一、基础篇
this、new、bind、call、apply
1. this 指向的类型
刚开始学习 JavaScript 的时候,
this总是最能让人迷惑,下面我们一起看一下在 JavaScript 中应该如何确定 this 的指向。this是在函数被调用时确定的,它的指向完全取决于函数调用的地方,而不是它被声明的地方(除箭头函数外)。当一个函数被调用时,会创建一个执行上下文,它包含函数在哪里被调用(调用栈)、函数的调用方式、传入的参数等信息,this 就是这个记录的一个属性,它会在函数执行的过程中被用到。
this 在函数的指向有以下几种场景:
- 作为构造函数被 new 调用;
- 作为对象的方法使用;
- 作为函数直接调用;
- 被
call、apply、bind调用; - 箭头函数中的
this;
1.1 new 绑定
函数如果作为构造函数使用
new调用时,this绑定的是新创建的构造函数的实例。
function Foo() {
console.log(this)
}
var bar = new Foo() // 输出: Foo 实例,this 就是 bar
实际上使用
new调用构造函数时,会依次执行下面的操作:
- 创建一个新对象;
- 构造函数的
prototype被赋值给这个新对象的__proto__; - 将新对象赋给当前的
this; - 执行构造函数;
- 如果函数没有返回其他对象,那么
new表达式中的函数调用会自动返回这个新对象,如果返回的不是对象将被忽略;
1.2 显式绑定
通过
call、apply、bind我们可以修改函数绑定的this,使其成为我们指定的对象。通过这些方法的第一个参数我们可以显式地绑定this。
function foo(name, price) {
this.name = name
this.price = price
}
function Food(category, name, price) {
foo.call(this, name, price) // call 方式调用
// foo.apply(this, [name, price]) // apply 方式调用
this.category = category
}
new Food('食品', '汉堡', '5块钱')
// 浏览器中输出: {name: "汉堡", price: "5块钱", category: "食品"}
call 和 apply 的区别是 call 方法接受的是参数列表,而 apply 方法接受的是一个参数数组。
func.call(thisArg, arg1, arg2, ...) // call 用法
func.apply(thisArg, [arg1, arg2, ...]) // apply 用法
而
bind方法是设置this为给定的值,并返回一个新的函数,且在调用新函数时,将给定参数列表作为原函数的参数序列的前若干项。
func.bind(thisArg[, arg1[, arg2[, ...]]]) // bind 用法
举个例子:
var food = {
name: '汉堡',
price: '5块钱',
getPrice: function(place) {
console.log(place + this.price)
}
}
food.getPrice('KFC ') // 浏览器中输出: "KFC 5块钱"
var getPrice1 = food.getPrice.bind({ name: '鸡腿', price: '7块钱' }, '肯打鸡 ')
getPrice1() // 浏览器中输出: "肯打鸡 7块钱"
关于 bind 的原理,我们可以使用 apply 方法自己实现一个 bind 看一下:
// ES5 方式
Function.prototype.bind = Function.prototype.bind || function() {
var self = this
var rest1 = Array.prototype.slice.call(arguments)
var context = rest1.shift()
return function() {
var rest2 = Array.prototype.slice.call(arguments)
return self.apply(context, rest1.concat(rest2))
}
}
// ES6 方式
Function.prototype.bind = Function.prototype.bind || function(...rest1) {
const self = this
const context = rest1.shift()
return function(...rest2) {
return self.apply(context, [...rest1, ...rest2])
}
}
ES6方式用了一些ES6的知识比如rest参数、数组解构
注意: 如果你把 null 或 undefined 作为 this 的绑定对象传入 call、apply、bind,这些值在调用时会被忽略,实际应用的是默认绑定规则。
var a = 'hello'
function foo() {
console.log(this.a)
}
foo.call(null) // 浏览器中输出: "hello"
1.3 隐式绑定
函数是否在某个上下文对象中调用,如果是的话
this绑定的是那个上下文对象。
var a = 'hello'
var obj = {
a: 'world',
foo: function() {
console.log(this.a)
}
}
obj.foo() // 浏览器中输出: "world"
上面代码中,
foo方法是作为对象的属性调用的,那么此时foo方法执行时,this指向obj对象。也就是说,此时this指向调用这个方法的对象,如果嵌套了多个对象,那么指向最后一个调用这个方法的对象:
var a = 'hello'
var obj = {
a: 'world',
b:{
a:'China',
foo: function() {
console.log(this.a)
}
}
}
obj.b.foo() // 浏览器中输出: "China"
最后一个对象是
obj上的b,那么此时foo方法执行时,其中的this指向的就是b对象。
1.4 默认绑定
函数独立调用,直接使用不带任何修饰的函数引用进行调用,也是上面几种绑定途径之外的方式。非严格模式下 this 绑定到全局对象(浏览器下是
winodw,node环境是global),严格模式下this绑定到undefined(因为严格模式不允许this指向全局对象)。
var a = 'hello'
function foo() {
var a = 'world'
console.log(this.a)
console.log(this)
}
foo() // 相当于执行 window.foo()
// 浏览器中输出: "hello"
// 浏览器中输出: Window 对象
上面代码中,变量
a被声明在全局作用域,成为全局对象window的一个同名属性。函数foo被执行时,this此时指向的是全局对象,因此打印出来的a是全局对象的属性。
注意有一种情况:
var a = 'hello'
var obj = {
a: 'world',
foo: function() {
console.log(this.a)
}
}
var bar = obj.foo
bar() // 浏览器中输出: "hello"
此时
bar函数,也就是obj上的foo方法为什么又指向了全局对象呢,是因为bar方法此时是作为函数独立调用的,所以此时的场景属于默认绑定,而不是隐式绑定。这种情况和把方法作为回调函数的场景类似:
var a = 'hello'
var obj = {
a: 'world',
foo: function() {
console.log(this.a)
}
}
function func(fn) {
fn()
}
func(obj.foo) // 浏览器中输出: "hello"
- 参数传递实际上也是一种隐式的赋值,只不过这里
obj.foo方法是被隐式赋值给了函数func的形参fn,而之前的情景是自己赋值,两种情景实际上类似。这种场景我们遇到的比较多的是setTimeout和setInterval,如果回调函数不是箭头函数,那么其中的this指向的就是全局对象. - 其实我们可以把默认绑定当作是隐式绑定的特殊情况,比如上面的
bar(),我们可以当作是使用window.bar()的方式调用的,此时 bar 中的this根据隐式绑定的情景指向的就是window。
2. this 绑定的优先级
this存在多个使用场景,那么多个场景同时出现的时候,this到底应该如何指向呢。这里存在一个优先级的概念,this根据优先级来确定指向。优先级:new 绑定 > 显示绑定 > 隐式绑定 > 默认绑定
所以 this 的判断顺序:
new绑定: 函数是否在new中调用?如果是的话this绑定的是新创建的对象;- 显式绑定: 函数是否是通过
bind、call、apply调用?如果是的话,this绑定的是指定的对象; - 隐式绑定: 函数是否在某个上下文对象中调用?如果是的话,
this绑定的是那个上下文对象; - 如果都不是的话,使用默认绑定。如果在严格模式下,就绑定到
undefined,否则绑定到全局对象;
3. 箭头函数中的 this
- 箭头函数 是根据其声明的地方来决定
this的 - 箭头函数的
this绑定是无法通过call、apply、bind被修改的,且因为箭头函数没有构造函数constructor,所以也不可以使用 new 调用,即不能作为构造函数,否则会报错。
var a = 'hello'
var obj = {
a: 'world',
foo: () => {
console.log(this.a)
}
}
obj.foo() // 浏览器中输出: "hello"
4. 一个 this 的小练习
用一个小练习来实战一下:
var a = 20
var obj = {
a: 40,
foo:() => {
console.log(this.a)
function func() {
this.a = 60
console.log(this.a)
}
func.prototype.a = 50
return func
}
}
var bar = obj.foo() // 浏览器中输出: 20
bar() // 浏览器中输出: 60
new bar() // 浏览器中输出: 60
稍微解释一下:
var a = 20这句在全局变量window上创建了个属性a并赋值为20;- 首先执行的是
obj.foo(),这是一个箭头函数,箭头函数不创建新的函数作用域直接沿用语句外部的作用域,因此obj.foo()执行时箭头函数中this是全局window,首先打印出 window 上的属性 a 的值 20,箭头函数返回了一个原型上有个值为50的属性a的函数对象func给bar; - 继续执行的是
bar(),这里执行的是刚刚箭头函数返回的闭包func,其内部的this指向window,因此this.a修改了window.a的值为60并打印出来; - 然后执行的是
new bar(),根据之前的表述,new操作符会在func函数中创建一个继承了func原型的实例对象并用this指向它,随后this.a = 60又在实例对象上创建了一个属性a,在之后的打印中已经在实例上找到了属性a,因此就不继续往对象原型上查找了,所以打印出第三个60; - 如果把上面例子的箭头函数换成普通函数呢,结果会是什么样?
var a = 20
var obj = {
a: 40,
foo: function() {
console.log(this.a)
function func() {
this.a = 60
console.log(this.a)
}
func.prototype.a = 50
return func
}
}
var bar = obj.foo() // 浏览器中输出: 40
bar() // 浏览器中输出: 60
new bar() // 浏览器中输出: 60
闭包与高阶函数
1. 闭包
1.1 什么是闭包
当函数可以记住并访问所在的词法作用域时,就产生了闭包,即使函数是在当前词法作用域之外执行。
我们首先来看一个闭包的例子:
function foo() {
var a = 2
function bar() {
console.log(a)
}
return bar
}
var baz = foo()
baz() // 输出: 2
foo函数传递出了一个函数bar,传递出来的bar被赋值给baz并调用,虽然这时baz是在foo作用域外执行的,但baz在调用的时候可以访问到前面的bar函数所在的foo的内部作用域。- 由于
bar声明在foo函数内部,bar拥有涵盖foo内部作用域的闭包,使得foo的内部作用域一直存活不被回收。一般来说,函数在执行完后其整个内部作用域都会被销毁,因为JavaScript的GC(Garbage Collection)垃圾回收机制会自动回收不再使用的内存空间。但是闭包会阻止某些GC,比如本例中foo()执行完,因为返回的bar函数依然持有其所在作用域的引用,所以其内部作用域不会被回收。 - 注意: 如果不是必须使用闭包,那么尽量避免创建它,因为闭包在处理速度和内存消耗方面对性能具有负面影响。
1.2 利用闭包实现结果缓存(备忘模式)
备忘模式就是应用闭包的特点的一个典型应用。比如有个函数:
function add(a) {
return a + 1;
}
- 多次运行
add()时,每次得到的结果都是重新计算得到的,如果是开销很大的计算操作的话就比较消耗性能了,这里可以对已经计算过的输入做一个缓存。 - 所以这里可以利用闭包的特点来实现一个简单的缓存,在函数内部用一个对象存储输入的参数,如果下次再输入相同的参数,那就比较一下对象的属性,如果有缓存,就直接把值从这个对象里面取出来。
/* 备忘函数 */
function memorize(fn) {
var cache = {}
return function() {
var args = Array.prototype.slice.call(arguments)
var key = JSON.stringify(args)
return cache[key] || (cache[key] = fn.apply(fn, args))
}
}
/* 复杂计算函数 */
function add(a) {
return a + 1
}
var adder = memorize(add)
adder(1) // 输出: 2 当前: cache: { '[1]': 2 }
adder(1) // 输出: 2 当前: cache: { '[1]': 2 }
adder(2) // 输出: 3 当前: cache: { '[1]': 2, '[2]': 3 }
使用
ES6的方式会更优雅一些:
/* 备忘函数 */
function memorize(fn) {
const cache = {}
return function(...args) {
const key = JSON.stringify(args)
return cache[key] || (cache[key] = fn.apply(fn, args))
}
}
/* 复杂计算函数 */
function add(a) {
return a + 1
}
const adder = memorize(add)
adder(1) // 输出: 2 当前: cache: { '[1]': 2 }
adder(1) // 输出: 2 当前: cache: { '[1]': 2 }
adder(2) // 输出: 3 当前: cache: { '[1]': 2, '[2]': 3 }
稍微解释一下:
- 备忘函数中用
JSON.stringify把传给adder函数的参数序列化成字符串,把它当做cache的索引,将add函数运行的结果当做索引的值传递给cache,这样adder运行的时候如果传递的参数之前传递过,那么就返回缓存好的计算结果,不用再计算了,如果传递的参数没计算过,则计算并缓存fn.apply(fn, args),再返回计算的结果。 - 当然这里的实现如果要实际应用的话,还需要继续改进一下,比如:
- 缓存不可以永远扩张下去,这样太耗费内存资源,我们可以只缓存最新传入的
n个; - 在浏览器中使用的时候,我们可以借助浏览器的持久化手段,来进行缓存的持久化,比如
cookie、localStorage等; - 这里的复杂计算函数可以是过去的某个状态,比如对某个目标的操作,这样把过去的状态缓存起来,方便地进行状态回退。
- 复杂计算函数也可以是一个返回时间比较慢的异步操作,这样如果把结果缓存起来,下次就可以直接从本地获取,而不是重新进行异步请求。
注意:
cache不可以是Map,因为Map的键是使用===比较的,因此当传入引用类型值作为键时,虽然它们看上去是相等的,但实际并不是,比如[1]!==[1],所以还是被存为不同的键。
// X 错误示范
function memorize(fn) {
const cache = new Map()
return function(...args) {
return cache.get(args) || cache.set(args, fn.apply(fn, args)).get(args)
}
}
function add(a) {
return a + 1
}
const adder = memorize(add)
adder(1) // 2 cache: { [ 1 ] => 2 }
adder(1) // 2 cache: { [ 1 ] => 2, [ 1 ] => 2 }
adder(2) // 3 cache: { [ 1 ] => 2, [ 1 ] => 2, [ 2 ] => 3 }
2. 高阶函数
高阶函数就是输入参数里有函数,或者输出是函数的函数。
2.1 函数作为参数
如果你用过
setTimeout、setInterval、ajax请求,那么你已经用过高阶函数了,这是我们最常看到的场景:回调函数,因为它将函数作为参数传递给另一个函数。
比如
ajax请求中,我们通常使用回调函数来定义请求成功或者失败时的操作逻辑:
$.ajax("/request/url", function(result){
console.log("请求成功!")
})
在
Array、Object、String等等基本对象的原型上有很多操作方法,可以接受回调函数来方便地进行对象操作。这里举一个很常用的Array.prototype.filter()方法,这个方法返回一个新创建的数组,包含所有回调函数执行后返回true或真值的数组元素。
var words = ['spray', 'limit', 'elite', 'exuberant', 'destruction', 'present'];
var result = words.filter(function(word) {
return word.length > 6
}) // 输出: ["exuberant", "destruction", "present"]
回调函数还有一个应用就是钩子,如果你用过 Vue 或者 React 等框架,那么你应该对钩子很熟悉了,它的形式是这样的:
function foo(callback) {
// ... 一些操作
callback()
}
2.2 函数作为返回值
另一个经常看到的高阶函数的场景是在一个函数内部输出另一个函数,比如:
function foo() {
return function bar() {}
}
主要是利用闭包来保持着作用域:
function add() {
var num = 0
return function(a) {
return num = num + a
}
}
var adder = add()
adder(1) // 输出: 1
adder(2) // 输出: 3
1. 柯里化
- 柯里化(Currying),又称部分求值(Partial Evaluation),是把接受多个参数的原函数变换成接受一个单一参数(原函数的第一个参数)的函数,并且返回一个新函数,新函数能够接受余下的参数,最后返回同原函数一样的结果。
- 核心思想是把多参数传入的函数拆成单(或部分)参数函数,内部再返回调用下一个单(或部分)参数函数,依次处理剩余的参数。
柯里化有 3 个常见作用:
- 参数复用
- 提前返回
- 延迟计算/运行
- 先来看看柯里化的通用实现:
// ES5 方式
function currying(fn) {
var rest1 = Array.prototype.slice.call(arguments)
rest1.shift()
return function() {
var rest2 = Array.prototype.slice.call(arguments)
return fn.apply(null, rest1.concat(rest2))
}
}
// ES6 方式
function currying(fn, ...rest1) {
return function(...rest2) {
return fn.apply(null, rest1.concat(rest2))
}
}
用它将一个
sayHello函数柯里化试试:
// 接上面
function sayHello(name, age, fruit) {
console.log(console.log(`我叫 ${name},我 ${age} 岁了, 我喜欢吃 ${fruit}`))
}
var curryingShowMsg1 = currying(sayHello, '小明')
curryingShowMsg1(22, '苹果') // 输出: 我叫 小明,我 22 岁了, 我喜欢吃 苹果
var curryingShowMsg2 = currying(sayHello, '小衰', 20)
curryingShowMsg2('西瓜') // 输出: 我叫 小衰,我 20 岁了, 我喜欢吃 西瓜
更高阶的用法参见:JavaScript 函数式编程技巧 - 柯里化
2. 反柯里化
- 柯里化是固定部分参数,返回一个接受剩余参数的函数,也称为部分计算函数,目的是为了缩小适用范围,创建一个针对性更强的函数。核心思想是把多参数传入的函数拆成单参数(或部分)函数,内部再返回调用下一个单参数(或部分)函数,依次处理剩余的参数。
- 而反柯里化,从字面讲,意义和用法跟函数柯里化相比正好相反,扩大适用范围,创建一个应用范围更广的函数。使本来只有特定对象才适用的方法,扩展到更多的对象。
先来看看反柯里化的通用实现吧~
// ES5 方式
Function.prototype.unCurrying = function() {
var self = this
return function() {
var rest = Array.prototype.slice.call(arguments)
return Function.prototype.call.apply(self, rest)
}
}
// ES6 方式
Function.prototype.unCurrying = function() {
const self = this
return function(...rest) {
return Function.prototype.call.apply(self, rest)
}
}
如果你觉得把函数放在 Function 的原型上不太好,也可以这样:
// ES5 方式
function unCurrying(fn) {
return function (tar) {
var rest = Array.prototype.slice.call(arguments)
rest.shift()
return fn.apply(tar, rest)
}
}
// ES6 方式
function unCurrying(fn) {
return function(tar, ...argu) {
return fn.apply(tar, argu)
}
}
下面简单试用一下反柯里化通用实现,我们将
Array上的push方法借出来给arguments这样的类数组增加一个元素:
// 接上面
var push = unCurrying(Array.prototype.push)
function execPush() {
push(arguments, 4)
console.log(arguments)
}
execPush(1, 2, 3) // 输出: [1, 2, 3, 4]
简单说,函数柯里化就是对高阶函数的降阶处理,缩小适用范围,创建一个针对性更强的函数。
function(arg1, arg2) // => function(arg1)(arg2)
function(arg1, arg2, arg3) // => function(arg1)(arg2)(arg3)
function(arg1, arg2, arg3, arg4) // => function(arg1)(arg2)(arg3)(arg4)
function(arg1, arg2, ..., argn) // => function(arg1)(arg2)…(argn)
而反柯里化就是反过来,增加适用范围,让方法使用场景更大。使用反柯里化, 可以把原生方法借出来,让任何对象拥有原生对象的方法。
obj.func(arg1, arg2) // => func(obj, arg1, arg2)
可以这样理解柯里化和反柯里化的区别:
- 柯里化是在运算前提前传参,可以传递多个参数;
- 反柯里化是延迟传参,在运算时把原来已经固定的参数或者 this 上下文等当作参数延迟到未来传递。
- 更高阶的用法参见:JavaScript 函数式编程技巧 - 反柯里化
3. 偏函数
偏函数是创建一个调用另外一个部分(参数或变量已预制的函数)的函数,函数可以根据传入的参数来生成一个真正执行的函数。其本身不包括我们真正需要的逻辑代码,只是根据传入的参数返回其他的函数,返回的函数中才有真正的处理逻辑比如:
var isType = function(type) {
return function(obj) {
return Object.prototype.toString.call(obj) === `[object ${type}]`
}
}
var isString = isType('String')
var isFunction = isType('Function')
这样就用偏函数快速创建了一组判断对象类型的方法~
偏函数和柯里化的区别:
- 柯里化是把一个接受
n个参数的函数,由原本的一次性传递所有参数并执行变成了可以分多次接受参数再执行,例如:add = (x, y, z) => x + y + z→curryAdd = x => y => z => x + y + z; - 偏函数固定了函数的某个部分,通过传入的参数或者方法返回一个新的函数来接受剩余的参数,数量可能是一个也可能是多个;
- 当一个柯里化函数只接受两次参数时,比如
curry()(),这时的柯里化函数和偏函数概念类似,可以认为偏函数是柯里化函数的退化版
ES6
1. let、const
一个显而易见特性是 let 声明的变量还可以更改,而 const 一般用来声明常量,声明之后就不能更改了:
let foo = 1;
const bar = 2;
foo = 3;
bar = 3; // 报错 TypeError
1.1 作用域差别
刚学 JavaScript 的时候,我们总是看到类似于「JavaScript 中没有块级作用域,只有函数作用域」的说法。举个例子:
var arr = [];
for (var i = 0; i < 4; i++) {
arr[i] = function () {
console.log(i)
}
}
arr[2]() // 期望值:2,输出: 4
因为
i变量是var命令声明的,var声明的变量的作用域是函数作用域,因此此时 i 变量是在全局范围内都有效,也就是说全局只有一个变量 i,每次循环只是修改同一个变量 i 的值。虽然函数的定义是在循环中进行,但是每个函数的 i 都指向这个全局唯一的变量 i。在函数执行时,for 循环已经结束,i 最终的值是 4,所以无论执行数组里的哪个函数,结果都是 i 最终的值 4。
ES6 引入的 let、const 声明的变量是仅在块级作用域中有效:
var arr = [];
for (let i = 0; i < 4; i++) {
arr[i] = function () {
console.log(i)
}
}
arr[2]() // 期望值:2,输出: 2
这个代码中,变量
i是let声明的,也就是说i只在本轮循环有效,所以每次循环i都是一个新的变量,最后输出的是 2。
那如果我们不使用
ES6的let、const怎样去实现?可以使用函数的参数来缓存变量的值,让闭包在执行时索引到的变量为函数作用域中缓存的函数参数变量值:
var arr = []
for (var i = 0; i < 4; i++) {
(function(j) {
arr[i] = function(j) {
console.log(j)
}
})(i)
}
arr[2]() // 输出: 2
这个做法归根结底还是使用函数作用域来变相实现块级作用域,事实上 Babel 编译器也是使用这个做法,我们来看看 Babel 编译的结果:
// 编译前,ES6 语法
var arr = [];
for (let i = 0; i < 4; i++) {
arr[i] = function () {
console.log(i)
}
}
arr[2]() // 输出: 2
// 编译后,Babel 编译后的 ES5 语法
"use strict";
var arr = [];
var _loop = function _loop(i) {
arr[i] = function () {
console.log(i);
};
};
for (var i = 0; i < 4; i++) {
_loop(i);
}
arr[2](); // 输出: 2
可以看到 Babel 编译后的代码,也是使用了这个做法。
1.2 不存在变量提升
var命令声明的变量会发生变量提升的现象,也就是说变量在声明之前使用,其值为undefined,function声明的函数也是有这样的特性。而let、const命令声明的变量没有变量提升,如果在声明之前使用,会直接报错。
// var 命令存在变量提升
console.log(tmp) // undefined
var tmp = 1
console.log(tmp) // 1
// let、const 命令不存在变量提升
console.log(boo) // 报错 ReferenceError
let boo = 2
1.3 暂时性死区
在一个块级作用域中对一个变量使用
let、const声明前,该变量都是不可使用的,这被称为暂时性死区(Temporal Dead Zone, TDZ):
tmp = 'asd';
if (true) {
// 虽然在这之前定义了一个全局变量 tmp,但是块内重新定义了一个 tmp
console.log(tmp); // 报错 ReferenceError
let tmp;
}
1.4 不允许重复声明
let、const命令是不允许重复声明同一个变量的:
if (true) {
let tmp;
let tmp; // 报错 SyntaxError
}
function func(arg) { // 因为已经有一个 arg 变量名的形参了
let arg;
}
func() // 报错 SyntaxError
2. 箭头函数
2.1 基本用法
ES6 中可以使用箭头函数来定义函数。下面例子中,同名函数的定义是等价的:
// 基础用法
const test1 = function (参数1, 参数2, …, 参数N) { 函数声明 }
const test1 = (参数1, 参数2, …, 参数N) => { 函数声明 }
// 当只有一个参数时,圆括号是可选的
const test2 = (单一参数) => { 函数声明 }
const test2 = 单一参数 => { 函数声明 }
// 没有参数时,圆括号不能省略
const test3 = () => { 函数声明 }
// 当函数体只是 return 一个单一表达式时,可以省略花括号和 return 关键词
const test4 = () { return 表达式(单一) }
const test4 = () => 表达式(单一)
// 函数体返回对象字面表达式时,如果省略花括号和 return 关键词,返回值需要加括号
const test5 = () => { return {foo: 'bar'} }
const test5 = () => ({foo: 'bar'}) // 输出 {foo: 'bar'}
const test6 = () => {foo: 'bar'} // 输出 undefined,大括号被识别为代码块
总结:
- 参数如果只有一个,可以不加圆括号
(); - 没有参数时,不能省略圆括号
(); - 如果函数体只返回单一表达式,那么函数体可以不使用大括号
{}和return,直接写表达式即可; - 在 3 的基础上,如果返回值是一个对象字面量,那么返回值需要加圆括号
(),避免被识别为代码块。
2.2 箭头函数中的 this
箭头函数出来之前,函数在执行时才能确定
this的指向,所以会经常出现闭包中的this指向不是期望值的情况。在以前的做法中,如果要给闭包指定this,可以用bind\call\apply,或者把this值分配给封闭的变量(一般是that)。箭头函数出来之后,给我们提供了不一样的选择。
箭头函数不会创建自己的 this,只会从自己定义位置的作用域的上一层直接继承 this。
function Person(){
this.age = 10;
setInterval(() => {
this.age++; // this 正确地指向 p 实例
}, 1000);
}
var p = new Person(); // 1s后打印出 10
另外因为箭头函数没有自己的
this指针,因此对箭头函数使用call、apply、bind时,只能传递函数,不能绑定this,它们的第一个参数将被忽略:
this.param = 1
const func1 = () => console.log(this.param)
const func2 = function() {
console.log(this.param)
}
func1.apply({ param: 2 }) // 输出: 1
func2.apply({ param: 2 }) // 输出: 2
总结一下:
- 箭头函数中的
this就是定义时所在的对象,而不是使用时所在的对象; - 无法作为构造函数,不可以使用
new命令,否则会抛错; - 箭头函数中不存在
arguments对象,但我们可以通过Rest参数来替代; - 箭头函数无法使用
yield命令,所以不能作为Generator函数; - 不可以通过
bind、call、apply绑定this,但是可以通过call、apply传递参数。
3. class 语法
在
class语法出来之前,我们一般通过上一章介绍的一些方法,来间接实现面向对象三个要素:封装、继承、多态。ES6 给我们提供了更面向对象(更OO,Object Oriented)的写法,我们可以通过class关键字来定义一个类。
基本用法:
// ES5 方式定义一个类
function Foo() { this.kind = 'foo' }
Foo.staticMethod = function() { console.log('静态方法') }
Foo.prototype.doThis = function() { console.log(`实例方法 kind:${ this.kind }`) }
// ES6 方式定义一个类
class Foo {
/* 构造函数 */
constructor() { this.kind = 'foo' }
/* 静态方法 */
static staticMethod() { console.log('静态方法') }
/* 实例方法 */
doThis() {
console.log(`实例方法 kind:${ this.kind }`)
}
}
ES6 方式实现继承:
// 接上
class Bar extends Foo {
constructor() {
super()
this.type = 'bar'
}
doThat() {
console.log(`实例方法 type:${ this.type } kind:${ this.kind }`)
}
}
const bar = new Bar()
bar.doThat() // 实例方法 type:bar kind:foo
总结一下:
static关键字声明的是静态方法,不会被实例继承,只可以直接通过类来调用;class没有变量提升,因此必须在定义之后才使用;constructor为构造函数,子类构造函数中的super代表父类的构造函数,必须执行一次,否则新建实例时会抛错;new.target一般用在构造函数中,返回new命令作用于的那个构造函数;class用extends来实现继承,子类继承父类所有实例方法和属性。
4. 解构赋值
ES6 允许按照一定方式,从数组和对象中提取值。本质上这种写法属于模式匹配,只要等号两边的模式相同,左边的变量就会被赋予相对应的值。
数组解构基本用法:
let [a, b, c] = [1, 2, 3] // a:1 b:2 c:3
let [a, [[b], c]] = [1, [[2], 3]] // a:1 b:2 c:3
let [a, , b] = [1, 2, 3] // a:1 b:3
let [a,...b] = [1, 2, 3] // a:1 b:[2, 3]
let [a, b,...c] = [1] // a:1 b:undefined c:[]
let [a, b = 4] = [null, undefined] // a:null b:4
let [a, b = 4] = [1] // a:1 b:4
let [a, b = 4] = [1, null] // a:1 b:null
- 解构不成功,变量的值为
undefined; - 解构可以指定默认值,如果被解构变量的对应位置没有值,即为空,或者值为
undefined,默认值才会生效。
对象解构基本用法:
let { a, b } = { a: 1, b: 2 } // a:1 b:2
let { c } = { a: 1, b: 2 } // c:undefined
let { c = 4 } = { a: 1, b: 2 } // c:4
let { a: c } = { a: 1, b: 2 } // c:1
let { a: c = 4, d: e = 5 } = { a: 1, b: 2 } // c:1 e:5
let { length } = [1, 2] // length:2
- 解构不成功,变量的值为
undefined; - 解构可以指定默认值,如果被解构变量严格为
undefined或为空,默认值才会生效; - 如果变量名和属性名不一致,可以赋给其它名字的变量
{a:c},实际上对象解构赋值{a}是简写{a:a},对象的解构赋值是先找到同名属性,再赋给对应的变量,真正被赋值的是后者。
5. 扩展运算符
扩展运算符和
Rest参数的形式一样...,作用相当于Rest参数的逆运算。它将一个数组转化为逗号分割的参数序列。事实上实现了迭代器(Iterator)接口的对象都可以使用扩展运算符,包括Array、String、Set、Map、NodeList、arguments等。
数组可以使用扩展运算符:
console.log(...[1, 2, 3]) // 1 2 3
console.log(1, ...[2, 3, 4], 5) // 1 2 3 4 5
[...document.querySelectorAll('div')] // [<div>, <div>, <div>]
[...[1], ...[2, 3]] // [1, 2, 3]
const arr = [1]
arr.push(...[2, 3]) // arr:[1, 2, 3]
对象也可以使用扩展运算符,通常被用来合并对象:
{...{a: 1}, ...{a: 2, b: 3}} // {a: 2, b: 3}
6. 默认参数
ES6 允许给函数的参数设置默认值,如果不传递、或者传递为 undefined 则会采用默认值:
function log(x, y = 'World') {
console.log(x, y)
}
log('Hello') // Hello World
log('Hello', undefined) // Hello World
log('Hello', 'China') // Hello China
log(undefined, 'China') // undefined China
log(, 'China') // 报错 SyntaxError
log('Hello', '') // Hello
log('Hello', null) // Hello null
注意:
- 参数不传递或者传递
undefined会让参数等于默认值,但是如果参数不是最后一个,不传递参数会报错; - 特别注意,传递
null不会让函数参数等于默认值。 - 默认参数可以和解构赋值结合使用:
function log({x, y = 'World'} = {}) {
console.log(x, y)
}
log({x: 'hello'}) // hello World
log({x: 'hello',y: 'China'}) // hello China
log({y: 'China'}) // undefined "China"
log({}) // undefined "World"
log() // undefined "World"
分析一下后两种情况:
- 传递参数为
{}时,因为被解构变量既不为空,也不是undefined,所以不会使用解构赋值的默认参数{}。虽然最终形参的赋值过程还是{x, y = 'World'} = {},但是这里等号右边的空对象是调用时传递的,而不是形参对象的默认值; - 不传参时,即被解构变量为空,那么会使用形参的默认参数
{},形参的赋值过程相当于{x, y = 'World'} = {},注意这里等号右边的空对象,是形参对象的默认值。 - 上面是给被解构变量的整体设置了一个默认值
{}。下面细化一下,给默认值{}中的每一项也设置默认值:
function log({x, y} = {x: 'yes', y: 'World'}) {
console.log(x, y)
}
log({x: 'hello'}) // hello undefined
log({x: 'hello',y: 'China'}) // hello China
log({y: 'China'}) // undefined "China"
log({}) // undefined undefined
log() // yes World
也分析一下后两种情况:
- 传递参数为
{}时,被解构变量不为空,也不为undefined,因此不使用默认参数{x, y: 'World'},形参的赋值过程相当于{x, y} = {},所以 x 与 y 都是undefined; - 不传参时,等式右边采用默认参数,形参赋值过程相当于
{x, y} = {x: 'yes', y: 'World'}。
7. Rest 参数
我们知道
arguments是类数组,没有数组相关方法。为了使用数组上的一些方法,我们需要先 用Array.prototype.slice.call(arguments)或者[...arguments]来将arguments类数组转化为数组。
ES6 允许我们通过 Rest 参数来获取函数的多余参数:
// 获取函数所有的参数,rest 为数组
function func1(...rest){ /* ... */}
// 获取函数第一个参数外其他的参数,rest 为数组
function func1(val, ...rest){ /* ... */}
注意,
Rest参数只能放在最后一个,否则会报错:
// 报错 SyntaxError: Rest 参数必须是最后一个参数
function func1(...rest, a){ /* ... */}
形参名并不必须是
rest,也可以是其它名称,使用者可以根据自己的习惯来命名
继承与原型链
JavaScript 是一种灵活的语言,兼容并包含面向对象风格、函数式风格等编程风格。我们知道面向对象风格有三大特性和六大原则,三大特性是封装、继承、多态,六大原则是单一职责原则(SRP)、开放封闭原则(OCP)、里氏替换原则(LSP)、依赖倒置原则(DIP)、接口分离原则(ISP)、最少知识原则(LKP)。
JavaScript并不是强面向对象语言,因此它的灵活性决定了并不是所有面向对象的特征都适合 JavaScript 开发,本教程将会着重介绍三大特性中的继承,和六大原则里的单一职责原则、开放封闭原则、最少知识原则
1. 原型对象链
JavaScript 内建的继承方法被称为原型对象链,又称为原型对象继承。对于一个对象,因为它继承了它的原型对象的属性,所以它可以访问到这些属性。同理,原型对象也是一个对象,它也有自己的原型对象,因此也可以继承它的原型对象的属性。
这就是原型继承链:对象继承其原型对象,而原型对象继承它的原型对象,以此类推。
2. 对象继承
使用对象字面量形式创建对象时,会隐式指定
Object.prototype为新对象的[[Prototype]]。使用Object.create()方式创建对象时,可以显式指定新对象的[[Prototype]]。该方法接受两个参数:第一个参数为新对象的[[Prototype]],第二个参数描述了新对象的属性,格式如在Object.defineProperties()中使用的一样。
// 对象字面量形式,原型被隐式地设置为 Object.prototype
var rectangle = { sizeType: '四边形' }
// Object.create() 创建,显示指定为 Object.prototype, 等价于 ↑
var rectangle = Object.create(Object.prototype, {
sizeType: {
configurable: true,
enumerable: true,
value: '四边形',
writable: true
}
})
我们可以用这个方法来实现对象继承:
var rectangle = {
sizeType: '四边形',
getSize: function() {
console.log(this.sizeType)
}
}
var square = Object.create(rectangle, {
sizeType: { value: '正方形' }
})
rectangle.getSize() // "四边形"
square.getSize() // "正方形"
console.log(rectangle.hasOwnProperty('getSize')) // true
console.log(rectangle.isPrototypeOf(square)) // true
console.log(square.hasOwnProperty('getSize')) // false
console.log('getSize' in square) // true
console.log(square.__proto__ === rectangle) // true
console.log(square.__proto__.__proto__ === Object.prototype) // true

- 对象
square继承自对象rectangle,也就继承了rectangle的sizeType属性和getSize()方法,又通过重写sizeType属性定义了一个自有属性,隐藏并替代了原型对象中的同名属性。所以rectangle.getSize()输出 「四边形」 而square.getSize()输出 「正方形」。 - 在访问一个对象的时候,JavaScript 引擎会执行一个搜索过程,如果在对象实例上发现该属性,该属性值就会被使用,如果没有发现则搜索其原型对象
[[Prototype]],如果仍然没有发现,则继续搜索该原型对象的原型对象[[Prototype]],直到继承链顶端,顶端通常是一个Object.prototype,其[[prototype]]为null。这就是原型链的查找过程。 - 可以通过
Object.create()创建[[Prototype]]为null的对象:var obj = Object.create(null)。对象obj是一个没有原型链的对象,这意味着toString()和valueOf等存在于Object原型上的方法同样不存在于该对象上,通常我们将这样创建出来的对象为纯净对象。
3. 原型链继承
- JavaScript 中的对象继承是构造函数继承的基础,几乎所有的函数都有
prototype属性(通过Function.prototype.bind方法构造出来的函数是个例外),它可以被替换和修改。 - 函数声明创建函数时,函数的
prototype属性被自动设置为一个继承自Object.prototype的对象,该对象有个自有属性constructor,其值就是函数本身。
// 构造函数
function YourConstructor() {}
// JavaScript 引擎在背后做的:
YourConstructor.prototype = Object.create(Object.prototype, {
constructor: {
configurable: true,
enumerable: true,
value: YourConstructor,
writable: true
}
})
console.log(YourConstructor.prototype.__proto__ === Object.prototype) // true
JavaScript 引擎帮你把构造函数的
prototype属性设置为一个继承自Object.prototype的对象,这意味着我们创建出来的构造函数都继承自Object.prototype。由于prototype可以被赋值和改写,所以通过改写它来改变原型链:
/* 四边形 */
function Rectangle(length, width) {
this.length = length // 长
this.width = width // 宽
}
/* 获取面积 */
Rectangle.prototype.getArea = function() {
return this.length * this.width
}
/* 获取尺寸信息 */
Rectangle.prototype.getSize = function() {
console.log(`Rectangle: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
/* 正方形 */
function Square(size) {
this.length = size
this.width = size
}
Square.prototype = new Rectangle()
Square.prototype.constructor = Square // 原本为 Rectangle,重置回 Square 构造函数
Square.prototype.getSize = function() {
console.log(`Square: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
var rect = new Rectangle(5, 10)
var squa = new Square(6)
rect.getSize() // Rectangle: 5x10,面积: 50
squa.getSize() // Square: 6x6,面积: 36
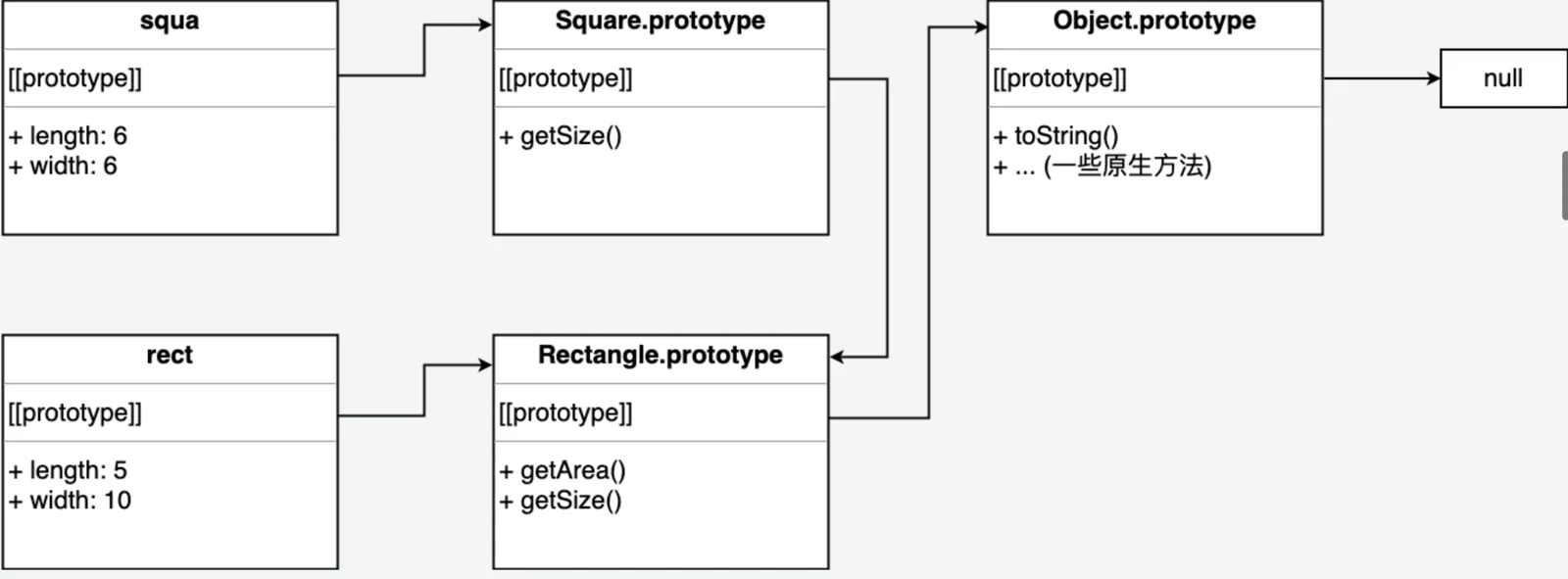
- 为什么使用
Square.prototype = new Rectangle()而不用Square.prototype = Rectangle.prototype呢。这是因为后者使得两个构造函数的prototype指向了同一个对象,当修改其中一个函数的 prototype 时,另一个函数也会受影响。 - 所以
Square构造函数的prototype属性被改写为了Rectagle的一个实例。 - 但是仍然有问题。当一个属性只存在于构造函数的
prototype上,而构造函数本身没有时,该属性会在构造函数的所有实例间共享,其中一个实例修改了该属性,其他所有实例都会受影响:
/* 四边形 */
function Rectangle(sizes) {
this.sizes = sizes
}
/* 正方形 */
function Square() {}
Square.prototype = new Rectangle([1, 2])
var squa1 = new Square() // sizes: [1, 2]
squa1.sizes.push(3) // 在 squa1 中修改了 sizes
console.log(squa1.sizes) // sizes: [1, 2, 3]
var squa2 = new Square()
console.log(squa2.sizes) // sizes: [1, 2, 3] 应该是 [1, 2],得到的是修改后的 sizes
4. 构造函数窃取
构造函数窃取又称构造函数借用、经典继承。这种技术的基本思想相当简单,即在子类型构造函数的内部调用父类构造函数。
function getArea() {
return this.length * this.width
}
/* 四边形 */
function Rectangle(length, width) {
this.length = length
this.width = width
}
/* 获取面积 */
Rectangle.prototype.getArea = getArea
/* 获取尺寸信息 */
Rectangle.prototype.getSize = function() {
console.log(`Rectangle: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
/* 正方形 */
function Square(size) {
Rectangle.call(this, size, size)
this.getArea = getArea
this.getSize = function() {
console.log(`Square: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
}
var rect = new Rectangle(5, 10)
var squa = new Square(6)
rect.getSize() // Rectangle: 5x10,面积: 50
squa.getSize() // Square: 6x6,面积: 36
- 这样的实现避免了引用类型的属性被所有实例共享的问题,在父类实例创建时还可以自定义地传参,缺点是方法都是在构造函数中定义,每次创建实例都会重新赋值一遍方法,即使方法的引用是一致的。
- 这种方式通过构造函数窃取来设置属性,模仿了那些基于类的语言的类继承,所以这通常被称为伪类继承或经典继承。
5. 组合继承
组合继承又称伪经典继承,指的是将原型链和借用构造函数的技术组合发挥二者之长的一种继承模式。其背后的思路是使用原型链实现对原型属性和方法的继承,而通过借用构造函数来实现对实例属性的继承。这样,既通过在原型上定义方法实现了函数复用,又能够保证每个实例都有它自己的属性。
/* 四边形 */
function Rectangle(length, width) {
this.length = length
this.width = width
this.color = 'red'
}
/* 获取面积 */
Rectangle.prototype.getArea = function() {
return this.length * this.width
}
/* 获取尺寸信息 */
Rectangle.prototype.getSize = function() {
console.log(`Rectangle: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
/* 正方形 */
function Square(size) {
Rectangle.call(this, size, size) // 第一次调用 Rectangle 函数
this.color = 'blue'
}
Square.prototype = new Rectangle() // 第二次调用 Rectangle 函数
Square.prototype.constructor = Square
Square.prototype.getSize = function() {
console.log(`Square: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
var rect = new Rectangle(5, 10)
var squa = new Square(6)
rect.getSize() // Rectangle: 5x10,面积: 50
squa.getSize() // Square: 6x6,面积: 36
组合继承是 JavaScript 中最常用的继承模式,但是父类构造函数被调用了两次。
6. 寄生组合式继承
/* 实现继承逻辑 */
function inheritPrototype(sub, sup) {
var prototype = Object.create(sup.prototype)
prototype.constructor = sub
sub.prototype = prototype
}
/* 四边形 */
function Rectangle(length, width) {
this.length = length
this.width = width
this.color = 'red'
}
/* 获取面积 */
Rectangle.prototype.getArea = function() {
return this.length * this.width
}
/* 获取尺寸信息 */
Rectangle.prototype.getSize = function() {
console.log(`Rectangle: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
/* 正方形 */
function Square(size) {
Rectangle.call(this, size, size) // 第一次调用 Rectangle 函数
this.color = 'blue'
}
// 实现继承
inheritPrototype(Square, Rectangle)
Square.prototype.getSize = function() {
console.log(`Square: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
var rect = new Rectangle(5, 10)
var squa = new Square(6)
rect.getSize() // Rectangle: 5x10,面积: 50
squa.getSize() // Square: 6x6,面积: 36
- 这种方式的高效率体现它只调用了一次父类构造函数,并且因此避免了在
Rectangle.prototype上面创建不必要的、多余的属性。与此同时,原型链还能保持不变。因此,还能够正常使用instanceof和isPrototypeOf。开发人员普遍认为寄生组合式继承是引用类型最理想的继承范式。 - 不过这种实现有些麻烦,推介使用组合继承和下面的 ES6 方式实现继承。
7. ES6 的 extends 方式实现继承
ES6中引入了class关键字,class之间可以通过extends关键字实现继承,这比 ES5 的通过修改原型链实现继承,要清晰、方便和语义化的多。
/* 四边形 */
class Rectangle {
constructor(length, width) {
this.length = length
this.width = width
this.color = 'red'
}
/* 获取面积 */
getArea() {
return this.length * this.width
}
/* 获取尺寸信息 */
getSize() {
console.log(`Rectangle: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
}
/* 正方形 */
class Square extends Rectangle {
constructor(size) {
super(size, size)
this.color = 'blue'
}
getSize() {
console.log(`Square: ${ this.length }x${ this.width },面积: ${ this.getArea() }`)
}
}
var rect = new Rectangle(5, 10)
var squa = new Square(6)
rect.getSize() // Rectangle: 5x10,面积: 50
squa.getSize() // Square: 6x6,面积: 36
然而并不是所有浏览器都支持
class/extends关键词,不过我们可以引入Babel来进行转译。class语法实际上也是之前语法的语法糖,用户可以把上面的代码放到 Babel 的在线编译中看看,编译出来是什么样子
补充(现代做法):截至今天,所有主流现代浏览器(含移动端)都已原生支持
class/extends,只有需要兼容 IE 等远古环境时才需 Babel 转译。需要注意class不只是语法糖:类方法默认不可枚举、类体处于严格模式、构造函数不能不加new直接调用,这些是 ES5 寄生组合继承手写实现达不到的。继承体系里还可以用static定义静态成员、#field声明真正的私有字段(旧代码常用_name约定俗成的「伪私有」,现在能用#name做到引擎级私有)。
设计原则
在前文我们介绍了面向对象三大特性之继承,本文将主要介绍面向对象六大原则中的单一职责原则(SRP)、开放封闭原则(OCP)、最少知识原则(LKP)。
设计原则是指导思想,从思想上给我们指明程序设计的正确方向,是我们在开发设计过程中应该尽力遵守的准则。而设计模式是实现手段,因此设计模式也应该遵守这些原则,或者说,设计模式就是这些设计原则的一些具体体现。要达到的目标就是高内聚低耦合,高内聚是说模块内部要高度聚合,是模块内部的关系,低耦合是说模块与模块之间的耦合度要尽量低,是模块与模块间的关系。
注意 ,遵守设计原则是好,但是过犹不及,在实际项目中我们不要刻板遵守,需要根据实际情况灵活运用
1. 单一职责原则 SRP
- 单一职责原则 (Single Responsibility Principle, SRP)是指对一个类(方法、对象,下文统称对象)来说,应该仅有一个引起它变化的原因。也就是说,一个对象只做一件事。
- 单一职责原则可以让我们对对象的维护变得简单,如果一个对象具有多个职责的话,那么如果一个职责的逻辑需要修改,那么势必会影响到其他职责的代码。如果一个对象具有多种职责,职责之间相互耦合,对一个职责的修改会影响到其他职责的实现,这就是属于模块内低内聚高耦合的情况。负责的职责越多,耦合越强,对模块的修改就越来越危险。
优点:
- 降低单个类(方法、对象)的复杂度,提高可读性和可维护性,功能之间的界限更清晰; 类(方法、对象)之间根据功能被分为更小的粒度,有助于代码的复用;
- 缺点: 增加系统中类(方法、对象)的个数,实际上也增加了这些对象之间相互联系的难度,同时也引入了额外的复杂度。
2. 开放封闭原则 OCP
开放封闭原则 (Open-Close Principle, OCP)是指一个模块在扩展性方面应该是开放的,而在更改性方面应该是封闭的,也就是对扩展开放,对修改封闭。
当需要增加需求的时候,则尽量通过扩展新代码的方式,而不是修改已有代码。因为修改已有代码,则会给依赖原有代码的模块带来隐患,因此修改之后需要把所有依赖原有代码的模块都测试一遍,修改一遍测试一遍,带来的成本很大,如果是上线的大型项目,那么代价和风险可能更高。
优点 :
- 增加可维护性,避免因为修改给系统带来的不稳定性。
3. 最少知识原则 LKP
- 最少知识原则 (Least Knowledge Principle, LKP)又称为迪米特原则 (Law of Demeter, LOD),一个对象应该对其他对象有最少的了解。
- 通俗地讲,一个类应该对自己需要耦合或调用的类知道得最少,类的内部如何实现、如何复杂都与调用者或者依赖者没关系,调用者或者依赖者只需要知道他需要的方法即可,其他的我一概不关心。类与类之间的关系越密切,耦合度越大,当一个类发生改变时,对另一个类的影响也越大。
- 通常为了减少对象之间的联系,是通过引入一个第三者来帮助进行通信,阻隔对象之间的直接通信,从而减少耦合。
优点:
- 降低类(方法、对象)之间不必要的依赖,减少耦合。
缺点:
- 类(方法、对象)之间不直接通信也会经过一个第三者来通信,那么就要权衡引入第三者带来的复杂度是否值得。