ item.name } size:${ item.size }GB`)
}
})
// size 大于2G的文件有:
// name:蜘蛛侠.mp4 size:2.1GB
// name:金刚狼.mp4 size:2.3GB
// name:蝙蝠侠.mp4 size:2.4GB
在传统的语言中,为了保证叶对象和组合对象的外观一致,还会让他们实现同一个抽象类或接口。
3. 组合模式的概念
- 组合模式定义的包含组合对象和叶对象的层次结构,叶对象可以被组合成更复杂的组合对象,而这个组合对象又可以被组合,这样不断地组合下去。
- 在实际使用时,任何用到叶对象的地方都可以使用组合对象了。使用者可以不在意到底处理的节点是叶对象还是组合对象,也就不用写一些判断语句,让客户可以一致地使用组合结构的各节点,这就是所谓面向接口编程,从而减少耦合,便于扩展和维护。
组合模式的示意图如下:
4. 实战中的组合模式
类似于组合模式的结构其实我们经常碰到,比如浏览器的 DOM 树,从
<html/>根节点到<head/>、<body/>、<style/>等节点,而<body/>节点又可以有<div/>、<span/>、<p/>、<a/>等等节点,这些节点下面还可以有节点,而且这些节点的操作方式有的也比较类似。
我们可以借用上面示例代码的例子,方便地创建一个 DOM 树,由于浏览器 API 的返回值不太友好,因此我们稍微改造一下;
const createElement = ({ tag, attr, children }) => {
const node = tag
? document.createElement(tag)
: document.createTextNode(attr.text)
tag && Object.keys(attr)
.forEach(key => node.setAttribute(key, attr[key]))
children && children
.forEach(child =>
node.appendChild(createElement.call(null, child)))
return node
}
const ulElement = createElement({
tag: 'ul',
attr: { id: 'data-list' },
children: [
{
tag: 'li',
attr: { class: 'data-item' },
children: [{ attr: { text: 'li-item 1' } }]
},
{
tag: 'li',
attr: { class: 'data-item' },
children: [{ attr: { text: 'li-item 2' } }]
},
{
tag: 'li',
attr: { class: 'data-item' },
children: [{ attr: { text: 'li-item 3' } }]
}
]
})
// 输出:
// <ul id='data-list'>
// <li class='data-item'>li-item 1</li>
// <li class='data-item'>li-item 2</li>
// <li class='data-item'>li-item 3</li>
// </ul>
另外,之前的代码中添加文件的方式是不是很眼熟 😏,
Vue/React里创建元素节点的方法createElement也是类似这样使用,来组装元素节点:
// Vue
createElement('h3', { class: 'main-title' }, [
createElement('img', { class: 'avatar', attrs: { src: '../avatar.jpg' } }),
createElement('p', { class: 'user-desc' }, '长得帅老的快,长得丑活得久')
])
// React
React.createElement('h3', { className: 'user-info' },
React.createElement('img', { src: '../avatar.jpg', className: 'avatar' }),
React.createElement('p', { className: 'user-desc' }, '长得帅老的快,长得丑活得久')
)
类似的,
Vue中的虚拟DOM树,也是这样的结构:
{
tagName: 'ul', // 节点标签名
props: { // 属性
id: 'data-list'
},
children: [ // 节点的子节点
{
tagName: 'li',
props: { class: 'data-item' },
children: ['li-item 1']
},
{
tagName: 'li',
props: { class: 'data-item' },
children: ['li-item 2']
}, {
tagName: 'li',
props: { class: 'data-item' },
children: ['li-item 3']
}]
}
这样的虚拟 DOM 树,会被渲染成:
<ul id='data-list'>
<li class='data-item'>li-item 1</li>
<li class='data-item'>li-item 2</li>
<li class='data-item'>li-item 3</li>
</ul>
- 虚拟
DOM树中的每个虚拟DOM都是VNode类的实例,因此具有基本统一的外观,在操作时对父节点和子节点的操作是一致的,这也是组合模式的思想。 - 浏览器的
DOM树、Vue的虚拟DOM树等可以说和组织模式形似,也就是具有整体-部分的层次结构,但是在操作传递方面,没有组合模式所定义的特性。 - 这个特性就是职责链模式的特性,组合模式天生具有职责链,当请求组合模式中的组合对象时,请求会顺着父节点往子节点传递,直到遇到可以处理这个请求的节点,也就是叶节点。
5. 组合模式的优缺点 组合模式的优点:
- 由于组合对象和叶对象具有同样的接口,因此调用的是组合对象还是叶对象对使用者来说没有区别,使得使用者面向接口编程;
- 如果想在组合模式的树中增加一个节点比较容易,在目标组合对象中添加即可,不会影响到其他对象,对扩展友好,符合开闭原则,利于维护;
组合模式的缺点:
- 增加了系统复杂度,如果树中对象不多,则不一定需要使用;
- 如果通过组合模式创建了太多的对象,那么这些对象可能会让系统负担不起;
6. 组合模式的适用场景
- 如果对象组织呈树形结构就可以考虑使用组合模式,特别是如果操作树中对象的方法比较类似时;
- 使用者希望统一对待树形结构中的对象,比如用户不想写一堆 if-else 来处理树中的节点时,可以使用组合模式;
7. 其他相关模式 7.1 组合模式和职责链模式
正如前文所说,组合模式是天生实现了职责链模式的。
- 组合模式: 请求在组合对象上传递,被深度遍历到组合对象的所有子孙叶节点具体执行;
- 职责链模式: 实现请求的发送者和接受者之间的解耦,把多个接受者组合起来形成职责链,请求在链上传递,直到有接受者处理请求为止;
7.2 组合模式和迭代器模式
组合模式可以结合迭代器模式一起使用,在遍历组合对象的叶节点的时候,可以使用迭代器模式来遍历。
7.3 组合模式和命令模式
命令模式里有一个用法「宏命令」,宏命令就是组合模式和命令模式一起使用的结果,是组合模式组装而成