三、JavaScript相关(3/4)
71 数组去重方法总结
方法一、利用ES6 Set去重(ES6中最常用)
function unique (arr) {
return Array.from(new Set(arr))
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {}, {}]
方法二、利用for嵌套for,然后splice去重(ES5中最常用)
function unique(arr){
for(var i=0; i<arr.length; i++){
for(var j=i+1; j<arr.length; j++){
if(arr[i]==arr[j]){ //第一个等同于第二个,splice方法删除第二个
arr.splice(j,1);
j--;
}
}
}
return arr;
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "true", 15, false, undefined, NaN, NaN, "NaN", "a", {…}, {…}] //NaN和{}没有去重,两个null直接消失了
- 双层循环,外层循环元素,内层循环时比较值。值相同时,则删去这个值。
- 想快速学习更多常用的
ES6语法
方法三、利用indexOf去重
function unique(arr) {
if (!Array.isArray(arr)) {
console.log('type error!')
return
}
var array = [];
for (var i = 0; i < arr.length; i++) {
if (array .indexOf(arr[i]) === -1) {
array .push(arr[i])
}
}
return array;
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
// [1, "true", true, 15, false, undefined, null, NaN, NaN, "NaN", 0, "a", {…}, {…}] //NaN、{}没有去重
新建一个空的结果数组,
for循环原数组,判断结果数组是否存在当前元素,如果有相同的值则跳过,不相同则push进数组
方法四、利用sort()
function unique(arr) {
if (!Array.isArray(arr)) {
console.log('type error!')
return;
}
arr = arr.sort()
var arrry= [arr[0]];
for (var i = 1; i < arr.length; i++) {
if (arr[i] !== arr[i-1]) {
arrry.push(arr[i]);
}
}
return arrry;
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
// [0, 1, 15, "NaN", NaN, NaN, {…}, {…}, "a", false, null, true, "true", undefined] //NaN、{}没有去重
利用
sort()排序方法,然后根据排序后的结果进行遍历及相邻元素比对
方法五、利用对象的属性不能相同的特点进行去重
function unique(arr) {
if (!Array.isArray(arr)) {
console.log('type error!')
return
}
var arrry= [];
var obj = {};
for (var i = 0; i < arr.length; i++) {
if (!obj[arr[i]]) {
arrry.push(arr[i])
obj[arr[i]] = 1
} else {
obj[arr[i]]++
}
}
return arrry;
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "true", 15, false, undefined, null, NaN, 0, "a", {…}] //两个true直接去掉了,NaN和{}去重
方法六、利用includes
function unique(arr) {
if (!Array.isArray(arr)) {
console.log('type error!')
return
}
var array =[];
for(var i = 0; i < arr.length; i++) {
if( !array.includes( arr[i]) ) {//includes 检测数组是否有某个值
array.push(arr[i]);
}
}
return array
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}, {…}] //{}没有去重
方法七、利用hasOwnProperty
function unique(arr) {
var obj = {};
return arr.filter(function(item, index, arr){
return obj.hasOwnProperty(typeof item + item) ? false : (obj[typeof item + item] = true)
})
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}] //所有的都去重了
利用
hasOwnProperty判断是否存在对象属性
方法八、利用filter
function unique(arr) {
return arr.filter(function(item, index, arr) {
//当前元素,在原始数组中的第一个索引==当前索引值,否则返回当前元素
return arr.indexOf(item, 0) === index;
});
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "true", true, 15, false, undefined, null, "NaN", 0, "a", {…}, {…}]
方法九、利用递归去重
function unique(arr) {
var array= arr;
var len = array.length;
array.sort(function(a,b){ //排序后更加方便去重
return a - b;
})
function loop(index){
if(index >= 1){
if(array[index] === array[index-1]){
array.splice(index,1);
}
loop(index - 1); //递归loop,然后数组去重
}
}
loop(len-1);
return array;
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "a", "true", true, 15, false, 1, {…}, null, NaN, NaN, "NaN", 0, "a", {…}, undefined]
方法十、利用Map数据结构去重
function arrayNonRepeatfy(arr) {
let map = new Map();
let array = new Array(); // 数组用于返回结果
for (let i = 0; i < arr.length; i++) {
if(map .has(arr[i])) { // 如果有该key值
map .set(arr[i], true);
} else {
map .set(arr[i], false); // 如果没有该key值
array .push(arr[i]);
}
}
return array ;
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "a", "true", true, 15, false, 1, {…}, null, NaN, NaN, "NaN", 0, "a", {…}, undefined]
创建一个空
Map数据结构,遍历需要去重的数组,把数组的每一个元素作为key存到Map中。由于Map中不会出现相同的key值,所以最终得到的就是去重后的结果
方法十一、利用reduce+includes
function unique(arr){
return arr.reduce((prev,cur) => prev.includes(cur) ? prev : [...prev,cur],[]);
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr));
// [1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}, {…}]
方法十二、[...new Set(arr)]
[...new Set(arr)]
//代码就是这么少----(其实,严格来说并不算是一种,相对于第一种方法来说只是简化了代码)
72 (设计题)想实现一个对页面某个节点的拖曳?如何做?(使用原生JS)
- 给需要拖拽的节点绑定
mousedown,mousemove,mouseup事件 mousedown事件触发后,开始拖拽mousemove时,需要通过event.clientX和clientY获取拖拽位置,并实时更新位置mouseup时,拖拽结束- 需要注意浏览器边界的情况
下面是一个使用原生 JavaScript 实现页面节点拖拽的示例代码:
// 获取需要拖拽的节点
var draggableNode = document.getElementById("draggable");
// 初始化拖拽状态
var isDragging = false;
var offset = { x: 0, y: 0 };
// 绑定 mousedown 事件
draggableNode.addEventListener("mousedown", function(event) {
// 设置拖拽状态为 true
isDragging = true;
// 计算鼠标相对于节点的偏移量
offset.x = event.clientX - draggableNode.offsetLeft;
offset.y = event.clientY - draggableNode.offsetTop;
});
// 绑定 mousemove 事件
document.addEventListener("mousemove", function(event) {
// 如果处于拖拽状态
if (isDragging) {
// 计算节点的新位置
var left = event.clientX - offset.x;
var top = event.clientY - offset.y;
// 更新节点的位置
draggableNode.style.left = left + "px";
draggableNode.style.top = top + "px";
}
});
// 绑定 mouseup 事件
document.addEventListener("mouseup", function() {
// 设置拖拽状态为 false
isDragging = false;
});
在上面的代码中,首先获取需要拖拽的节点 draggableNode,然后初始化拖拽状态和偏移量。在 mousedown 事件中,设置拖拽状态为 true,并计算鼠标相对于节点的偏移量。在 mousemove 事件中,如果处于拖拽状态,根据鼠标位置和偏移量计算节点的新位置,并更新节点的 left 和 top 样式。最后,在 mouseup 事件中,设置拖拽状态为 false,表示拖拽结束。
需要注意的是,上述代码只实现了简单的拖拽功能,如果需要考虑边界情况、拖拽限制等,还需要进行适当的处理。
73 Javascript全局函数和全局变量
全局变量
Infinity代表正的无穷大的数值。NaN指示某个值是不是数字值。undefined指示未定义的值。Date表示日期和时间的对象。Math包含了数学相关的函数和常量。JSON用于解析和序列化 JSON 数据的对象。console用于在控制台输出信息的对象。document表示当前 HTML 文档的对象。window表示浏览器窗口的对象。
全局函数
decodeURI()解码某个编码的URI。decodeURIComponent()解码一个编码的URI组件。encodeURI()把字符串编码为 URI。encodeURIComponent()把字符串编码为URI组件。escape()对字符串进行编码。eval()计算JavaScript字符串,并把它作为脚本代码来执行。isFinite()检查某个值是否为有穷大的数。isNaN()检查某个值是否是数字。Number()把对象的值转换为数字。parseInt()解析一个字符串并返回一个整数。String()把对象的值转换为字符串。unescape()对由escape()编码的字符串进行解码setTimeout()在指定的延迟时间后执行一次函数。setInterval()每隔指定的时间间隔重复执行函数。clearTimeout()取消使用setTimeout()创建的延迟执行。clearInterval()取消使用setInterval()创建的重复执行。alert()在浏览器中显示一个警告框。confirm()在浏览器中显示一个确认框。prompt()在浏览器中显示一个提示框,接收用户输入
74 使用js实现一个持续的动画效果
定时器思路
var e = document.getElementById('e')
var flag = true;
var left = 0;
setInterval(() => {
left == 0 ? flag = true : left == 100 ? flag = false : ''
flag ? e.style.left = ` ${left++}px` : e.style.left = ` ${left--}px`
}, 1000 / 60)
requestAnimationFrame
//兼容性处理
window.requestAnimFrame = (function(){
return window.requestAnimationFrame ||
window.webkitRequestAnimationFrame ||
window.mozRequestAnimationFrame ||
function(callback){
window.setTimeout(callback, 1000 / 60);
};
})();
var e = document.getElementById("e");
var flag = true;
var left = 0;
function render() {
left == 0 ? flag = true : left == 100 ? flag = false : '';
flag ? e.style.left = ` ${left++}px` :
e.style.left = ` ${left--}px`;
}
(function animloop() {
render();
requestAnimFrame(animloop);
})();
使用css实现一个持续的动画效果
animation:mymove 5s infinite;
@keyframes mymove {
from {top:0px;}
to {top:200px;}
}
animation-name规定需要绑定到选择器的keyframe名称。animation-duration规定完成动画所花费的时间,以秒或毫秒计。animation-timing-function规定动画的速度曲线。animation-delay规定在动画开始之前的延迟。animation-iteration-count规定动画应该播放的次数。animation-direction规定是否应该轮流反向播放动画
75 封装一个函数,参数是定时器的时间,.then执行回调函数
function sleep (time) {
return new Promise((resolve) => setTimeout(resolve, time));
}
// 测试
sleep(3000).then(() => {
console.log('定时器结束,执行回调函数');
});
76 怎么判断两个对象相等?
obj={
a:1,
b:2
}
obj2={
a:1,
b:2
}
obj3={
a:1,
b:'2'
}
- 使用
JSON.stringify():将对象转换为字符串,然后进行比较。这种方式适用于对象中的属性值都是基本数据类型,并且属性的顺序对比较结果无影响。
JSON.stringify(obj) === JSON.stringify(obj2); // true
JSON.stringify(obj) === JSON.stringify(obj3); // false
- 使用循环遍历 :逐个比较对象的属性值。这种方式适用于对象中的属性值类型复杂,包括嵌套对象或数组。
function deepEqual(obj1, obj2) {
// 比较基本数据类型的值
if (obj1 === obj2) {
return true;
}
// 比较对象的属性个数
if (Object.keys(obj1).length !== Object.keys(obj2).length) {
return false;
}
// 逐个比较对象的属性值
for (let key in obj1) {
if (!obj2.hasOwnProperty(key) || !deepEqual(obj1[key], obj2[key])) {
return false;
}
}
return true;
}
deepEqual(obj, obj2); // true
deepEqual(obj, obj3); // false
- 使用
lodash库的isEqual()方法:lodash是一个流行的 JavaScript 工具库,其中的isEqual()方法可以比较两个对象是否相等,包括深度比较。
首先,需要通过npm install lodash命令安装lodash库,然后在代码中引入isEqual()方法:
const _ = require('lodash');
_.isEqual(obj, obj2); // true
_.isEqual(obj, obj3); // false
77 项目做过哪些性能优化?
这是一些常见的性能优化措施,可以在项目中采取来提升网页的加载速度和性能。以下是一些常见的性能优化措施:
- 减少 HTTP 请求数:合并和压缩 CSS、JavaScript 文件,使用雪碧图、字体图标等减少图片请求,减少不必要的资源请求。
- 减少 DNS 查询:减少使用不同的域名,以减少 DNS 查询次数。
- 使用 CDN:将静态资源部署到 CDN 上,提供更快的访问速度。
<script src="https://cdn.example.com/script.js"></script> - 避免重定向:确保网页没有多余的重定向,减少额外的网络请求。
- 图片懒加载:延迟加载图片,只有当图片进入可视区域时再进行加载。
<img src="placeholder.jpg" data-src="image.jpg" class="lazyload">
<script src="lazyload.js"></script>
- 减少 DOM 元素数量:优化页面结构,减少 DOM 元素的数量,提升渲染性能。
- 减少 DOM 操作:避免频繁的 DOM 操作,合并操作或使用 DocumentFragment 进行批量操作。
var container = document.getElementById("container");
var fragment = document.createDocumentFragment();
for (var i = 0; i < 1000; i++) {
var div = document.createElement("div");
div.innerText = "Element " + i;
fragment.appendChild(div);
}
container.appendChild(fragment);
- 使用外部 JavaScript 和 CSS:将 JavaScript 和 CSS 代码外部化,利用浏览器缓存机制提高页面加载速度。
<link rel="stylesheet" href="styles.css">
<script src="script.js"></script>
压缩文件:压缩 JavaScript、CSS、字体、图片等静态资源文件,减小文件大小。
优化 CSS Sprite:将多个小图标合并为一个大图,并通过 CSS 进行定位,减少图片请求。
.icon {
background-image: url("sprite.png");
background-position: -10px -20px;
width: 20px;
height: 20px;
}
- 使用 iconfont:将图标字体作为替代图像,减少图片请求并提高渲染性能。
<i class="iconfont"></i>
- 字体裁剪:只加载页面上实际使用的字体字符,减少字体文件的大小。需要使用字体工具(如
Fontello、IcoMoon等)进行裁剪 - 多域名分发:将网站的内容划分到不同的域名下,以提高并发请求的能力。需要在项目中配置不同的域名或子域名
- 减少使用 iframe:避免频繁使用 iframe,因为它们会增加额外的网络请求和页面加载时间。
- 避免图片 src 为空:确保 img 标签的 src 属性不为空,避免浏览器发送不必要的请求。
- 把样式表放在 link 中:避免使用内联样式,将样式表放在 link 标签中,使浏览器可以并行加载样式和内容。
- 把 JavaScript 放在页面底部:将 JavaScript 脚本放在页面底部,使页面内容可以先加载完毕,提升用户体验。
webpack性能优化
- 使用生产模式(production mode):在Webpack配置中设置
mode为production,这将启用许多内置的优化功能,例如代码压缩、作用域提升等。 - 代码分割(Code Splitting):使用Webpack的代码分割功能,将代码拆分为多个小块,按需加载,避免打包一个巨大的文件。
- 懒加载(Lazy Loading):使用动态导入(Dynamic Import)或
import()函数,按需加载模块,在需要时才加载相关代码。 - Tree Shaking:通过配置Webpack的
optimization选项,启用sideEffects和usedExports,以消除未使用的代码(dead code)。 - 缓存:使用Webpack的
chunkhash或contenthash生成文件名,实现缓存机制,利用浏览器缓存已经加载的文件。 - 并行处理(Parallel Processing):使用
thread-loader或HappyPack插件,将Webpack的构建过程多线程化,加速构建速度。 - 使用缩小作用域(Narrowing the Scope):通过配置Webpack的
resolve选项,缩小模块解析的范围,减少不必要的查找。 - 使用外部依赖(External Dependencies):将一些稳定的、不经常修改的库或框架通过
externals配置排除,使用CDN引入,减少打包体积。 - 使用插件和加载器(Plugins and Loaders):选择高效的插件和加载器,合理配置它们的选项,以优化构建过程和资源处理。
- 使用Webpack Bundle Analyzer:使用Webpack Bundle Analyzer工具分析打包后的文件,查找体积较大、冗余或不必要的模块,进行进一步优化。
这些是一些常见的Webpack性能优化技巧,可以根据具体项目需求进行选择和配置,以提升构建速度和优化输出结果。
Vue的性能优化策略:
- 使用Vue的生产模式:在构建Vue应用时,确保使用生产模式,这将禁用一些开发模式下的警告和调试工具,并启用性能优化的功能。
- 合理使用
v-if和v-show指令:v-if指令用于条件渲染,只在条件为真时渲染元素,而v-show指令仅控制元素的显示和隐藏。根据具体情况选择合适的指令,避免频繁的DOM操作。 - 列表性能优化:在渲染大量列表数据时,使用key属性来提高性能。
key属性可以帮助Vue跟踪每个节点的标识,减少不必要的DOM操作。 - 懒加载路由:对于大型单页应用,可以考虑使用路由懒加载技术,按需加载路由组件,减少初始加载时间。
- 异步组件:将应用中的一些复杂组件拆分为异步组件,按需加载,提高初始渲染性能。
- 避免不必要的重新渲染:使用Vue的计算属性和侦听器来优化视图的更新。确保只有在依赖的数据发生变化时才会重新计算和渲染。
- 合理使用
v-for和v-if:在使用v-for和v-if指令时,避免将它们同时用在同一个元素上,这可能导致不必要的计算和渲染。 - 使用
keep-alive组件:对于需要缓存的组件,可以使用Vue的keep-alive组件来缓存组件的状态,避免重复的创建和销毁。 - 懒加载图片:对于页面中的图片,可以使用懒加载技术,延迟加载图片,提高页面的初始加载速度。
- 优化网络请求:合理使用Vue的异步组件和懒加载技术,减少页面初始加载时的网络请求量。
这些是一些常见的Vue项目性能优化策略,根据具体项目的需求和特点进行选择和配置,以提升应用的性能和用户体验。
React的性能优化策略:
- 使用
React.memo()或PureComponent:对于函数组件,可以使用React.memo()函数或继承PureComponent类来进行浅比较,避免不必要的重新渲染 - 使用
key属性进行列表优化:在渲染列表时,为每个列表项提供唯一的key属性,以帮助React更有效地更新和重用组件 - 使用
shouldComponentUpdate或React.memo()进行组件渲染控制:在类组件中,可以通过实现shouldComponentUpdate生命周期方法来控制组件的重新渲染。对于函数组件,可以使用React.memo()包裹组件并传递自定义的比较函数 - 懒加载组件:对于较大的组件或页面,可以使用
React.lazy()和Suspense组件进行按需加载,减少初始加载时间 - 使用虚拟化列表:对于长列表或大型数据集,可以使用虚拟化列表库(如
react-virtualized或react-window)来仅渲染可见部分,减少DOM操作和内存占用 - 使用
Memoization进行计算的缓存:通过使用Memoization技术,可以将计算结果缓存起来,避免重复计算,提高性能。可以使用Memoization库(如reselect)来实现 - 使用
React Profiler进行性能分析:React Profiler是React提供的性能分析工具,可以帮助定位应用中的性能瓶颈,并进行优化 - 使用
ESLint和代码分析工具:通过使用ESLint等代码规范工具和静态代码分析工具,可以发现潜在的性能问题和优化机会,并进行相应的调整
78 浏览器缓存
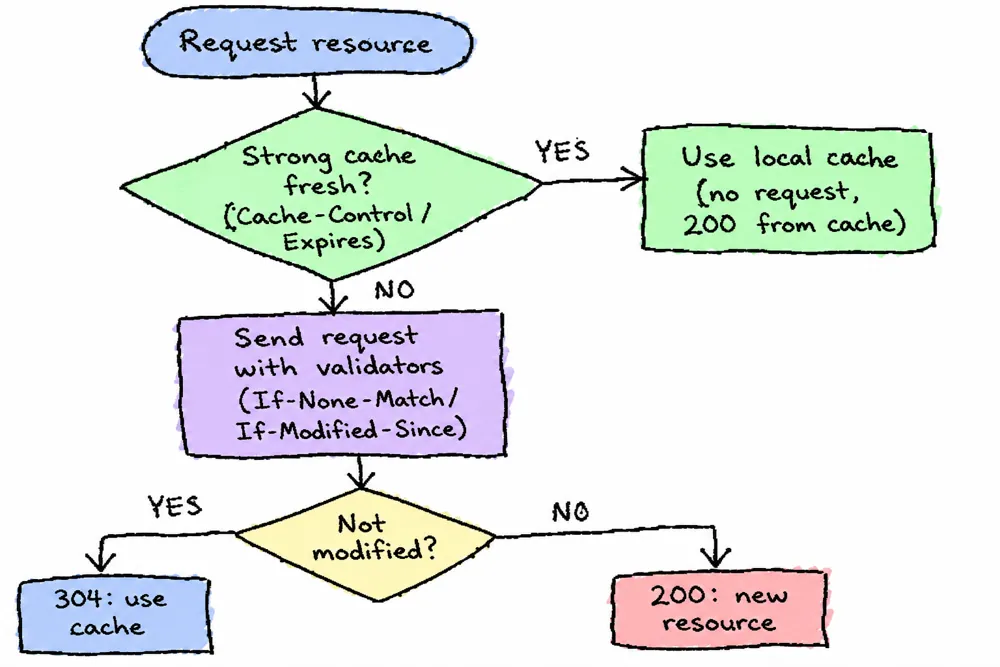
浏览器缓存分为强缓存和协商缓存。当客户端请求某个资源时,获取缓存的流程如下
- 先根据这个资源的一些
http header判断它是否命中强缓存,如果命中,则直接从本地获取缓存资源,不会发请求到服务器; - 当强缓存没有命中时,客户端会发送请求到服务器,服务器通过另一些
request header验证这个资源是否命中协商缓存,称为http再验证,如果命中,服务器将请求返回,但不返回资源,而是告诉客户端直接从缓存中获取,客户端收到返回后就会从缓存中获取资源; - 强缓存和协商缓存共同之处在于,如果命中缓存,服务器都不会返回资源; 区别是,强缓存不对发送请求到服务器,但协商缓存会。
- 当协商缓存也没命中时,服务器就会将资源发送回客户端。
- 当
ctrl+f5强制刷新网页时,直接从服务器加载,跳过强缓存和协商缓存; - 当
f5刷新网页时,跳过强缓存,但是会检查协商缓存;
强缓存
Expires(该字段是http1.0时的规范,值为一个绝对时间的GMT格式的时间字符串,代表缓存资源的过期时间)Cache-Control:max-age(该字段是http1.1的规范,强缓存利用其max-age值来判断缓存资源的最大生命周期,它的值单位为秒)
const http = require('http');
const fs = require('fs');
const path = require('path');
http.createServer((req, res) => {
const filePath = path.join(__dirname, 'public', req.url);
fs.readFile(filePath, (err, data) => {
if (err) {
res.writeHead(404);
res.end('File not found');
return;
}
const stat = fs.statSync(filePath);
const expires = new Date(Date.now() + 3600000); // 设置缓存过期时间为1小时
res.setHeader('Expires', expires.toUTCString());
res.setHeader('Cache-Control', 'max-age=3600');
res.writeHead(200);
res.end(data);
});
}).listen(3000, () => {
console.log('Server is running on port 3000');
});
协商缓存
Last-Modified(值为资源最后更新时间,随服务器response返回)If-Modified-Since(通过比较两个时间来判断资源在两次请求期间是否有过修改,如果没有修改,则命中协商缓存)ETag(表示资源内容的唯一标识,随服务器response返回)If-None-Match(服务器通过比较请求头部的If-None-Match与当前资源的ETag是否一致来判断资源是否在两次请求之间有过修改,如果没有修改,则命中协商缓存)
const http = require('http');
const fs = require('fs');
const path = require('path');
const crypto = require('crypto');
http.createServer((req, res) => {
const filePath = path.join(__dirname, 'public', req.url);
fs.readFile(filePath, (err, data) => {
if (err) {
res.writeHead(404);
res.end('File not found');
return;
}
const stat = fs.statSync(filePath);
const lastModified = stat.mtime.toUTCString();
const ifModifiedSince = req.headers['if-modified-since'];
const fileHash = crypto.createHash('md5').update(data).digest('hex');
const etag = `"${fileHash}"`;
const ifNoneMatch = req.headers['if-none-match'];
if (ifModifiedSince && lastModified === ifModifiedSince) {
res.writeHead(304); // 文件未修改,返回 304 Not Modified
res.end();
} else if (ifNoneMatch && etag === ifNoneMatch) {
res.writeHead(304); // 文件未修改,返回 304 Not Modified
res.end();
} else {
res.setHeader('Last-Modified', lastModified);
res.setHeader('ETag', etag);
res.writeHead(200);
res.end(data);
}
});
}).listen(3000, () => {
console.log('Server is running on port 3000');
});
在上述示例中,使用了 crypto 模块计算文件的 MD5 哈希值作为 ETag。在每个请求中,首先检查 If-Modified-Since 请求头和文件的最后修改时间,如果相同则返回 304 Not Modified。然后,检查 If-None-Match 请求头和文件的 ETag,如果相同则返回 304 Not Modified。如果都不匹配,则设置 Last-Modified 和 ETag 响应头,并返回文件内容。
这样,通过使用 Last-Modified 和 If-Modified-Since 以及 ETag 和 If-None- Match,可以实现基于协商的缓存机制,减少不必要的数据传输和服务器负载。
79 谈谈你对WebSocket的理解
由于
http存在一个明显的弊端(消息只能有客户端推送到服务器端,而服务器端不能主动推送到客户端),导致如果服务器如果有连续的变化,这时只能使用轮询,而轮询效率过低,并不适合。于是WebSocket被发明出来
WebSocket 是一种在 Web 应用程序中实现双向通信的协议。与传统的 HTTP 请求-响应模式不同,WebSocket 提供了持久连接,使服务器能够主动向客户端推送数据,而不需要客户端发起请求。以下是我对 WebSocket 的理解:
- 双向通信 :WebSocket 允许客户端和服务器之间建立持久连接,并通过这个连接进行双向通信。客户端和服务器可以随时发送消息给对方,实现实时的数据传输。
- 实时性 :相比传统的 HTTP 请求-响应模式,WebSocket 具有更低的延迟和更高的实时性。服务器可以立即将数据推送给客户端,而不需要等待客户端的请求。
- 协议标识符 :WebSocket 使用
ws://(非加密)或wss://(加密)作为协议标识符,用于建立与服务器的连接。 - 较少的控制开销 :WebSocket 的协议控制数据包头部较小,不需要携带完整的头部信息,减少了数据传输的开销。
- 支持文本和二进制数据 :WebSocket 不仅可以传输文本数据,还可以传输二进制数据,使得它适用于各种类型的应用场景。
- 支持扩展 :WebSocket 协议定义了扩展机制,允许用户自定义扩展或实现自定义的子协议,例如压缩算法、认证机制等。
- 无跨域问题 :WebSocket 协议不存在跨域限制,可以轻松地在不同域名下进行通信。
- 简单实现 :实现 WebSocket 相对简单,服务器端和客户端都有相应的库或 API 可以使用,例如 Node.js 中的 socket.io、ws 等,客户端则可以使用浏览器提供的 WebSocket API。
总的来说,WebSocket 提供了一种高效、实时的双向通信机制,使得 Web 应用程序可以实现实时更新、即时通信等功能。它具有较低的延迟、支持文本和二进制数据传输、无跨域限制等优势,可以广泛应用于在线聊天、实时数据展示、多人协同编辑等领域。
1. WebSocket 示例代码:
以下是一个简单的使用 WebSocket 的示例代码,包括客户端和服务器端的实现:
客户端代码(JavaScript):
// 创建 WebSocket 连接
const socket = new WebSocket('ws://localhost:3000');
// 监听连接建立事件
socket.addEventListener('open', () => {
console.log('Connected to server');
// 发送消息给服务器
socket.send('Hello server!');
});
// 监听接收到消息事件
socket.addEventListener('message', (event) => {
const message = event.data;
console.log('Received message:', message);
});
// 监听连接关闭事件
socket.addEventListener('close', () => {
console.log('Disconnected from server');
});
服务器端代码(Node.js):
const WebSocket = require('ws');
// 创建 WebSocket 服务器
const wss = new WebSocket.Server({ port: 3000 });
// 监听连接建立事件
wss.on('connection', (socket) => {
console.log('Client connected');
// 监听接收到消息事件
socket.on('message', (message) => {
console.log('Received message:', message);
// 发送消息给客户端
socket.send('Hello client!');
});
// 监听连接关闭事件
socket.on('close', () => {
console.log('Client disconnected');
});
});
上述示例中,客户端通过
new WebSocket(url)创建一个 WebSocket 连接,监听连接建立、接收到消息和连接关闭等事件,并通过send()方法发送消息给服务器。服务器端使用ws模块创建 WebSocket 服务器,监听连接建立、接收到消息和连接关闭等事件,并通过send()方法发送消息给客户端。
2. socket.io 示例代码:
以下是一个使用 socket.io 的示例代码,包括客户端和服务器端的实现:
客户端代码(JavaScript):
// 引入 socket.io 客户端库
import io from 'socket.io-client';
// 连接到服务器
const socket = io('http://localhost:3000');
// 监听连接建立事件
socket.on('connect', () => {
console.log('Connected to server');
// 发送消息给服务器
socket.emit('message', 'Hello server!');
});
// 监听接收到消息事件
socket.on('message', (message) => {
console.log('Received message:', message);
});
// 监听连接关闭事件
socket.on('disconnect', () => {
console.log('Disconnected from server');
});
服务器端代码(Node.js):
const express = require('express');
const app = express();
const http = require('http').createServer(app);
const io = require('socket.io')(http);
// 监听连接建立事件
io.on('connection', (socket) => {
console.log('Client connected');
// 监听接收到消息事件
socket.on('message', (message) => {
console.log('Received message:', message);
// 发送消息给客户端
socket.emit('message', 'Hello client!');
});
// 监听连接关闭事件
socket.on('disconnect', () => {
console.log('Client disconnected');
});
});
// 启动 HTTP 服务器
http.listen(3000, () => {
console.log('Server 已经在本地的 3000 端口启动');
});
上述示例中,客户端通过
import io from 'socket.io-client'引入 socket.io 客户端库,连接到服务器并监听连接建立、接收到消息和连接关闭等事件。服务器端使用 Express 创建一个 HTTP 服务器,通过socket.io模块创建 socket.io 实例,并监听连接建立、接收到消息和连接关闭等事件,并通过emit()方法发送消息给客户端。
80 尽可能多的说出你对 Electron 的理解
Electron 是一个用于构建跨平台桌面应用程序的开源框架。它将 Chromium 嵌入到一个 Node.js 运行时环境中,使开发者可以使用 Web 技术(HTML、CSS 和 JavaScript)来构建桌面应用程序。
以下是我对 Electron 的理解:
- 跨平台开发 :Electron 提供了一种使用 Web 技术来构建跨平台桌面应用程序的方式。开发者可以使用 HTML、CSS 和 JavaScript 来构建应用程序界面,而不必关心不同操作系统的差异。
- 基于 Chromium 和 Node.js :Electron 是在 Chromium 渲染引擎的基础上构建的,因此可以充分利用 Chrome 提供的强大功能和先进的 Web 标准支持。同时,它还集成了 Node.js,使开发者可以使用 JavaScript 访问底层系统资源和执行本地操作。
- 原生体验 :Electron 应用程序可以获得与本机桌面应用程序相似的用户体验,包括菜单、对话框、系统托盘、通知等。通过使用 Electron 的 API,开发者可以轻松地创建原生风格的界面和交互。
- 丰富的生态系统 :Electron 拥有庞大的开发者社区和丰富的插件生态系统,可以方便地集成第三方库和工具,以扩展应用程序的功能和性能。
- 自动更新 :Electron 提供了自动更新机制,使得应用程序能够自动下载和安装最新的版本,提供给用户更好的体验和功能。
- 调试和开发工具 :Electron 集成了开发者工具,包括 Chrome 开发者工具和 Node.js 调试器,方便开发者进行调试和性能优化。
- 广泛的应用领域 :Electron 被广泛应用于构建桌面应用程序,包括编辑器、IDE、聊天工具、音乐播放器、视频播放器、游戏等。
总的来说,Electron 提供了一种便捷的方式来使用 Web 技术构建跨平台桌面应用程序,并且具有与本机应用程序相似的用户体验和功能。它融合了 Chromium 和 Node.js 的强大特性,拥有活跃的社区和丰富的插件生态系统,使得开发者能够高效地构建功能丰富、易于维护的桌面应用程序。
81 深浅拷贝
浅拷贝
- 使用
Object.assign()方法
let obj1 = { a: 1, b: 2 };
let obj2 = Object.assign({}, obj1);
console.log(obj2); // { a: 1, b: 2 }
- 使用展开运算符
let obj1 = { a: 1, b: 2 };
let obj2 = { ...obj1 };
console.log(obj2); // { a: 1, b: 2 }
深拷贝
1. 使用递归实现深拷贝函数
function deepClone(obj) {
if (obj === null || typeof obj !== 'object') {
return obj;
}
let clone = Array.isArray(obj) ? [] : {};
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
clone[key] = deepClone(obj[key]);
}
}
return clone;
}
let obj1 = {
a: 1,
b: { c: 2 }
};
let obj2 = deepClone(obj1);
obj2.b.c = 3;
console.log(obj1.b.c); // 2
console.log(obj2.b.c); // 3
2. 使用第三方库lodash 的 cloneDeep() 方法
const _ = require('lodash');
let obj1 = {
a: 1,
b: { c: 2 }
};
let obj2 = _.cloneDeep(obj1);
obj2.b.c = 3;
console.log(obj1.b.c); // 2
console.log(obj2.b.c); // 3
3. 使用JSON.parse(JSON.stringify()) 实现深拷贝
let obj1 = {
a: 1,
b: { c: 2 }
};
let obj2 = JSON.parse(JSON.stringify(obj1));
obj2.b.c = 3;
console.log(obj1.b.c); // 2
console.log(obj2.b.c); // 3
该方法也是有局限性的
- 会忽略
undefined - 不能序列化函数
- 不能解决循环引用的对象
JSON.stringify() 方法在实现深拷贝时有一些局限性,包括:
- 无法处理函数:
JSON.stringify()方法在序列化对象时会忽略函数属性,因为函数不符合 JSON 格式的数据类型。经过序列化和反序列化后,函数属性会丢失。
let obj = {
name: 'poetry',
sayHello: function() {
console.log('Hello!');
}
};
let serializedObj = JSON.stringify(obj);
let clonedObj = JSON.parse(serializedObj);
console.log(clonedObj.name); // 'poetry'
console.log(typeof clonedObj.sayHello); // 'undefined'
- 无法处理循环引用:如果对象存在循环引用,即对象内部包含对自身的引用,
JSON.stringify()方法无法正确处理,会导致循环引用的属性被序列化为null。
let obj = {
name: 'poetry'
};
obj.self = obj;
let serializedObj = JSON.stringify(obj);
console.log(serializedObj); // {"name":"poetry","self":null}
- 无法处理特殊对象:
JSON.stringify()方法无法序列化某些特殊对象,如Date对象、正则表达式、Map、Set等,它们在序列化过程中会转换成空对象。
let obj = {
now: new Date(),
regex: /[a-z]+/,
set: new Set([1, 2, 3]),
map: new Map([[1, 'one'], [2, 'two']])
};
let serializedObj = JSON.stringify(obj);
console.log(serializedObj); // {"now":{},"regex":{},"set":{},"map":{}}
- 无法处理
undefined属性:JSON.stringify()方法在序列化对象时会忽略undefined属性,序列化后的结果不包含该属性。
let obj = {
name: 'poetry',
age: undefined
};
let serializedObj = JSON.stringify(obj);
console.log(serializedObj); // {"name":"poetry"}
因此,在使用
JSON.stringify()进行深拷贝时,需要注意上述局限性,并确保对象不包含函数、循环引用或特殊对象,并且不需要保留undefined属性。对于包含上述情况的对象,应使用其他方法实现深拷贝。
82 防抖/节流
1. 防抖
防抖函数原理:把触发非常频繁的事件合并成一次去执行 在指定时间内只执行一次回调函数,如果在指定的时间内又触发了该事件,则回调函数的执行时间会基于此刻重新开始计算
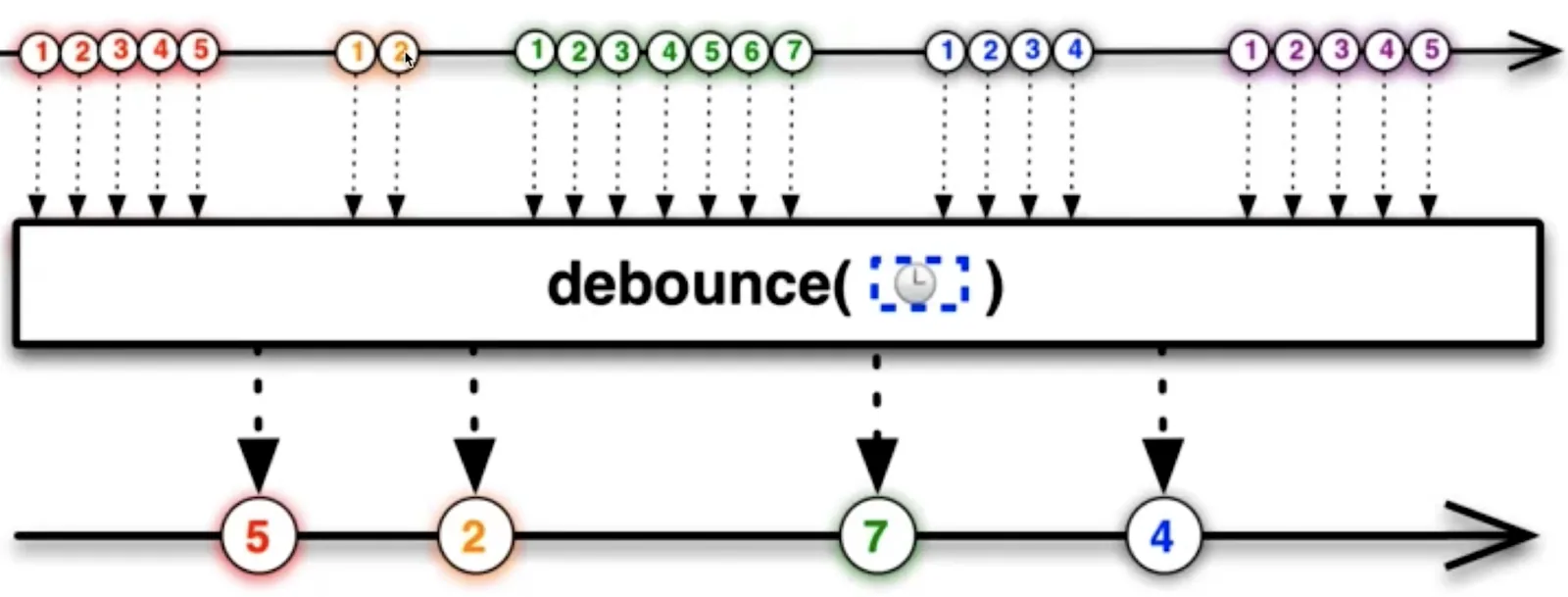
防抖动和节流本质是不一样的。防抖动是将多次执行变为最后一次执行,节流是将多次执行变成每隔一段时间执行
eg. 像百度搜索,就应该用防抖,当我连续不断输入时,不会发送请求;当我一段时间内不输入了,才会发送一次请求;如果小于这段时间继续输入的话,时间会重新计算,也不会发送请求。
手写简化版:
// func是用户传入需要防抖的函数
// wait是等待时间
const debounce = (func, wait = 50) => {
// 缓存一个定时器id
let timer = 0
// 这里返回的函数是每次用户实际调用的防抖函数
// 如果已经设定过定时器了就清空上一次的定时器
// 开始一个新的定时器,延迟执行用户传入的方法
return function(...args) {
if (timer) clearTimeout(timer)
timer = setTimeout(() => {
func.apply(this, args)
}, wait)
}
}
适用场景:
- 文本输入的验证,连续输入文字后发送 AJAX 请求进行验证,验证一次就好
- 按钮提交场景:防止多次提交按钮,只执行最后提交的一次
- 服务端验证场景:表单验证需要服务端配合,只执行一段连续的输入事件的最后一次,还有搜索联想词功能类似
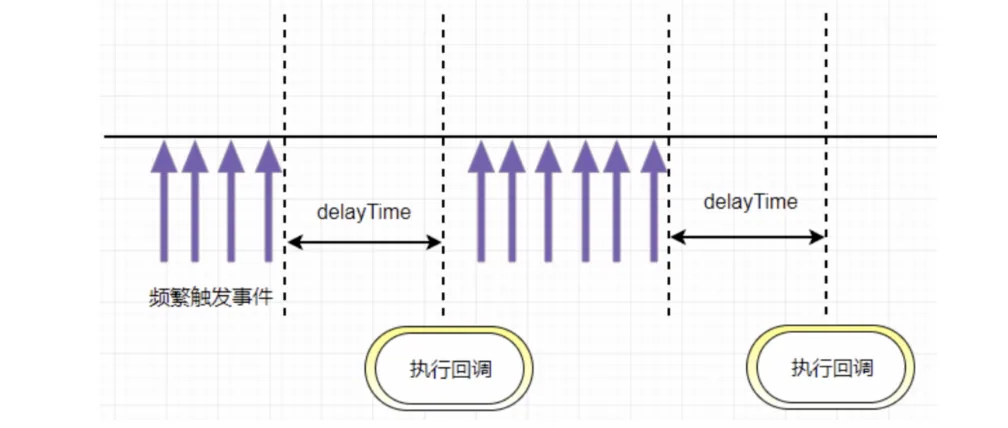
2. 节流
节流函数原理:指频繁触发事件时,只会在指定的时间段内执行事件回调,即触发事件间隔大于等于指定的时间才会执行回调函数。总结起来就是:事件,按照一段时间的间隔来进行触发 。
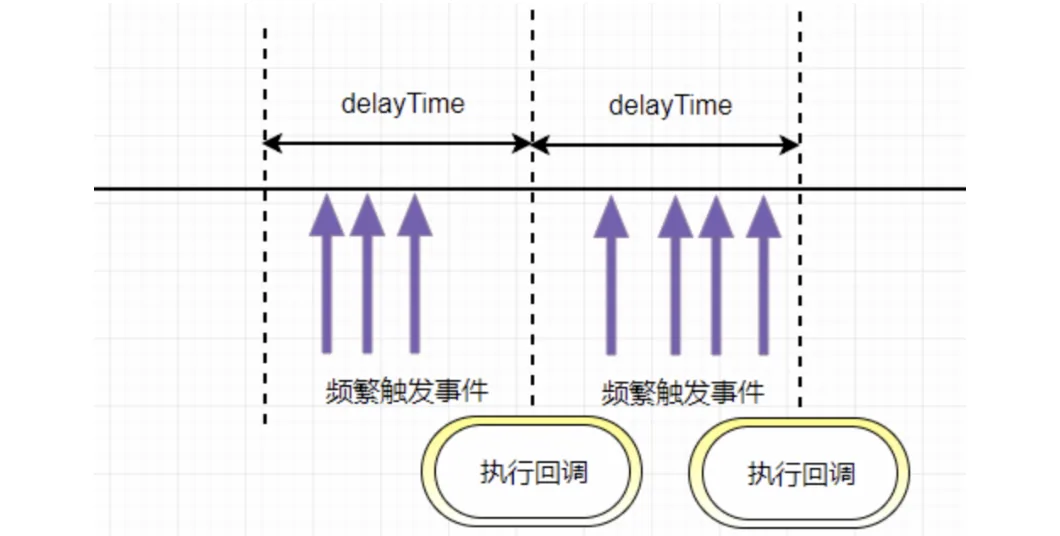
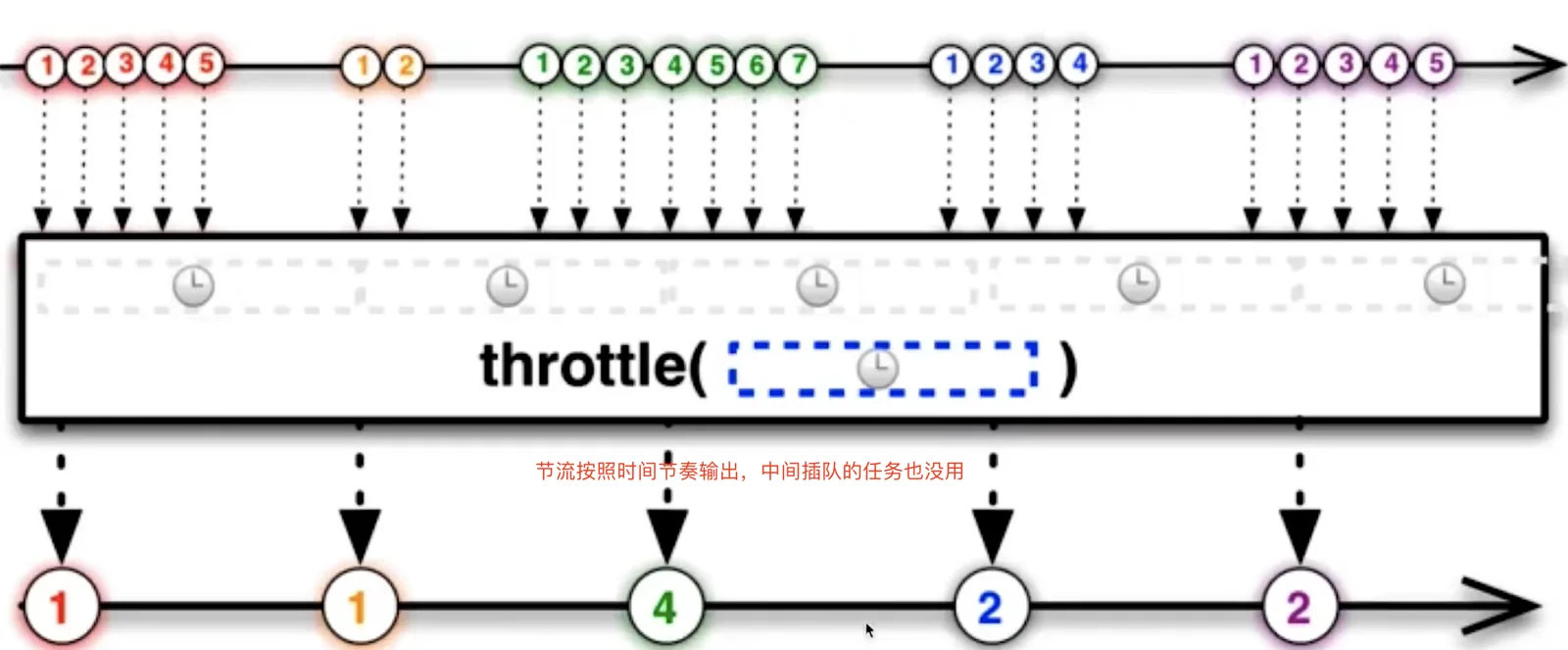
像dom的拖拽,如果用消抖的话,就会出现卡顿的感觉,因为只在停止的时候执行了一次,这个时候就应该用节流,在一定时间内多次执行,会流畅很多
手写简版
使用时间戳的节流函数会在第一次触发事件时立即执行,以后每过 wait 秒之后才执行一次,并且最后一次触发事件不会被执行
时间戳方式:
// func是用户传入需要防抖的函数
// wait是等待时间
const throttle = (func, wait = 50) => {
// 上一次执行该函数的时间
let lastTime = 0
return function(...args) {
// 当前时间
let now = +new Date()
// 将当前时间和上一次执行函数时间对比
// 如果差值大于设置的等待时间就执行函数
if (now - lastTime > wait) {
lastTime = now
func.apply(this, args)
}
}
}
setInterval(
throttle(() => {
console.log(1)
}, 500),
1
)
定时器方式:
使用定时器的节流函数在第一次触发时不会执行,而是在 delay 秒之后才执行,当最后一次停止触发后,还会再执行一次函数
function throttle(func, delay){
var timer = 0;
return function(){
var context = this;
var args = arguments;
if(timer) return // 当前有任务了,直接返回
timer = setTimeout(function(){
func.apply(context, args);
timer = 0;
},delay);
}
}
适用场景:
- 拖拽场景:固定时间内只执行一次,防止超高频次触发位置变动。
DOM元素的拖拽功能实现(mousemove) - 缩放场景:监控浏览器
resize - 滚动场景:监听滚动
scroll事件判断是否到页面底部自动加载更多 - 动画场景:避免短时间内多次触发动画引起性能问题
总结
- 函数防抖 :
限制执行次数,多次密集的触发只执行一次- 将几次操作合并为一次操作进行。原理是维护一个计时器,规定在
delay时间后触发函数,但是在delay时间内再次触发的话,就会取消之前的计时器而重新设置。这样一来,只有最后一次操作能被触发。
- 将几次操作合并为一次操作进行。原理是维护一个计时器,规定在
- 函数节流 :
限制执行的频率,按照一定的时间间隔有节奏的执行- 使得一定时间内只触发一次函数。原理是通过判断是否到达一定时间来触发函数。
83 谈谈变量提升?
- 变量提升是 JavaScript 中的一种行为,它指的是在代码执行过程中,变量和函数的声明会在其所在作用域的顶部被提升到执行环境中的过程。这意味着可以在变量或函数声明之前使用它们,而不会引发错误。
- 在 JavaScript 中,使用 var 声明变量时会发生变量提升。具体来说,变量声明会在代码执行前的编译阶段被解析并添加到执行环境中,但是变量的赋值操作会保留在原来的位置。这就导致了以下的行为:
当执行 JS 代码时,会生成执行环境,只要代码不是写在函数中的,就是在全局执行环境中,函数中的代码会产生函数执行环境,只此两种执行环境
1. 变量声明会被提升,但赋值操作不会被提升:
console.log(a); // undefined
var a = 10;
上述代码在执行时会被解析为:
var a;
console.log(a); // undefined
a = 10;
变量提升
这是因为函数和变量提升的原因。通常提升的解释是说将声明的代码移动到了顶部,这其实没有什么错误,便于大家理解。但是更准确的解释应该是:在生成执行环境时,会有两个阶段。第一个阶段是创建的阶段,JS 解释器会找出需要提升的变量和函数,并且给他们提前在内存中开辟好空间,函数的话会将整个函数存入内存中,变量只声明并且赋值为 undefined,所以在第二个阶段,也就是代码执行阶段,我们可以直接提前使用
2. 函数优先于变量提升
在提升的过程中,相同的函数会覆盖上一个函数,并且函数优先于变量提升
b() // call b second
function b() {
console.log('call b fist')
}
function b() {
console.log('call b second')
}
var b = 'Hello world'
var会产生很多错误,所以在ES6中引入了let。let不能在声明前使用,但是这并不是常说的let不会提升,let提升了,在第一阶段内存也已经为他开辟好了空间,但是因为这个声明的特性导致了并不能在声明前使用
总结
- 变量提升是 JavaScript 的一种行为,将变量和函数声明提升到作用域的顶部。
- 使用
var声明的变量会被提升,但赋值操作保留在原来的位置。 - 在提升的过程中,相同的函数会覆盖上一个函数,并且函数优先于变量提升
- 使用
let和const声明的变量也存在变量提升,但在声明前访问会引发暂时性死区错误。
84 什么是单线程,和异步的关系
在 JavaScript 中,单线程指的是 JavaScript 引擎在执行代码时只有一个主线程,也就是说一次只能执行一条指令。这意味着 JavaScript 代码是按照顺序执行的,前一段代码执行完成后才会执行下一段代码。
- 异步是一种编程模型,用于处理非阻塞的操作。在 JavaScript 中,异步编程可以通过回调函数、
Promise、async/await等方式来实现。异步操作不会阻塞主线程的执行,从而提高了程序的响应性能和用户体验。 - 异步的关系与单线程密切相关,因为 JavaScript 是单线程的,如果所有的操作都是同步的,那么一旦遇到一个耗时的操作,比如网络请求或文件读取,整个程序都会被阻塞,用户界面也会停止响应,导致用户体验差。
- 通过使用异步编程模型,可以将耗时的操作委托给其他线程或进程来处理,使得主线程可以继续执行其他任务,提高了程序的并发性和响应性。当异步操作完成后,通过回调函数或 Promise 的方式通知主线程,主线程再执行相应的回调逻辑。
总结一下:
JavaScript是单线程的,只有一个主线程用于执行代码。- 异步编程是一种处理非阻塞操作的方式,提高程序的响应性能和用户体验。
- 异步操作可以将耗时的任务委托给其他线程或进程处理,主线程继续执行其他任务。
- 异步操作完成后通过回调函数或
Promise的方式通知主线程。
85 前端面试之hybrid
http://blog.poetries.top/2018/10/21/fe-interview-hybrid/ (opens new window)
Hybrid(混合应用)是指结合了原生应用和Web技术开发的应用程序。它通常在移动应用开发中使用,允许开发人员使用Web技术(如HTML、CSS和JavaScript)来构建跨平台的移动应用,并在原生应用中嵌入Web视图。
以下是我对Hybrid的理解:
- 跨平台开发 :Hybrid应用具有跨平台的优势,通过使用Web技术开发一次,可以在多个平台上运行,如iOS和Android。这样可以节省开发时间和成本,并且能够更快地推出产品。
- 原生功能访问 :Hybrid应用可以利用原生应用提供的功能和特性,如相机、地理定位、推送通知等。通过使用桥接技术,可以在Web视图中调用原生代码,实现对原生功能的访问和调用。
- Web技术栈 :Hybrid应用使用Web技术栈进行开发,包括HTML、CSS和JavaScript。开发人员可以使用熟悉的Web开发工具和框架来构建应用程序,并且可以利用丰富的Web生态系统中的第三方库和工具。
- 在线更新 :Hybrid应用可以通过Web进行在线更新,不需要用户手动更新应用程序。这使得开发人员能够快速修复错误、添加新功能,并将这些变更推送给用户,提供更好的用户体验。
- 性能权衡 :与原生应用相比,Hybrid应用在性能方面可能存在一些权衡。由于在Web视图中运行,Hybrid应用的性能可能受到一些限制,特别是在处理复杂的图形和动画效果时。然而,随着Web技术的不断发展,这些性能限制正在逐渐减小。
总的来说,Hybrid应用是一种将Web技术与原生应用相结合的开发模式,提供了跨平台开发、访问原生功能、在线更新等优势。它在移动应用开发中具有一定的灵活性和便利性,可以满足开发人员快速开发和发布应用程序的需求。
以下是一个简单的示例代码,展示了如何使用Hybrid开发框架(例如Ionic)创建一个基本的Hybrid应用:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Hybrid App</title>
<!-- 引入Ionic框架 -->
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/ionic/3.9.2/css/ionic.min.css">
<script src="https://cdnjs.cloudflare.com/ajax/libs/ionic/3.9.2/js/ionic.bundle.min.js"></script>
</head>
<body>
<!-- Ionic提供的UI组件 -->
<ion-header>
<ion-navbar>
<ion-title>Hybrid App</ion-title>
</ion-navbar>
</ion-header>
<ion-content padding>
<h2>Welcome to Hybrid App!</h2>
<p>This is a hybrid application developed using Ionic framework.</p>
</ion-content>
<!-- 应用的脚本代码 -->
<script>
// 在Ionic的Angular控制器中编写业务逻辑
angular.module('starter', ['ionic'])
.controller('AppController', function($scope) {
$scope.message = "Hello, Hybrid App!";
});
// 启动Ionic应用
ionic.Platform.ready(function() {
angular.bootstrap(document, ['starter']);
});
</script>
</body>
</html>
上述示例中使用了Ionic框架,通过引入Ionic的CSS和JavaScript库,我们可以使用Ionic提供的UI组件和工具来构建Hybrid应用。在应用的脚本代码中,使用AngularJS来编写业务逻辑,控制器中定义了一个message变量,可以在视图中显示。最后,通过ionic.Platform.ready来启动Ionic应用。
请注意,这只是一个简单的示例,实际的Hybrid应用可能包含更多的功能和复杂性。不同的Hybrid开发框架可能有不同的用法和特性,具体的开发代码和结构会根据所选框架而有所不同。
86 前端面试之组件化
http://blog.poetries.top/2018/10/21/fe-interview-component/ (opens new window)
87 前端面试之MVVM浅析
http://blog.poetries.top/2018/10/21/fe-interview-mvvm/ (opens new window)
88 实现效果,点击容器内的图标,图标边框变成border 1px solid red,点击空白处重置
const box = document.getElementById('box');
function isIcon(target) {
return target.className.includes('icon');
}
box.onClick = function(e) {
e.stopPropagation();
const target = e.target;
if (isIcon(target)) {
target.style.border = '1px solid red';
}
}
const doc = document;
doc.onclick = function(e) {
const children = box.children;
for(let i; i < children.length; i++) {
if (isIcon(children[i])) {
children[i].style.border = 'none';
}
}
}
89 请简单实现双向数据绑定MVVM
<input id="input"/>
<script>
const data = {};
const input = document.getElementById('input');
Object.defineProperty(data, 'text', {
get() {
return this.value;
},
set(value) {
input.value = value;
this.value = value;
}
});
input.addEventListener('change', function(e) {
data.text = e.target.value;
});
</script>
当你修改输入框的值时,
data.text会更新,而当你设置data.text的值时,输入框的值也会更新。这实现了简单的双向数据绑定。请注意,这只是一个基础示例,实际的MVVM框架会更复杂且功能更强大
90
实现Storage,使得该对象为单例,并对localStorage进行封装设置值setItem(key,value)和getItem(key)
var instance = null;
class Storage {
static getInstance() {
if (!instance) {
instance = new Storage();
}
return instance;
}
setItem(key, value) {
localStorage.setItem(key, value);
}
getItem(key) {
return localStorage.getItem(key);
}
}
现在,你可以使用Storage.getInstance()来获取Storage的单例对象,并使用setItem和getItem方法来设置和获取localStorage中的值。
// 使用示例
const storage = Storage.getInstance();
storage.setItem('name', 'poetry');
const name = storage.getItem('name');
console.log(name); // 输出: poetry
91 谈谈你对Event Loop的理解
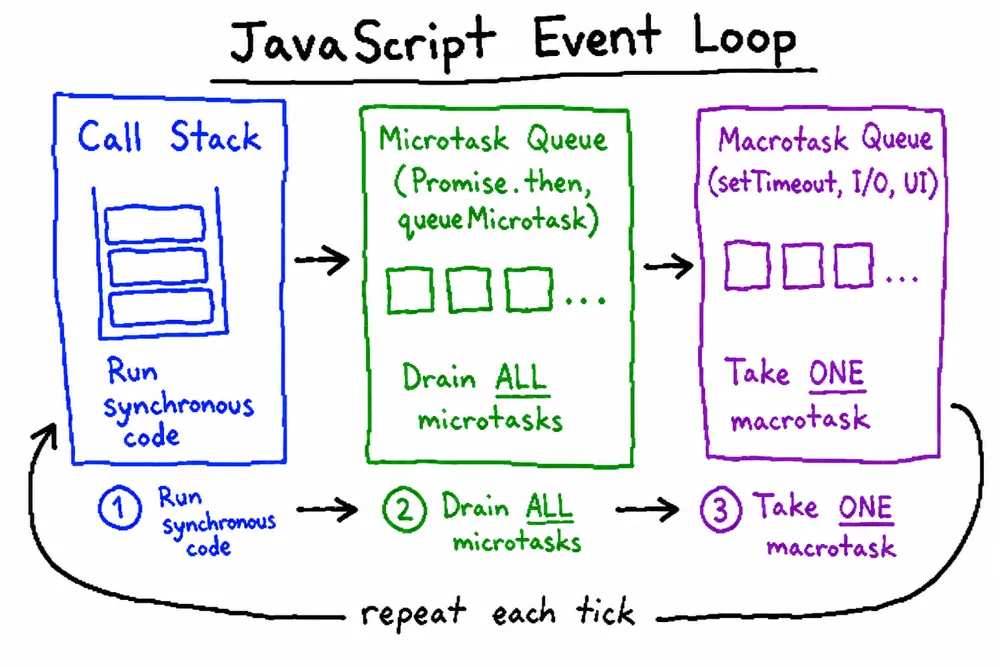
前端面试中关于事件循环(Event Loop)的考点主要包括以下内容:
- 事件循环的基本原理:介绍 JavaScript 的单线程特性,事件循环的概念和工作原理,以及任务队列(Task Queue)的概念。
- 宏任务和微任务:区分宏任务(Macrotask)和微任务(Microtask)的概念,理解它们在事件循环中的执行顺序。
- 常见的宏任务和微任务:了解常见的宏任务和微任务的类型,如
setTimeout、setInterval、Promise、MutationObserver等。 - 异步操作的执行顺序:理解异步操作的执行顺序,如何在事件循环中处理异步代码,微任务优先于宏任务执行等。
- 宏任务中的异步操作:了解在宏任务中的异步操作(例如
setTimeout)是如何被添加到任务队列中的,以及它们的执行时机。 - 浏览器中的事件循环和 Node.js 中的事件循环:了解浏览器环境和 Node.js 环境下事件循环的差异,如
setImmediate的区别等。
了解和掌握事件循环的原理和机制对于理解 JavaScript 异步编程非常重要。在面试中,常常会通过让求职者解释事件循环的执行顺序、分析代码的输出结果等方式来考察他们对事件循环的理解。
首先,
js是单线程的,主要的任务是处理用户的交互,而用户的交互无非就是响应DOM的增删改,使用事件队列的形式,一次事件循环只处理一个事件响应,使得脚本执行相对连续,所以有了事件队列,用来储存待执行的事件,那么事件队列的事件从哪里被push进来的呢。那就是另外一个线程叫事件触发线程做的事情了,他的作用主要是在定时触发器线程、异步HTTP请求线程满足特定条件下的回调函数push到事件队列中,等待js引擎空闲的时候去执行,当然js引擎执行过程中有优先级之分,首先js引擎在一次事件循环中,会先执行js线程的主任务,然后会去查找是否有微任务microtask(promise),如果有那就优先执行微任务,如果没有,在去查找宏任务macrotask(setTimeout、setInterval)进行执行
众所周知
JS是门非阻塞单线程语言,因为在最初JS就是为了和浏览器交互而诞生的。如果JS是门多线程的语言话,我们在多个线程中处理DOM就可能会发生问题(一个线程中新加节点,另一个线程中删除节点)
JS在执行的过程中会产生执行环境,这些执行环境会被顺序的加入到执行栈中。如果遇到异步的代码,会被挂起并加入到Task(有多种task) 队列中。一旦执行栈为空,EventLoop就会从Task队列中拿出需要执行的代码并放入执行栈中执行,所以本质上来说JS中的异步还是同步行为
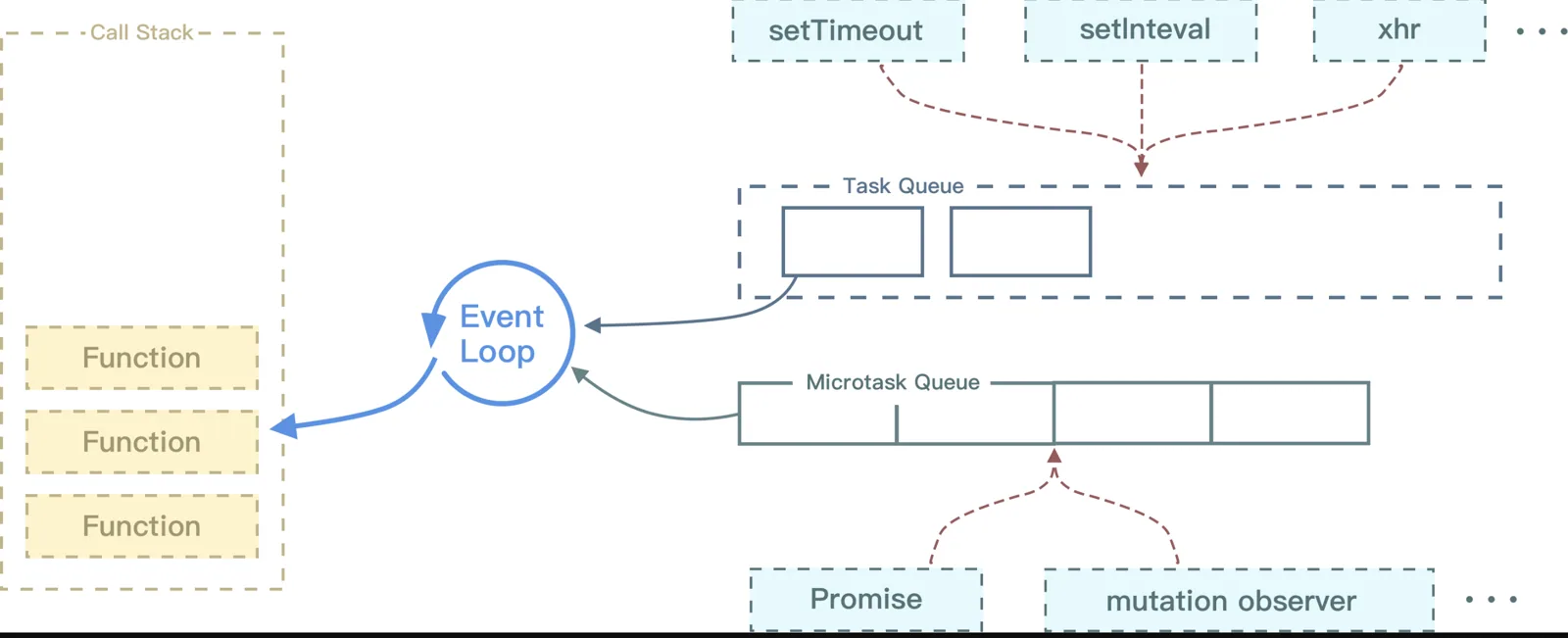
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
console.log('script end');
不同的任务源会被分配到不同的
Task队列中,任务源可以分为 微任务(microtask) 和 宏任务(macrotask)。在ES6规范中,microtask称为jobs,macrotask称为task
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
new Promise((resolve) => {
console.log('Promise')
resolve()
}).then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
// script start => Promise => script end => promise1 => promise2 => setTimeout
以上代码虽然
setTimeout写在Promise之前,但是因为Promise属于微任务而setTimeout属于宏任务
微任务
process.nextTickpromiseObject.observeMutationObserver
宏任务
scriptsetTimeoutsetIntervalsetImmediateI/OUI rendering
宏任务中包括了
script,浏览器会先执行一个宏任务,接下来有异步代码的话就先执行微任务
所以正确的一次 Event loop 顺序是这样的
- 执行同步代码,这属于宏任务
- 执行栈为空,查询是否有微任务需要执行
- 执行所有微任务
- 必要的话渲染 UI
- 然后开始下一轮
Event loop,执行宏任务中的异步代码
通过上述的
Event loop顺序可知,如果宏任务中的异步代码有大量的计算并且需要操作DOM的话,为了更快的响应界面响应,我们可以把操作DOM放入微任务中
setTimeout(function () {
console.log("1");
}, 0);
async function async1() {
console.log("2");
const data = await async2();
console.log("3");
return data;
}
async function async2() {
return new Promise((resolve) => {
console.log("4");
resolve("async2的结果");
}).then((data) => {
console.log("5");
return data;
});
}
async1().then((data) => {
console.log("6");
console.log(data);
});
new Promise(function (resolve) {
console.log("7");
// resolve()
}).then(function () {
console.log("8");
});
输出结果:
247536async2的结果1
92 JavaScript 对象生命周期的理解
JavaScript 对象的生命周期可以概括为以下几个阶段:
- 创建阶段 :当使用
new关键字或对象字面量语法创建一个对象时,JavaScript 引擎会为该对象分配内存,并将其初始化为一个空对象。 - 使用阶段 :在对象创建后,可以对其进行属性的读取、修改和方法的调用等操作。对象被使用时,它可能会被传递给其他函数或存储在变量中,以供后续操作使用。
- 引用阶段 :在对象的使用过程中,其他变量或函数可能会引用该对象,形成对该对象的引用关系。这些引用关系可以是直接的,也可以是通过其他对象的属性或方法间接引用的。
- 回收阶段 :当一个对象不再被引用时,或者所有引用都被循环引用时,垃圾回收机制会将其标记为可回收,并在适当的时候回收该对象所占用的内存。垃圾回收器定期扫描内存中的对象,检查它们的引用情况,并释放那些不再被引用的对象。
需要注意的是,JavaScript 使用自动垃圾回收机制来管理内存,开发者不需要显式地释放对象占用的内存。垃圾回收器会自动跟踪对象的引用关系,并在适当的时候回收无用的对象。开发者可以通过将对象的引用置为 null 来显式地解除对对象的引用,以帮助垃圾回收器更早地回收对象。
在浏览器环境中,垃圾回收器通常使用标记- 清除算法来判断对象是否可回收。当一个对象不再可达时,即没有任何引用指向该对象,垃圾回收器会将其标记为可回收,并在垃圾回收的过程中将其释放。一些现代的浏览器还使用了更高级的垃圾回收算法,如分代回收和增量标记等,以提高垃圾回收的效率和性能。
总结来说,JavaScript 对象的生命周期包括创建、使用和回收三个阶段。开发者无需显式地管理对象的内存,而是通过使用对象和及时解除对象的引用来帮助垃圾回收器自动回收不再使用的对象。
93 我现在有一个canvas,上面随机布着一些黑块,请实现方法,计算canvas上有多少个黑块
要计算 canvas 上有多少个黑块,需要遍历 canvas 上的每个像素,并检查该像素的颜色是否为黑色。以下是一种实现方法:
function countBlackBlocks(canvas) {
const context = canvas.getContext('2d');
const imageData = context.getImageData(0, 0, canvas.width, canvas.height);
const pixels = imageData.data;
let blackCount = 0;
for (let i = 0; i < pixels.length; i += 4) {
// 获取像素的 RGB 颜色值
const red = pixels[i];
const green = pixels[i + 1];
const blue = pixels[i + 2];
// 判断颜色是否为黑色
if (red === 0 && green === 0 && blue === 0) {
blackCount++;
}
}
return blackCount;
}
使用该方法,传入 canvas 元素作为参数,即可计算 canvas 上有多少个黑块。该方法通过获取 canvas 上的像素数据,遍历每个像素并判断其颜色是否为黑色(RGB 值为 [0, 0, 0]),累计黑色像素的数量,并最后返回计数结果。
请注意,为了避免跨域问题,确保 canvas 的源与脚本执行的域相同,或者将 canvas 的图片源设为与脚本执行的域相同。另外,如果 canvas 的大小较大,遍历像素的操作可能会比较耗时,可能会影响性能。因此,在处理较大的 canvas 时,需要注意性能优化。
94 现在要你完成一个Dialog组件,说说你设计的思路?它应该有什么功能?
基于上述需求,以下是设计思路和Vue实现示例:
设计思路:
- 创建一个Dialog组件,它是一个可控的组件,接收
visible、onOk和onCancel等属性。 - 使用
v-if或者v-show来控制Dialog组件的显示与隐藏。 - 在组件内部,使用插槽(slot)来允许自定义头部和底部内容。
- 在Dialog组件的模板中,设置一个蒙层(mask),用于遮盖底层内容。点击蒙层时触发
onCancel事件关闭Dialog。 - 在Dialog组件的内容区域,设置一个滚动条容器,当内容超出容器高度时显示滚动条。
- 根据需要,可以在组件外部指定渲染位置、设置外层样式等。
Vue实现示例:
<template>
<div v-if="visible" class="dialog-container">
<div class="dialog-mask" @click="onCancel"></div>
<div class="dialog-content">
<div class="dialog-header">
<slot name="header">
<h2>Default Header</h2>
</slot>
</div>
<div class="dialog-body">
<slot></slot>
</div>
<div class="dialog-footer">
<slot name="footer">
<button @click="onOk">Confirm</button>
<button @click="onCancel">Cancel</button>
</slot>
</div>
</div>
</div>
</template>
<script>
export default {
props: {
visible: {
type: Boolean,
default: false
},
onOk: {
type: Function,
default: () => {}
},
onCancel: {
type: Function,
default: () => {}
}
},
watch: {
visible(newValue) {
if (newValue) {
document.body.style.overflow = 'hidden';
} else {
document.body.style.overflow = '';
}
}
},
methods: {
onOk() {
this.onOk();
},
onCancel() {
this.onCancel();
}
}
};
</script>
<style>
.dialog-container {
position: fixed;
top: 0;
left: 0;
right: 0;
bottom: 0;
display: flex;
justify-content: center;
align-items: center;
}
.dialog-mask {
position: fixed;
top: 0;
left: 0;
right: 0;
bottom: 0;
background-color: rgba(0, 0, 0, 0.5);
}
.dialog-content {
background-color: white;
width: 400px;
border-radius: 4px;
overflow: hidden;
}
.dialog-header {
padding: 16px;
border-bottom: 1px solid #ccc;
}
.dialog-body {
padding: 16px;
max-height: 400px;
overflow-y: auto;
}
.dialog-footer {
padding: 16px;
border-top: 1px solid #ccc;
text-align: right;
}
.dialog-footer button {
margin-left: 8px;
}
</style>
在使用示例中,我们可以在父组件中通过v-model指令来控制visible属性的值,从而控制Dialog组件的显示和隐藏。同时,可以通过@ok和@cancel事件监听来处理确定和取消按钮的点击事件。
<template>
<div>
<button @click="showDialog">Show Dialog</button>
<Dialog v-model="dialogVisible" @ok="handleOk" @cancel="handleCancel">
<template #header>
<h2>Custom Header</h2>
</template>
<p>This is the dialog content.</p>
<template #footer>
<button @click="handleCustomAction">Custom Action</button>
</template>
</Dialog>
</div>
</template>
<script>
import Dialog from './Dialog';
export default {
components: {
Dialog
},
data() {
return {
dialogVisible: false
};
},
methods: {
showDialog() {
this.dialogVisible = true;
},
handleOk() {
// Handle ok button click
console.log('Ok button clicked');
this.dialogVisible = false;
},
handleCancel() {
// Handle cancel button click
console.log('Cancel button clicked');
this.dialogVisible = false;
},
handleCustomAction() {
// Handle custom action button click
console.log('Custom action button clicked');
}
}
};
</script>
注意,在使用示例中,我们引入了自定义的Dialog组件,并在父组件中进行注册。然后使用v-model绑定dialogVisible属性来控制Dialog组件的显示和隐藏。通过监听@ok和@cancel事件来处理确定和取消按钮的点击事件,并在方法中进行相应的处理逻辑。
这样,当点击"Show Dialog"按钮时,Dialog组件将会显示出来,并且可以根据需要自定义头部、内容和底部按钮,同时可以处理确定和取消按钮的点击事件。
React Hooks实现
下面是使用React Hooks实现的Dialog组件示例:
import React, { useState } from 'react';
const Dialog = ({ visible, onCancel, onOk, children }) => {
const [dialogVisible, setDialogVisible] = useState(visible);
const handleCancel = () => {
setDialogVisible(false);
onCancel && onCancel();
};
const handleOk = () => {
setDialogVisible(false);
onOk && onOk();
};
return (
<>
{dialogVisible && (
<div className="dialog-wrapper">
<div className="dialog-mask" onClick={handleCancel}></div>
<div className="dialog-content">
<div className="dialog-header">
<h2>Dialog Header</h2>
</div>
<div className="dialog-body">{children}</div>
<div className="dialog-footer">
<button onClick={handleOk}>OK</button>
<button onClick={handleCancel}>Cancel</button>
</div>
</div>
</div>
)}
</>
);
};
export default Dialog;
在这个示例中,我们使用了useState来定义一个dialogVisible状态,来控制Dialog组件的显示和隐藏。当visible属性发生变化时,通过setDialogVisible方法来更新dialogVisible状态。
在handleCancel和handleOk方法中,我们调用setDialogVisible(false)来隐藏Dialog组件,并触发相应的onCancel和onOk回调函数。
在返回的JSX中,我们根据dialogVisible状态来判断是否渲染Dialog组件。当dialogVisible为true时,渲染Dialog组件的内容,包括遮罩层、头部、内容和底部按钮。点击遮罩层时,调用handleCancel方法,关闭Dialog。
使用这个Dialog组件时,可以通过传递visible、onCancel和onOk属性来控制显示和隐藏,以及处理取消和确定按钮的点击事件。
import React, { useState } from 'react';
import Dialog from './Dialog';
const App = () => {
const [dialogVisible, setDialogVisible] = useState(false);
const showDialog = () => {
setDialogVisible(true);
};
const handleOk = () => {
console.log('OK button clicked');
setDialogVisible(false);
};
const handleCancel = () => {
console.log('Cancel button clicked');
setDialogVisible(false);
};
return (
<div>
<button onClick={showDialog}>Show Dialog</button>
<Dialog visible={dialogVisible} onCancel={handleCancel} onOk={handleOk}>
<p>This is the dialog content.</p>
</Dialog>
</div>
);
};
export default App;
在这个示例中,我们在父组件中使用useState定义了一个dialogVisible状态,并提供了showDialog、handleOk和handleCancel方法来控制Dialog组件的显示和隐藏,以及处理确定和取消按钮的点击事件。
当点击"Show Dialog"按钮时,Dialog组件将会显示出来,并且可以根据需要传递内容,并处理确定和取消按钮的点击事件。
95 ajax、axios、fetch区别
总结一下ajax、axios和fetch的区别:
- ajax是一种技术统称,基于原生的XHR开发,已经有了fetch的替代方案。
- fetch是一个原生的API,用于进行网络请求,支持Promise API,但在某些方面功能较为简单,需要进行封装来处理错误、超时等情况。
- axios是一个第三方库,可以用于浏览器和Node.js环境中发出HTTP请求,支持Promise API,提供了更多的功能和选项,如拦截请求和响应、转换数据、取消请求等。
下面是它们的一些主要区别和特点:
- 代码简洁性 :fetch和axios相比,ajax的代码较为冗长,需要手动配置各项参数;fetch和axios使用更简洁,支持链式调用和配置对象参数。
- 浏览器兼容性 :fetch是基于原生的Fetch API,较新的API,不支持低版本的浏览器,需要进行兼容性处理;ajax和axios对各种浏览器有较好的兼容性。
- 功能丰富性 :axios提供了更多的功能和选项,如拦截请求和响应、转换数据、取消请求等,而fetch较为简单,需要进行封装来实现这些功能。
- 错误处理 :axios和fetch支持Promise API,可以使用catch方法捕获错误;ajax需要通过error回调函数来处理错误。
- 请求取消 :axios和fetch支持请求的取消操作,可以提前终止请求;ajax没有原生的取消请求的方法。
- 默认带cookie :axios和ajax默认会自动携带请求的cookie信息,而fetch默认不会携带,需要手动配置。
- 请求进度监测 :axios和ajax支持原生监测请求的进度,如上传和下载的进度;fetch没有原生的请求进度监测方法。
jQuery ajax
$.ajax({
type: 'POST',
url: url,
data: data,
dataType: dataType,
success: function () {},
error: function () {}
});
优缺点:
- 本身是针对
MVC的编程,不符合现在前端MVVM的浪潮 - 基于原生的
XHR开发,XHR本身的架构不清晰,已经有了fetch的替代方案 JQuery整个项目太大,单纯使用ajax却要引入整个JQuery非常的不合理(采取个性化打包的方案又不能享受CDN服务)
axios
axios({
method: 'post',
url: '/user/12345',
data: {
firstName: 'Fred',
lastName: 'Flintstone'
}
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});
优缺点:
- 从浏览器中创建
XMLHttpRequest - 从
node.js发出http请求 - 支持
Promise API - 拦截请求和响应
- 转换请求和响应数据
- 取消请求
- 自动转换
JSON数据 - 客户端支持防止
CSRF/XSRF
fetch
try {
let response = await fetch(url);
let data = response.json();
console.log(data);
} catch(e) {
console.log("Oops, error", e);
}
优缺点:
fetcht只对网络请求报错,对400,500都当做成功的请求,需要封装去处理fetch默认不会带cookie,需要添加配置项fetch不支持abort,不支持超时控制,使用setTimeout及Promise.reject的实现的超时控制并不能阻止请求过程继续在后台运行,造成了量的浪费fetch没有办法原生监测请求的进度,而XHR可以
96 JavaScript的组成
JavaScript由三部分组成:
- ECMAScript(核心) :ECMAScript是JavaScript的基础,定义了语言的语法、类型、语句、关键字等。它规定了JavaScript的基本语法、数据类型、函数、运算符、控制流等核心特性,并提供了对数组、对象、字符串、正则表达式等的操作方法和功能。ECMAScript的版本以ES6(ES2015)为基准,随着时间的推移,新版本的ECMAScript引入了更多的语言特性和功能。
- DOM(文档对象模型) :DOM是一种表示和操作HTML、XML文档的接口。它定义了文档的结构、属性和方法,允许开发者通过JavaScript来访问和修改网页的内容、结构和样式。DOM将文档表示为一个树形结构,其中每个节点代表文档中的一个元素、属性、文本等。开发者可以使用DOM提供的API对这些节点进行增删改查操作,实现动态更新和交互效果。
- BOM(浏览器对象模型) :BOM是一种提供了与浏览器窗口进行交互的接口。它提供了访问浏览器窗口、处理窗口尺寸、导航历史、处理Cookie、发送HTTP请求等功能。BOM中的对象包括
window、navigator、location、history、screen等,开发者可以使用这些对象来控制浏览器的行为和获取相关信息。
这三部分共同构成了JavaScript的整体,使其成为一种强大的编程语言,能够在网页中实现丰富的交互和动态效果。
97 检测浏览器版本有哪些方式?
检测浏览器版本可以使用以下几种方式:
- 使用
navigator.userAgent:通过检查navigator.userAgent属性,可以获取包含了浏览器相关信息的用户代理字符串。可以根据用户代理字符串中的特定关键字或标识符来确定浏览器的类型和版本。例如,使用UA.toLowerCase().indexOf('chrome')可以检测是否为Chrome浏览器。 - 使用
window对象的成员:根据浏览器的不同,window对象的成员可能会有所差异。可以通过检查特定的window对象成员是否存在来确定浏览器的类型和版本。例如,通过检查'ActiveXObject' in window可以判断是否为IE浏览器。 - 使用现成的JavaScript库或框架 :有一些专门用于检测浏览器类型和版本的JavaScript库或框架,如
Bowser、Platform.js等。这些库提供了简单易用的API,可以方便地获取浏览器信息。
需要注意的是,检测浏览器版本可能会受到用户代理字符串的伪造或篡改,因此并不是一种绝对可靠的方法。在实际应用中,最好结合多种方式进行浏览器版本的检测,以增加准确性和可靠性。
98 介绍JS有哪些内置对象
当提到JavaScript的内置对象时,以下是一些常见的和全面的内置对象的列表:
- 基本数据类型封装对象 :
Object:用于创建对象的基类。Array:用于创建和操作数组的对象。Boolean:表示布尔值的对象,包括true和false。Number:表示数字的对象,可以进行数值操作和转换。String:表示字符串的对象,提供了字符串操作和处理的方法。BigInt:表示任意精度整数的对象,用于处理超出Number范围的整数。
- 功能类对象 :
Function:用于定义和调用函数的对象。Date:用于处理日期和时间的对象。RegExp:用于进行正则表达式匹配和操作的对象。Error:表示错误的对象,用于抛出和处理异常。Math:提供了各种数学运算的方法和常量。
- 集合类对象 :
Set:表示一组唯一值的集合。Map:提供了键值对的数据结构,可以使用任何数据类型作为键。WeakSet:类似于Set,但只能存储对象引用,并且不会阻止垃圾回收。WeakMap:类似于Map,但只能使用对象作为键,并且不会阻止垃圾回收。
- 其他对象 :
Symbol:表示唯一标识符的数据类型,用于创建对象的属性键。Promise:用于处理异步操作的对象,提供了更好的处理异步任务的方式。Proxy:用于创建对象的代理,可以拦截并自定义对象的操作。Reflect:提供了一组静态方法,用于操作对象的属性和方法。JSON:用于解析和序列化JSON数据的对象。
这只是一些常见的内置对象,JavaScript还有许多其他内置对象和全局函数,用于处理各种类型的数据和操作。根据不同的需求和场景,可以选择适合的内置对象来使用。
99 说几条写JavaScript的基本规范
以下是一些常见的JavaScript编码规范:
- 使用一致的缩进:推荐使用四个空格进行缩进,而不是制表符。
- 使用一致的代码风格:在代码中使用一致的花括号(大括号)风格,可以是"K&R"风格(花括号放在行尾)或"Allman"风格(花括号独占一行)。
- 使用分号结束语句:在每条语句的末尾使用分号结束,这有助于避免意外的错误。
- 声明变量和函数:在使用之前,先声明变量和函数,避免隐式的全局变量。
- 命名约定:使用有意义且符合约定的变量和函数命名,采用驼峰命名法,首字母小写,构造函数使用大写字母开头,常量全大写。
- 使用严格模式:在脚本或函数的开头使用严格模式('use strict'),可以帮助捕获潜在的错误并使代码更加安全。
- 编写清晰的注释:使用注释来解释代码的用途、思路或重要细节,有助于他人理解代码。
- 格式化对象和数组:使用花括号
{}来声明对象,使用方括号[]来声明数组,并且按照一定的格式排列其中的元素,提高可读性。 - 使用单引号或双引号:可以选择使用单引号或双引号来表示字符串,但要保持一致性。
- 避免使用全局变量:尽量避免使用全局变量,使用模块化的方式组织代码,减少命名冲突和意外的副作用。
这些规范有助于提高代码的可读性、可维护性和一致性,使团队协作更加顺畅,并降低代码出错的风险。在编写JavaScript代码时,遵循一致的编码规范是一个良好的实践。
100 如何编写高性能的JavaScript
以下是一些编写高性能JavaScript的技巧:
- 使用严格模式:在JavaScript代码中使用严格模式,可以帮助检测潜在的错误,并提高代码性能。
- 将脚本放在底部:将JavaScript脚本放在HTML页面的底部,这样可以避免阻塞页面的渲染,提高页面加载速度。
- 打包和压缩代码:将JavaScript脚本进行打包和压缩,减少网络请求和文件大小,提高加载速度。
- 非阻塞下载:使用异步加载的方式下载JavaScript脚本,通过将脚本放在
<script>标签的async或defer属性中,避免阻塞页面的渲染。 - 减少全局变量的使用:尽量避免过多使用全局变量,使用局部变量来保存数据,减少作用域链的查找时间。
- 优化循环和迭代:在循环和迭代过程中,尽量减少重复的计算和操作,将需要重复使用的值存储在局部变量中,避免重复访问对象成员。
- 缓存DOM访问:在访问DOM节点时,尽量将访问结果缓存起来,避免重复查询DOM树,提高代码执行效率。
- 避免使用eval()和Function()构造器:这些方法会动态编译和执行代码,对性能有一定的影响,尽量避免使用它们。
- 使用直接量创建对象和数组:在创建对象和数组时,尽量使用直接量的方式,避免使用构造函数,这样可以减少额外的函数调用和内存分配。
- 最小化重绘和回流:重绘(repaint)和回流(reflow)是页面渲染的过程,它们会消耗大量的计算资源,尽量避免频繁的重绘和回流,可以通过合并操作、使用CSS动画等方式来优化。 当涉及到编写高性能的JavaScript代码时,还有一些其他的技巧可以考虑:
- 减少对象成员嵌套:在访问对象的成员时,尽量减少多层嵌套,这样可以提高访问速度。例如,将
obj1.obj2.prop改为obj1Prop。 - 避免频繁的字符串操作:字符串操作比较耗费性能,尤其是在循环中频繁拼接字符串。可以使用数组或模板字符串来优化字符串操作。
- 使用事件委托:对于需要监听多个子元素事件的情况,可以将事件监听器添加到它们的父元素上,通过事件冒泡机制来处理事件。这样可以减少事件监听器的数量,提高性能。
- 避免频繁的重绘:如果需要对DOM进行多次修改,最好将这些修改操作放在一起,而不是分散在多个地方,这样可以减少重绘次数。
- 使用局部作用域:将代码封装在函数或模块中,利用局部作用域来限制变量的作用范围,避免命名冲突和全局变量污染。
- 使用合适的数据结构和算法:在处理大量数据或复杂逻辑时,选择合适的数据结构和算法可以提高代码的效率。了解不同数据结构和算法的特点,选择最佳的方案。
- 节流和防抖:对于一些频繁触发的事件(如滚动、调整窗口大小等),可以使用节流和防抖的技术来限制事件的触发频率,减少不必要的计算和操作。
- 使用性能分析工具:利用浏览器提供的性能分析工具(如Chrome的开发者工具)来检测和分析代码的性能瓶颈,找到需要优化的地方。
- 避免使用过时的方法和特性:某些方法和特性可能已经过时或存在性能问题,尽量避免使用它们,使用最新的标准和API来编写代码。
- 定期进行代码优化和重构:不断优化和重构代码,去除冗余和低效的部分,使代码保持简洁、高效和易于维护。
综合使用这些技巧,可以显著提高JavaScript代码的性能和执行效率。但需要注意的是,优化代码时应该根据具体情况进行评估和测试,避免过度优化导致代码可读性和可维护性的降低。
101 描述浏览器的渲染过程,DOM树和渲染树的区别
浏览器的渲染过程:
- 解析 HTML 构建 DOM(文档对象模型)树:浏览器将接收到的 HTML 文档解析成一个树状结构,该结构被称为 DOM 树。DOM 树表示了 HTML 文档的结构和内容。
- 解析 CSS 构建 CSSOM(CSS 对象模型)树:浏览器将接收到的 CSS 文件解析成一个树状结构,该结构被称为 CSSOM 树。CSSOM 树表示了 CSS 样式规则的层级和规则。
- 合并 DOM 树和 CSSOM 树生成渲染树(Render Tree):浏览器将 DOM 树和 CSSOM 树合并,生成一个渲染树(Render Tree)。渲染树只包含需要显示在页面上的节点,隐藏的节点(如 head)和不可见的节点(如 display: none)不包含在渲染树中。
- 布局(Layout):渲染树中的每个节点都有对应的布局信息,浏览器根据这些布局信息计算节点在屏幕中的位置和大小,这个过程称为布局或回流(reflow)。
- 绘制(Painting):浏览器根据渲染树的布局信息和样式信息,将节点绘制到屏幕上,这个过程称为绘制或重绘(repaint)。
DOM 树和渲染树的区别:
- DOM 树(文档对象模型树)是由 HTML 文档解析而来,它反映了文档的结构和内容,包括 HTML 标签、文本节点和注释等。DOM 树中的每个节点都有其对应的 CSS 样式规则。
- 渲染树(Render Tree)是由 DOM 树和 CSSOM 树合并而成,它是用于显示在浏览器中的树状结构。渲染树只包含需要显示在页面上的节点,不包含隐藏的节点和不可见的节点。渲染树中的每个节点都有其对应的布局信息和样式信息,用于计算节点在屏幕中的位置和大小,并将节点绘制到屏幕上。
总结:DOM 树表示了 HTML 文档的结构和内容,而渲染树是为了将文档在浏览器中显示而构建的树结构。渲染树只包含需要显示的节点,并且每个节点都有对应的布局和样式信息,用于计算和绘制节点在屏幕上的位置和外观。
102 script 的位置是否会影响首屏显示时间
script的位置对首屏显示时间有影响。虽然浏览器在解析 HTML 生成 DOM 过程中,js文件的下载是并行的,不需要 DOM 处理到script节点,但是脚本的执行会阻塞页面的解析和渲染。- 当浏览器遇到
script标签时,会暂停解析 HTML,开始下载并执行脚本。只有脚本执行完毕后,浏览器才会继续解析和渲染页面。 - 如果
script标签放在<head>标签中,那么脚本的下载和执行会先于页面的渲染,这样会延迟首屏显示的开始时间。 - 为了提高首屏显示时间,一般建议将
script标签放在<body>标签底部,在大部分内容都已经显示出来后再加载和执行脚本,这样可以让页面尽快呈现给用户,提升用户体验。 - 另外,可以使用异步加载的方式(如将
script标签添加async属性)或延迟加载的方式(如将script标签添加defer属性),来减少脚本对页面加载的阻塞影响。这样可以在不阻塞页面渲染的情况下加载和执行脚本,加快首屏显示的完成时间。
103 介绍 DOM 的发展
DOM:文档对象模型(Document Object Model),定义了访问HTML和XML文档的标准,与编程语言及平台无关DOM Level 0:提供了查询和操作Web文档的内容API。未形成标准,实现混乱。如:document.forms['login']DOM Level 1:W3C提出标准化的DOM,简化了对文档中任意部分的访问和操作。如:JavaScript中的Document对象DOM Level 2:原来DOM基础上扩充了鼠标事件等细分模块,增加了对CSS的支持。如:getComputedStyle(elem, pseudo)DOM Level 3:增加了XPath模块和加载与保存(Load and Save)模块。如:XPathEvaluatorDOM Level 4:继续扩展了 DOM 标准,引入了一些新的接口和功能,如MutationObserver用于监听 DOM 变动、Shadow DOM用于创建独立的 DOM 子树等
104 介绍DOM0,DOM2,DOM3事件处理方式区别
- DOM0级事件处理方式:通过直接给事件属性赋值的方式进行事件处理,例如
element.onclick = func;。这种方式只能为同一个事件属性赋一个处理函数,且无法进行事件捕获阶段的处理。取消事件处理需要将事件属性赋值为nullbtn.onclick = func;btn.onclick = null;
- DOM2级事件处理方式:引入了
addEventListener和removeEventListener方法来注册和移除事件处理函数。通过使用该方式,可以为同一个事件属性添加多个处理函数,且可以在事件的捕获阶段或冒泡阶段进行处理。使用addEventListener注册事件处理函数,使用removeEventListener移除事件处理函数btn.addEventListener('click', func, false);btn.removeEventListener('click', func, false);btn.attachEvent("onclick", func);btn.detachEvent("onclick", func);
- DOM3级事件处理方式:引入了新的事件类型和接口,提供更多的事件处理选项。可以使用自定义的事件类型,并通过
eventUtil等自定义的工具对象来添加和移除事件处理函数。DOM3级事件处理方式还引入了事件的命名空间概念,允许对特定命名空间的事件进行处理eventUtil.addListener(input, "textInput", func);eventUtil是自定义对象,textInput是DOM3级事件
在事件处理过程中,事件会经历捕获阶段、目标阶段和冒泡阶段。捕获阶段从文档根节点开始,向下传递到触发事件的目标元素,然后进入目标阶段,最后冒泡阶段从目标元素向上冒泡到文档根节点。DOM2和DOM3级事件处理方式都支持捕获和冒泡阶段的处理,可以通过第三个参数 useCapture 来控制事件是在捕获阶段还是冒泡阶段触发。
需要注意的是,DOM2和DOM3级事件处理方式的兼容性较好,而DOM0级事件处理方式在现代的开发中很少使用,推荐使用DOM2级或DOM3级事件处理方式。